工程师法典是一份免费的、每周发布的刊物,提炼现实世界的软件工程。
阅读有关 Reddit 或 Hacker News 的讨论。
2012年1月,Pinterest的月独立用户数达到1170万,仅有6名工程师。
成立于2010年3月,当时是最快突破每月1000万用户的公司。
Pinterest 是一个以图片为主的社交网络,用户可以将图片保存或“固定”到他们的画板上。
当我在下面提到“用户”时,指的是“月活跃用户”(MAU)。
- 使用已知、经过验证的技术。 Pinterest 当时对新技术的尝试导致了数据损坏等问题。
- 保持简单。(一个反复出现的主题!)
- 不要过于创造性。 团队采用了一种架构,可以添加更多相同的节点以进行扩展。
- 限制你的选择。
- 分片数据库 > 集群。 减少了节点间的数据传输,这是一件好事。
- 玩得开心! 新工程师在第一周就能贡献代码。
Pinterest于2010年3月推出,当时只有一个小型MySQL数据库、一个小型Web服务器和一名工程师(以及两位联合创始人)
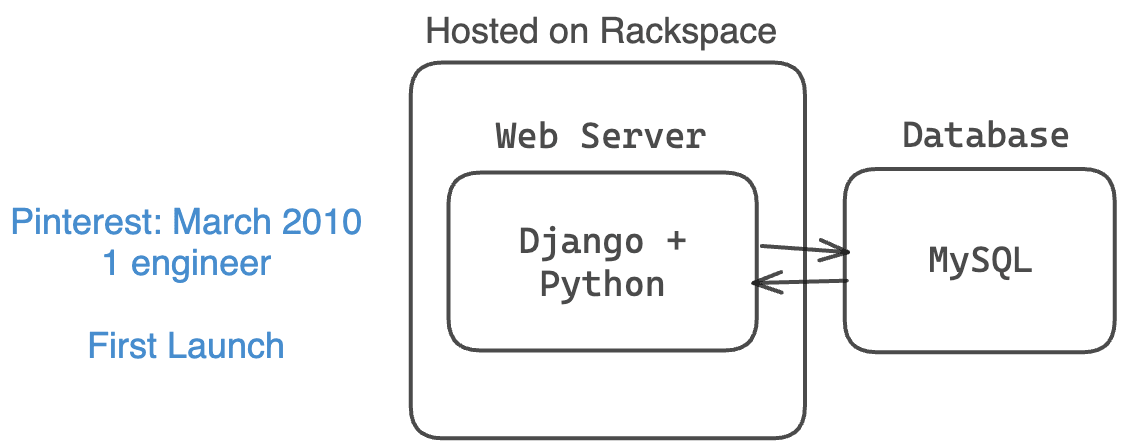
2011年1月,Pinterest的架构经过九个月的演变,能够处理更多用户。他们仍然只接受邀请注册,并且有2名工程师。
他们有:
- 一个基本的 Web 服务器堆栈(Amazon EC2、S3 和 CloudFront)
- Django(Python)用于后端
- 4 个 Web 服务器以实现冗余
- NGINX 作为反向代理和负载均衡器。
- 目前有 1 个 MySQL 数据库 + 1 个只读的辅助数据库
- MongoDB 用于计数器
- 1 个任务队列和 2 个任务处理器用于异步任务

从2011年1月到2011年10月,Pinterest增长非常迅速,用户数量每一个半月翻一番。
他们在2011年3月推出的iPhone应用是推动这种增长的因素之一。
当事物增长迅速时,技术出现故障的频率往往超出你的预期。
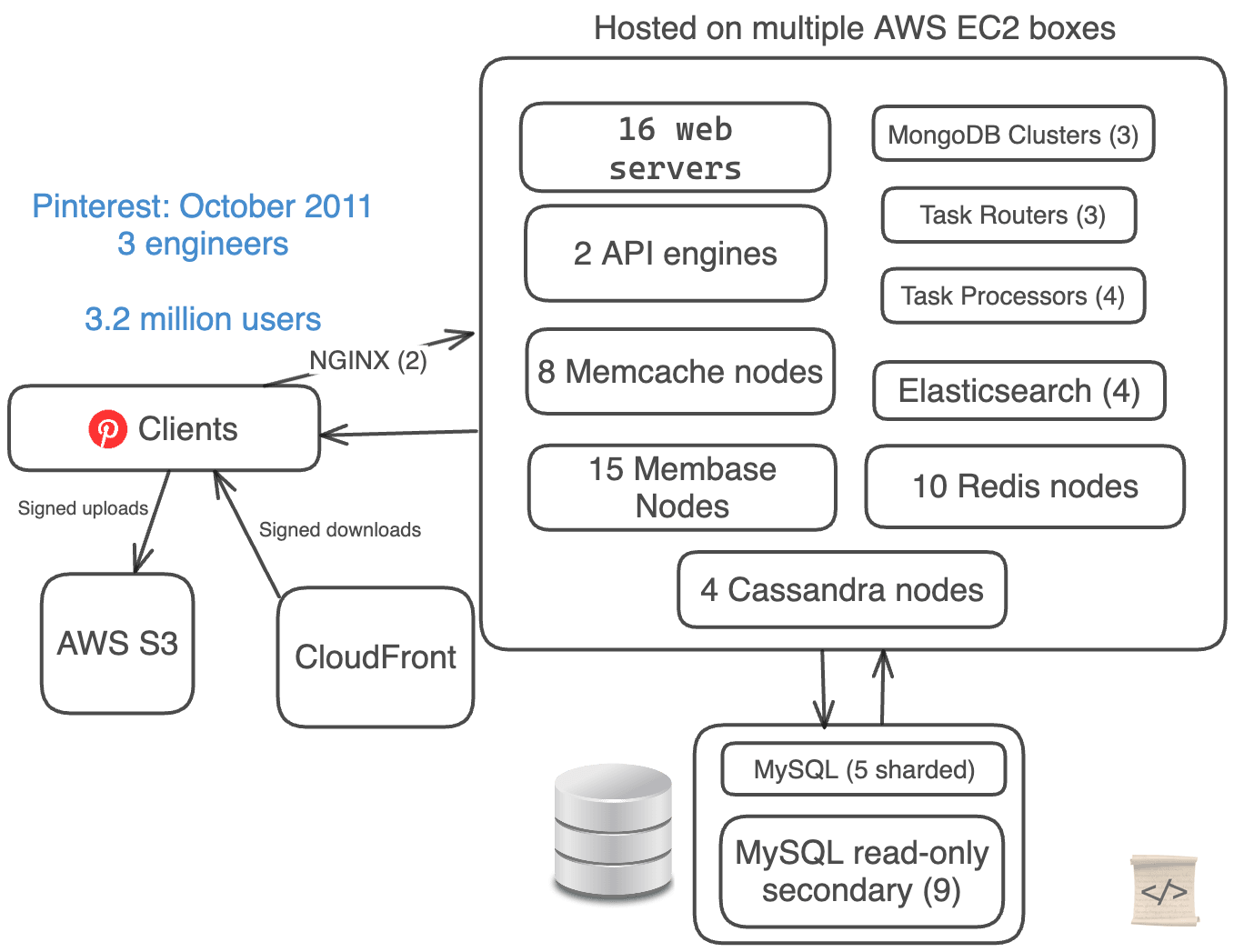
Pinterest犯了一个错误:他们过分复杂化了他们的架构。
他们只有3名工程师,但使用了5种不同的数据库技术来处理数据。
他们都在手动分片他们的MySQL数据库,并使用Cassandra和Membase(现在是Couchbase)对数据进行集群化。
- Web 服务器堆栈(EC2 + S3 + CloudFront)
- 16 个 Web 服务器
- 2 个 API 引擎
- 2 个 NGINX 代理
- 5 个手动分片的 MySQL 数据库 + 9 个只读副本
- 4 个 Cassandra 节点
- 15 个 Membase 节点(3 个独立集群)
- 8 个 Memcache 节点
- 10 个 Redis 节点
- 3 个任务路由器 + 4 个任务处理器
- 4 个 Elastic Search 节点
- 3 个 Mongo 集群
数据库集群 是将多个数据库服务器连接在一起共同工作的过程。
从理论上讲,聚类自动扩展数据存储,提供高可用性,免费负载平衡,并且没有单点故障。
不幸的是,在实践中,聚类过于复杂,升级机制困难,并且存在一个重大的单点故障。
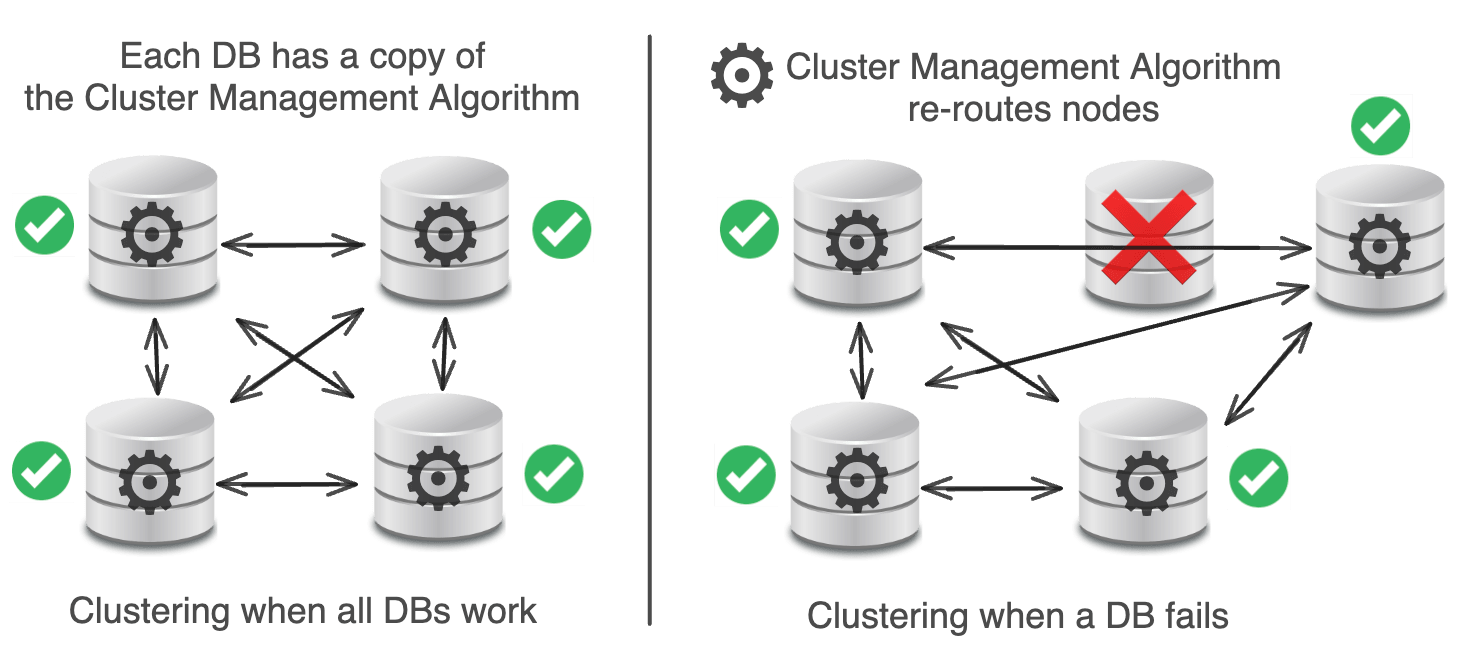
每个数据库都有一个集群管理算法,用于在数据库之间进行路由。
当数据库出现问题时,会添加一个新的数据库来替换它。
理论上,集群管理算法应该能很好地处理这个问题。
实际上,Pinterest的集群管理算法中存在一个错误,损坏了所有节点上的数据,破坏了数据再平衡,并造成了一些无法修复的问题。

Pinterest的解决方案?从系统中删除所有聚类技术(Cassandra,Membase)。全面采用MySQL + Memcached(更为成熟)。
MySQL 和 Memcached 是经过验证的技术。Facebook 使用这两种技术创建了世界上最大的 Memcached 系统,轻松处理了数十亿请求每秒的工作量。
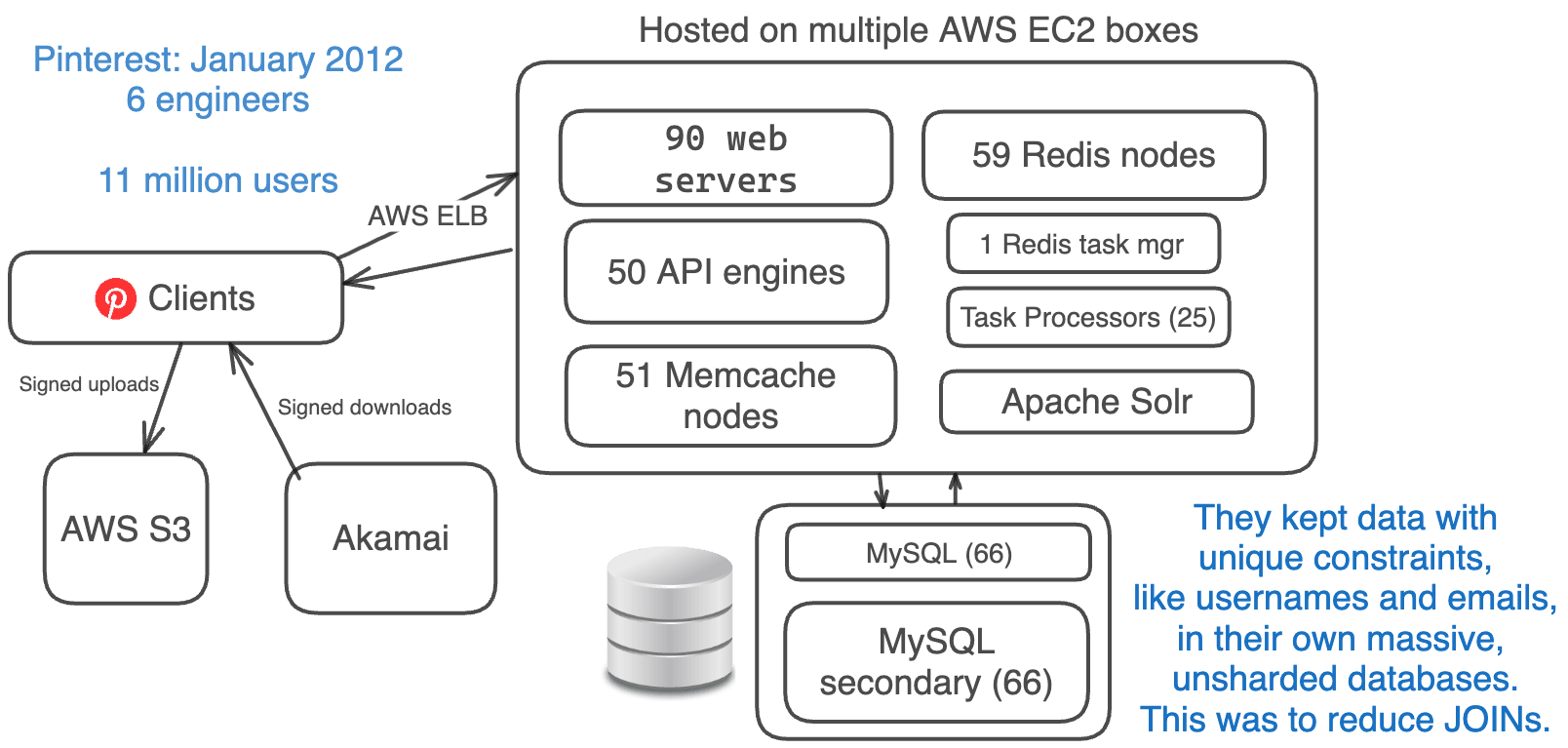
2012年1月,Pinterest的月活跃用户数约为1100万,每天的用户数在1200万至2100万之间。
Pinterest在这一点上花时间简化了他们的架构。
他们当时移除了 less-proven ideas,比如 clustering 和 Cassandra,并用 proven ones,比如 MySQL、Memcache 和 sharding 进行了替换。
他们的简化堆栈:
- Amazon EC2 + S3 + Akamai (替换 CloudFront)
- AWS ELB (弹性负载均衡)
- 90 Web 引擎 + 50 API 引擎 (使用 Flask)
- 66 个 MySQL 数据库 + 66 个从库
- 59 个 Redis 实例
- 51 个 Memcache 实例
- 1 个 Redis 任务管理器 + 25 个任务处理器
- 分片的 Apache Solr (替换 Elasticsearch)
- 移除了 Cassanda、Membase、Elasticsearch、MongoDB、NGINX
数据库分片 是将单个数据集分割成多个数据库的方法。
优势: 高可用性,负载均衡,简单的数据放置算法,易于分割数据库以增加容量,易于定位数据
当Pinterest首次对其数据库进行分片时,它们进行了功能冻结。在接下来的几个月里,它们逐步且手动地对数据库进行了分片:
团队从数据库层中移除了表连接和复杂查询。他们增加了大量的缓存。
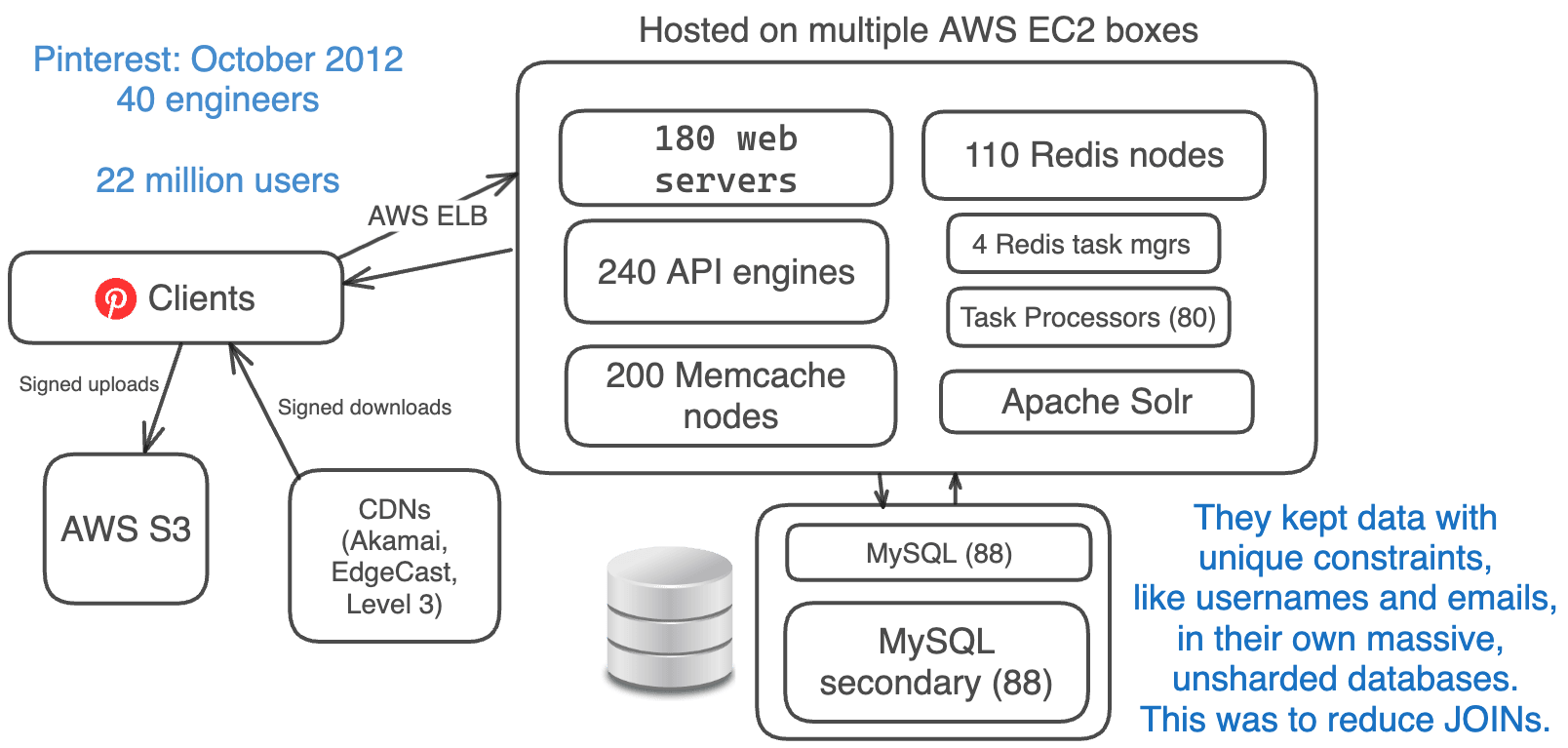
由于在不同数据库之间维护唯一约束需要额外的工作,他们将用户名和电子邮件等数据保存在一个庞大的、未分片的数据库中。
所有表都存在于它们的所有分片上。
由于他们有数十亿“引脚”,他们的数据库索引耗尽了内存。
他们会将数据库中最大的表格移到自己的数据库中。
然后,当数据库空间不足时,他们会进行分片。
2012年10月,Pinterest拥有约2200万月活跃用户,但他们的工程团队已经增加到40名工程师。
建筑物保持不变。他们只是增加了更多相同的系统。
- Amazon EC2 + S3 + CDNs (EdgeCast, Akamai, Level 3)
- 180 个 Web 服务器 + 240 个 API 引擎(使用 Flask)
- 88 个 MySQL 数据库 + 每个数据库有 88 个副本
- 110 个 Redis 实例
- 200 个 Memcache 实例
- 4 个 Redis 任务管理器 + 80 个任务处理器
- 分片 Apache Solr
他们开始从硬盘驱动器转向固态硬盘。
一个重要的教训是:有限、经过验证的选择是一件好事。
坚持使用 EC2 和 S3 意味着他们的配置选择有限,减少了烦恼,更简单。
然而,新实例可能在几秒钟内准备就绪。 这意味着他们可以在几分钟内添加 10 个 Memcache 实例。
SWE Quiz 是一个包含450多个软件工程和系统设计问题的汇编,涵盖数据库、身份验证、缓存等。
这些问题由来自 Google、Meta、Apple 等公司的工程师创建。
在面试中识别和弥补软件知识中的空白 + 通过“软件琐事”问题。
像 Instagram,Pinterest 有一个独特的 ID 结构,因为他们使用了分片数据库。
它们的 64 位 ID 看起来像:
分片 ID: 分片(16 位)
类型: 对象类型,如 pins(10 位)
本地 ID: 在表中的位置(38 位)
这些ID的查找结构是一个简单的Python字典。
它们有对象表和映射表。
对象表用于针、板、评论、用户等等。它们有一个本地ID映射到一个MySQL blob,就像JSON。
映射表用于对象之间的关系数据,比如将板块映射到用户或将点赞映射到一个图钉。 它们有一个完整的ID映射到一个完整的ID和一个时间戳。
所有查询都是为了效率而进行的主键(PK)或索引查找。它们消除了所有的连接操作。
本文基于Pinterest的扩展,Pinterest团队在2012年的演讲。