检索增强生成(RAG)是一个被滥用的术语。它承诺了很多,但在开发了RAG管道之后,很多人都在想为什么它的效果没有我们期望的那么好。
与大多数工具一样,RAG易于使用但难以精通。事实上,RAG并不仅仅是将文档放入向量数据库并在其上添加LLM。这种方法可能有效,但并非总是如此。
本电子书旨在告诉您,当开箱即用的 RAG 不起作用 时该怎么办。在本章中,我们将探讨对于次优 RAG 流程来说通常是最简单和最快实施的解决方案——我们将学习有关 重新排序器 的内容。
本章的视频配套内容。
召回 vs. 上下文窗口
在深入解决方案之前,让我们先谈谈问题。使用 RAG,我们正在对许多文本文档进行 语义搜索 — 这些文档可能是数万甚至数十亿份。
为了确保在大规模情况下快速搜索,我们通常使用向量搜索——也就是将文本转换为向量,将它们放入向量空间,并使用余弦相似度等相似度度量来比较它们与查询向量的接近程度。
为了使向量搜索起作用,我们需要向量。这些向量本质上是将一些文本的“含义”压缩成(通常为)768或1536维的向量。由于我们将这些信息压缩成单个向量,所以会有一些信息损失。
由于信息丢失,我们经常看到前三(例如)矢量搜索文档会错过相关信息。不幸的是,检索可能会返回在我们的 top_k 截断值以下的相关信息。
如果在较低位置的相关信息可以帮助我们的LLM制定更好的响应,我们该怎么办?最简单的方法是增加我们返回的文档数量(增加top_k),并将它们全部传递给LLM。
我们要衡量的指标是 召回率 — 意思是“我们检索到了多少相关文档”。召回率不考虑检索到的文档总数 — 所以我们可以通过返回 所有内容 来操纵指标,获得 完美 的召回率。
召回率@K=返回的相关文档数/数据集中的相关文档数召回率@K=\frac{#;of;relevant;docs;returned}{#;of;relevant;docs;in;dataset}
很遗憾,我们无法返回所有内容。LLM对我们可以传递的文本数量有限制,我们称之为上下文窗口。一些LLM具有巨大的上下文窗口,比如Anthropic的Claude,上下文窗口达到了100K个标记[1]。有了这个,我们可以容纳许多页的文本,因此我们可以返回许多文档(但不是全部),并且“填充”上下文窗口以提高召回率。
再次强调,不行。我们不能使用上下文填充,因为这会降低LLM的召回性能——请注意,这是LLM的召回性能,与我们迄今讨论的检索召回是不同的。
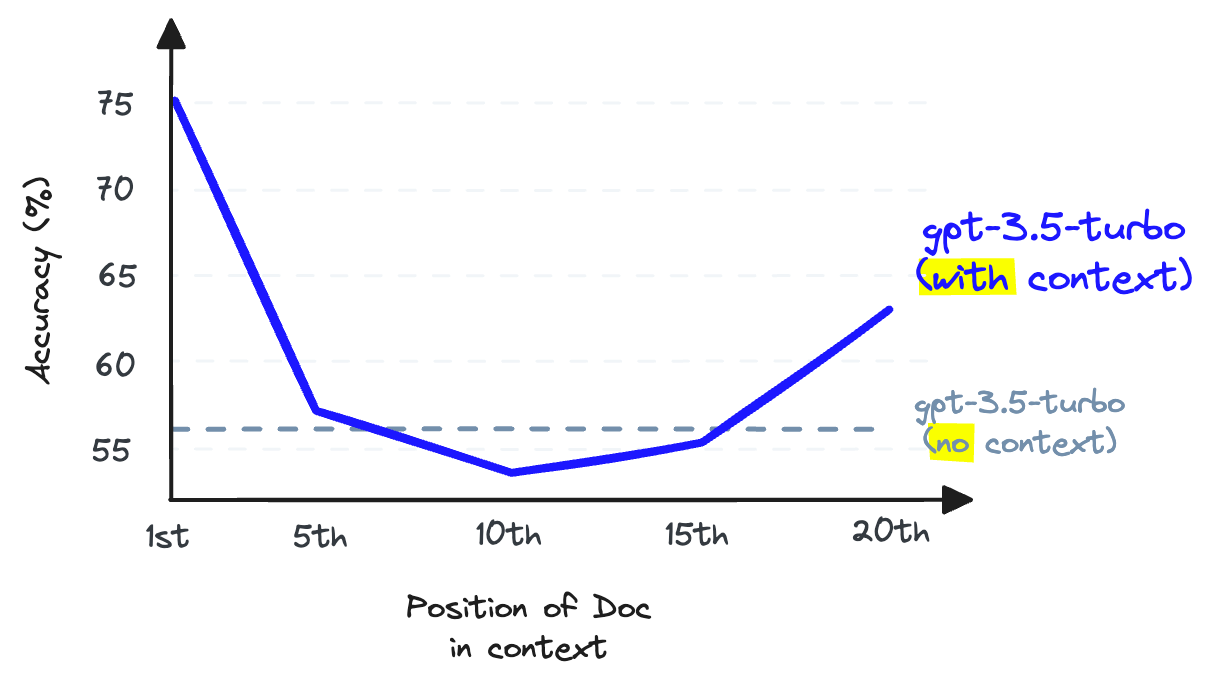
在上下文窗口的中间存储信息时,LLM 回忆该信息的能力变得比起初未提供该信息时更差 [2]。
LLM召回是指LLM从其上下文窗口中的文本中查找信息的能力。研究表明,随着我们在上下文窗口中放入更多的标记,LLM的召回能力会下降[2]。当我们填充上下文窗口时,LLM也不太可能遵循指令,因此上下文填充是一个不好的主意。
我们可以增加向量数据库返回的文档数量以提高检索召回率,但不能将这些传递给我们的LLM,否则会损害LLM的召回率。
解决这个问题的方法是通过检索大量文档来最大化检索召回率,然后通过 最小化 进入LLM的文档数量来最大化LLM召回率。为了做到这一点,我们重新排序检索到的文档,并只保留最相关的文档供LLM使用 — 为了做到这一点,我们使用 重新排序。
重新排序器的威力
一个重新排序模型,也被称为交叉编码器,是一种模型,给定查询和文档对,将输出相似度分数。我们使用这个分数来按照与我们的查询相关性重新排序文档。
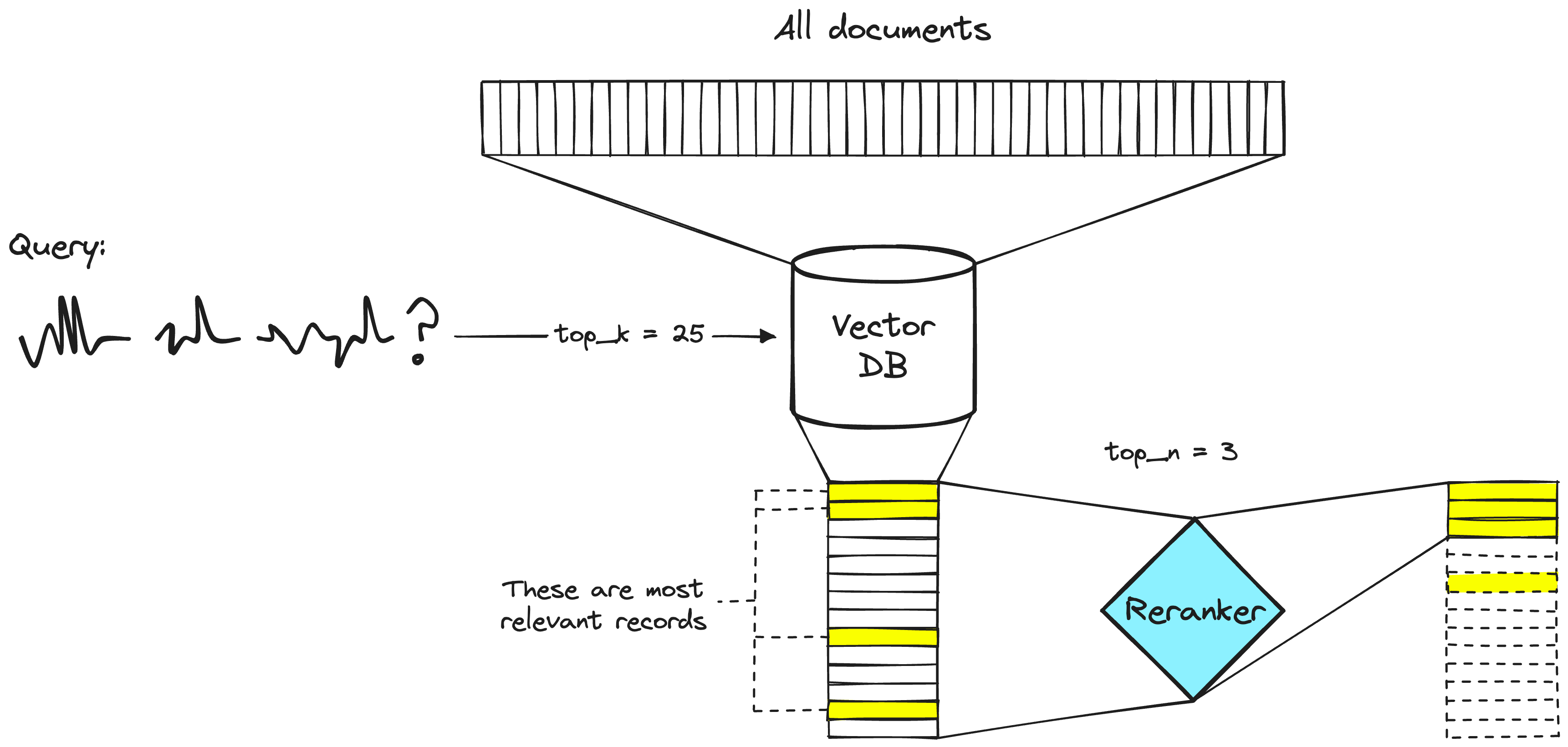
一个两阶段检索系统。向量数据库步骤通常包括双编码器或稀疏嵌入模型。
搜索工程师们在两阶段检索系统中长期以来一直使用重新排序器。在这些两阶段系统中,第一阶段模型(嵌入模型/检索器)从更大的数据集中检索一组相关文档。然后,第二阶段模型(重新排序器)用于重新排序第一阶段模型检索到的文档。
我们使用两个阶段是因为从大数据集中检索一小部分文档比重新对大量文档进行排名要快得多——我们很快会讨论为什么会这样——但总之,重新排名很慢,而检索器非常_快_。
为什么需要重新排名?
如果重新排序器慢得多,为什么还要使用它们呢?答案是重新排序器比嵌入模型更准确。
双编码器精度较低的直觉是,双编码器必须将文档的所有可能含义压缩成单个向量 — 这意味着我们丢失了信息。此外,双编码器在查询上没有上下文,因为在收到查询之前我们不知道查询内容(我们在用户查询之前创建嵌入)。
另一方面,重新排序器可以直接接收原始信息进行大型变换器计算,意味着信息损失更少。由于我们在用户查询时运行重新排序器,因此我们有额外的好处,即分析我们文档的含义与用户查询相关,而不是试图产生通用的、平均的含义。
重新排序器避免了双编码器的信息丢失,但它们会带来不同的惩罚——时间。
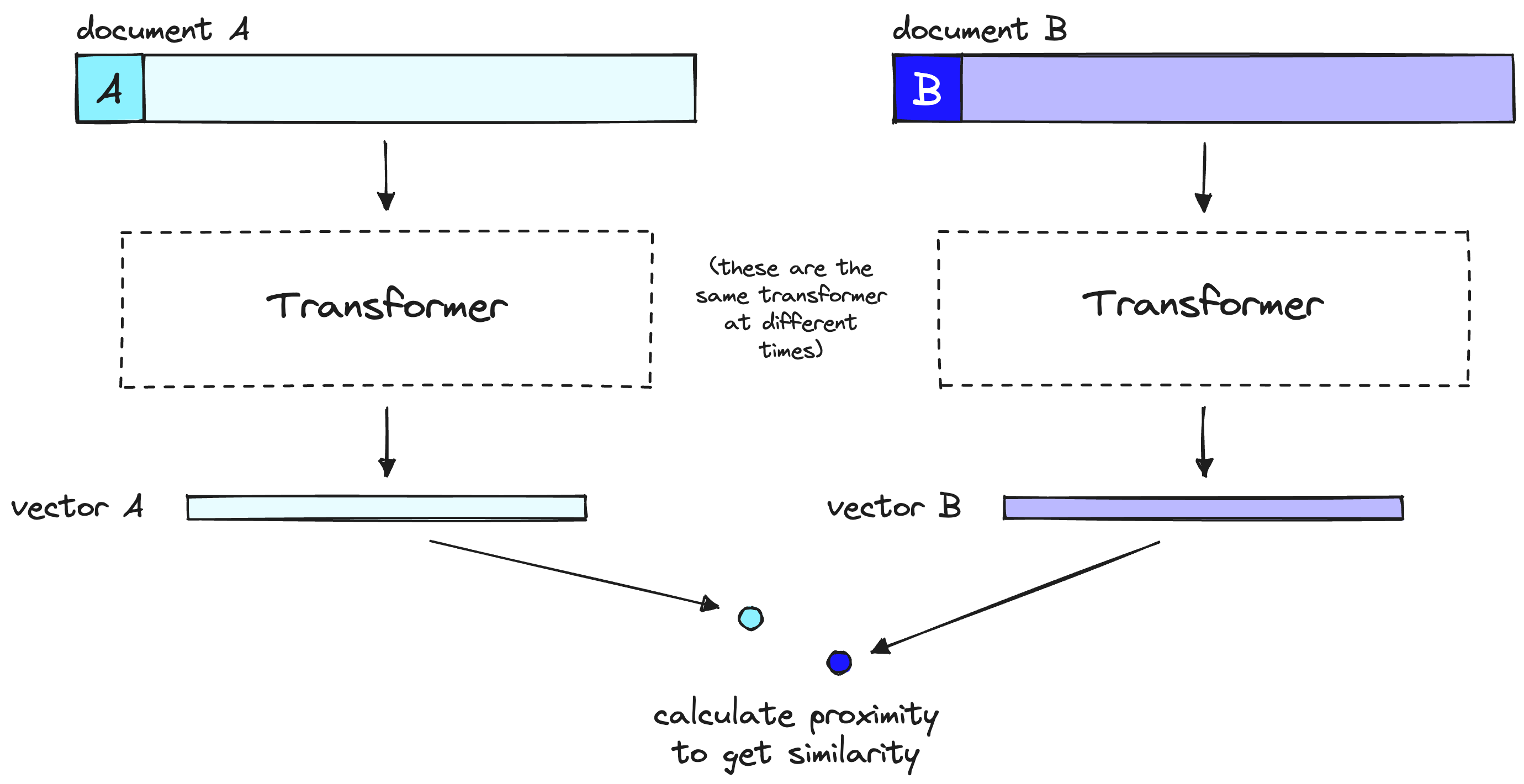
双编码器模型将文档或查询的含义压缩为单个向量。请注意,双编码器处理我们的查询的方式与处理文档的方式相同,但在用户查询时会有所不同。
当使用双编码器模型进行向量搜索时,我们将所有繁重的变换器计算前置到创建初始向量时——这意味着当用户查询我们的系统时,我们已经创建了向量,所以我们需要做的只是:
- 运行单个变换器计算生成查询向量。
- 使用余弦相似度(或其他轻量级度量)比较查询向量和文档向量。
使用重新排序器时,我们不会预先计算任何内容。相反,我们将查询和单个其他文档输入到变换器中,运行整个变换器推理步骤,并输出单个相似性分数。
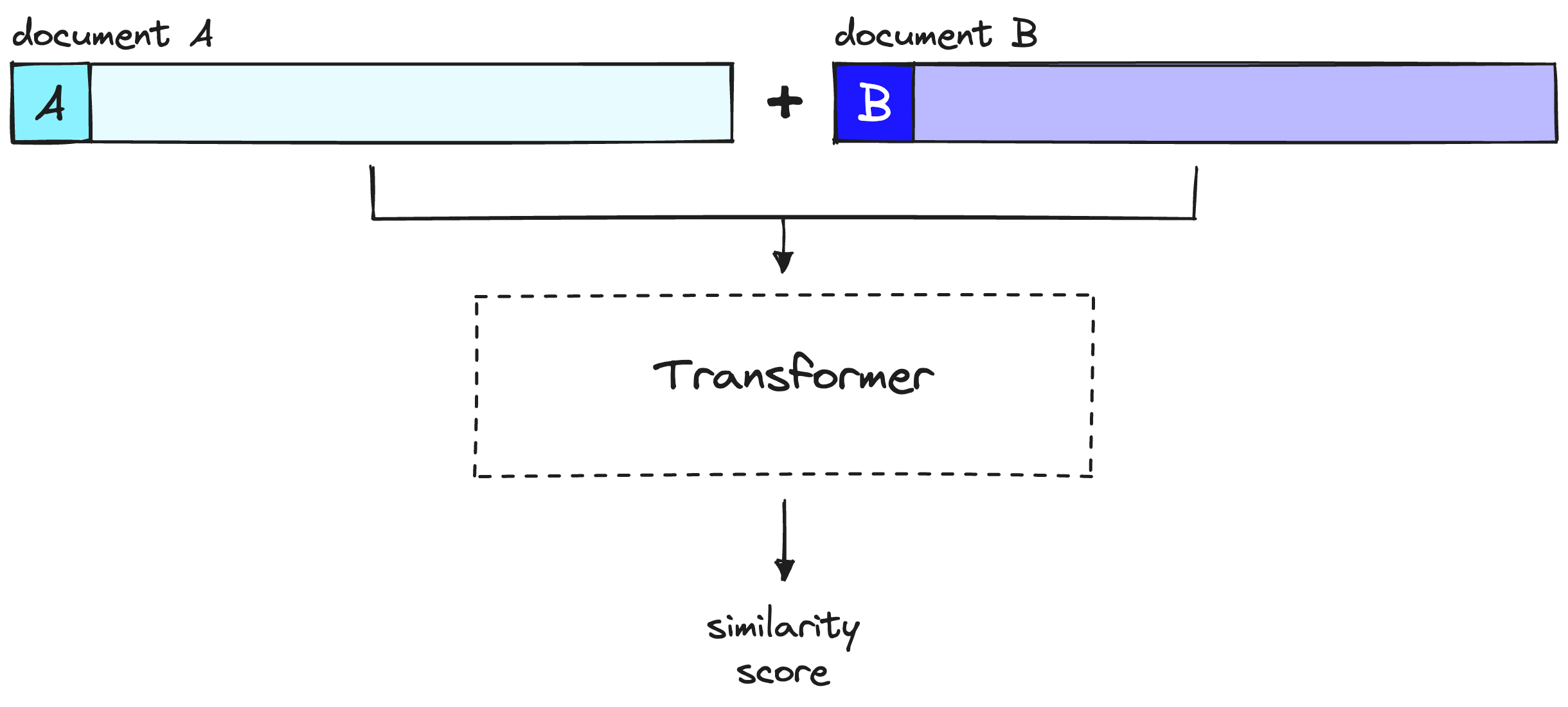
重新排序器考虑查询和文档,以在完整的变换器推理步骤中生成单个相似性分数。请注意,此处的文档A等同于我们的查询。
给定 40M 条记录,如果我们在 V100 GPU 上使用像 BERT 这样的小重新排序模型,我们将等待超过 50 小时才能返回单个查询结果 [3]。我们可以使用编码器模型和向量搜索在 <100ms 内完成相同的操作。
使用重新排序实现两阶段检索
现在我们了解了使用rerankers进行两阶段检索背后的思想和原因,让我们看看如何实现它(您可以参考此笔记本)。首先,我们将设置我们的先决条件库:
!pip install -qU \n datasets==2.14.5 \n openai==0.28.1 \n pinecone-client==2.2.4 \n cohere==4.27
数据准备
在设置检索管道之前,我们需要检索数据!我们将使用来自Hugging Face Datasets的jamescalam/ai-arxiv-chunked数据集。该数据集包含400多篇关于ML、NLP和LLMs的ArXiv论文,包括Llama 2、GPTQ和GPT-4论文。
data = load_dataset("jamescalam/ai-arxiv-chunked", split="train") data
下载数据文件: 0%| | 0/1 [00:00<?, ?it/s]
下载数据中: 0%| | 0.00/153M [00:00<?, ?B/s]
提取数据文件: 0%| | 0/1 [00:00<?, ?it/s]
生成训练集分割:0 个样本 [00:00, ? 个样本/秒]
数据集({
特征: ['doi', 'chunk-id', 'chunk', 'id', 'title', 'summary', 'source', 'authors', 'categories', 'comment', 'journal_ref', 'primary_category', 'published', 'updated', 'references'],
行数: 41584
})
该数据集包含41.5K个预分块记录。每个记录有1-2段落长,并包括有关所属论文的附加元数据。以下是一个示例:
DistilBERT, BERT的精简版本: 更小、更快、更便宜、更轻 Victor SANH, Lysandre DEBUT, Julien CHAUMOND, Thomas WOLF Hugging Face {victor,lysandre,julien,thomas}@huggingface.co 摘要 随着大规模预训练模型的迁移学习在自然语言处理(NLP)中变得更加普遍,将这些大型模型应用于边缘设备和/或受限的计算训练或推断预算仍然具有挑战性。在这项工作中,我们提出了一种方法,预训练一个更小的通用语言表示模型,称为DistilBERT,然后可以在广泛的任务上进行良好性能的微调,就像其更大的对应物一样。虽然大多数先前的工作都研究了蒸馏用于构建特定任务的模型,但我们在预训练阶段利用知识蒸馏,并展示了可以将BERT模型的大小减小40%,同时保留97%的语言理解能力,并且速度提高了60%。为了利用在预训练期间由更大模型学到的归纳偏差,我们引入了一个三重损失,结合语言建模、蒸馏和余弦距离损失。我们的更小、更快、更轻的模型更便宜进行预训练,并且我们展示了它在设备上的计算能力,通过概念验证实验和比较性的设备研究。
我们将把这些数据输入Pinecone,因此当后续进行嵌入和索引处理时,让我们重新格式化数据集,使其更适合Pinecone。格式将包含id、文本(我们将进行嵌入)和元数据。在这个示例中,我们不会使用元数据,但如果将来想要进行元数据过滤,包含元数据会很有帮助。
data = data.map(lambda x: {
"id": f'{x["id"]}-{x["chunk-id"]}',
"text": x["chunk"],
"metadata": {
"title": x["title"],
"url": x["source"],
"primary_category": x["primary_category"],
"published": x["published"],
"updated": x["updated"],
"text": x["chunk"],
}
})
# drop uneeded columns
data = data.remove_columns([
"title", "summary", "source",
"authors", "categories", "comment",
"journal_ref", "primary_category",
"published", "updated", "references",
"doi", "chunk-id",
"chunk"
])
data
地图: 0%| | 0/41584 [00:00<?, ? 例子/秒]
数据集({
特征: ['id', 'text', 'metadata'],
行数: 41584
})
嵌入和索引
为了将所有内容存储在向量数据库中,我们需要使用嵌入/双编码器模型对所有内容进行编码。为简单起见,我们将使用OpenAI的text-embedding-ada-002。我们确实需要一个OpenAI API密钥"]()来通过OpenAI客户端进行身份验证:
导入 openai
从OpenAI网站右上角的下拉菜单获取API密钥
embed_model = "文本嵌入-ada-002"
现在,我们创建我们的向量数据库来存储我们的向量。为此,我们需要获取一个免费的Pinecone API密钥 — 你可以在左侧导航栏的“API密钥”部分找到API密钥和环境变量。
初始化与 Pinecone 的连接(在 app.pinecone.io 获取 API 密钥)
api_key = "YOUR_PINECONE_API_KEY"
在 Pinecone 控制台中找到与 API 密钥相邻的环境
env = "YOUR_PINECONE_ENV"
pinecone.init(api_key=api_key, environment=env)
认证后,我们创建我们的索引。我们将维度设置为Ada-002的维度(1536),并使用与Ada-002兼容的度量,可以是余弦或点积。
index_name = "rerankers"
检查索引是否已存在(如果是第一次,它不应该存在)
if index_name not in pinecone.list_indexes(): # 如果不存在,创建索引 pinecone.create_index( index_name, dimension=1536, # ada 002 的维度 metric='dotproduct' ) # 等待索引初始化 while not pinecone.describe_index(index_name).status['ready']: time.sleep(1)
连接到索引
index = pinecone.Index(index_name)
我们现在可以开始使用OpenAI的嵌入模型来填充索引了,就像这样:
batch_size = 100 # 一次创建和插入多少个嵌入
for i in tqdm(range(0, len(data), batch_size)): passed = False # find end of batch i_end = min(len(data), i+batch_size) # create batch batch = data[i:i_end] # create embeddings (exponential backoff to avoid RateLimitError) for j in range(5): # max 5 retries try: res = openai.Embedding.create(input=batch["text"], engine=embed_model) passed = True except openai.error.RateLimitError: time.sleep(2**j) # wait 2^j seconds before retrying print("Retrying...") if not passed: raise RuntimeError("Failed to create embeddings.") # get embeddings embeds = [record['embedding'] for record in res['data']] to_upsert = list(zip(batch["id"], embeds, batch["metadata"])) # upsert to Pinecone index.upsert(vectors=to_upsert)
我们的索引现在已经填充完毕,可以进行查询了!
无需重新排序的检索
在重新排序之前,让我们看看没有重新排序的结果。我们将定义一个名为 get_docs 的函数,仅使用检索的第一阶段来返回文档:
# 编码查询
xq = embed([query])[0]
# 搜索pinecone索引
res = index.query(xq, top_k=top_k, include_metadata=True)
# 获取文档文本
docs = {x["metadata"]['text']: i for i, x in enumerate(res["matches"])}
return docs
让我们来了解一下强化学习与人类反馈(RLHF)——这是ChatGPT发布时突然表现出的性能提升背后的一种流行的微调方法。
query = "你能解释一下为什么我们想要做rlhf吗?" docs = get_docs(query, top_k=25) print("\n---\n".join(docs.keys()[:3])) # 打印前3个文档
哪些模型在面对复杂问题时被要求解释其推理过程,以增加最终答案正确的可能性。RLHF已经成为对大型语言模型进行微调的强大策略,可以显著提高它们的性能(Christiano等,2017年)。该方法首次由Stiennon等人(2020年)在文本摘要任务的背景下展示,此后已扩展到一系列其他应用。在这种范式中,模型根据人类用户的反馈进行微调,从而使模型的响应更加贴近人类的期望和偏好。Ouyang等人(2022年)证明了指导微调和RLHF的组合可以帮助解决无法通过简单扩大LLM来纠正的事实性、毒性和有用性问题。Bai等人(2022b年)通过用模型自身的自我批评和修订替换人工标记的微调数据,以及用模型替换人工评分员,部分自动化了这种微调加RLHF的方法。我们检验RLHF训练量的影响有两个原因。首先,RLHF [13, 57]是一种越来越受欢迎的技术,用于减少大型语言模型中的有害行为[3, 21, 52]。其中一些模型已经部署[52],因此我们认为RLHF的影响值得进一步审查。其次,先前的工作表明,RLHF训练量可以显著改变给定模型大小的一系列人格、政治偏好和伤害评估的指标[41]。因此,在分析我们的实验时,控制RLHF训练量是很重要的。
我们在这里获得了合理的性能 — 尤其是相关的文本片段:
| 文档 | 块 | | -------- | ------------------------------------------------------------------------------------------------- | | 0 | "使其性能显著提高" | | 0 | "通过迭代将模型的响应与人类期望和偏好更紧密地对齐" | | 0 | "指导微调和RLHF可以帮助解决事实性、毒性和实用性问题" | | 1 | "在大型语言模型中减少有害行为的越来越受欢迎的技术" |
剩下的文件和文字涵盖了RLHF,但没有回答我们特定的问题:“为什么我们想要做RLHF?”
重新排列响应
我们将使用Cohere的rerank端点进行重新排序。您需要一个Cohere API密钥来使用它。有了我们的API密钥,我们可以这样进行身份验证:
初始化客户端
co = cohere.Client("YOUR_COHERE_API_KEY")
现在,我们可以使用 co.rerank 重新排列我们的结果。让我们尝试增加第一阶段检索步骤返回的结果数量,设置 top_k=25 并对它们进行重新排列(设置 top_n=25),看看我们得到的重新排序是什么样子的。
重新排序后的结果如下:
rerank_docs = co.rerank( query=query, documents=docs.keys(), top_n=25, model="rerank-english-v2.0" )
[docs[doc.document["text"]] for doc in rerank_docs]
[0, 23, 14, 3, 12, 6, 9, 8, 1, 17, 7, 21, 2, 16, 10, 20, 18, 22, 24, 13, 19, 4, 15, 11, 5]
我们仍然在顶部有记录 0 — 这很好,因为它包含了大量与我们查询相关的信息。然而,不太相关的文档 1 和 2 分别被文档 23 和 14 替换了。
让我们创建一个函数,可以更快地比较原始结果和重新排名后的结果。
def compare(query: str, top_k: int, top_n: int):
# 首先获取向量搜索结果
docs = get_docs(query, top_k=top_k)
i2doc = {docs[doc]: doc for doc in docs.keys()}
# 重新排名
rerank_docs = co.rerank(
query=query, documents=docs.keys(), top_n=top_n, model="rerank-english-v2.0"
)
original_docs = []
reranked_docs = []
# 比较顺序变化
for i, doc in enumerate(rerank_docs):
rerank_i = docs[doc.document["text"]]
print(str(i)+"\t->\t"+str(rerank_i))
if i != rerank_i:
reranked_docs.append(f"[{rerank_i}]\n"+doc.document["text"])
original_docs.append(f"[{i}]\n"+i2doc[i])
for orig, rerank in zip(original_docs, reranked_docs):
print("ORIGINAL:\n"+orig+"\n\nRERANKED:\n"+rerank+"\n\n---\n")
我们从 RLHF 查询开始。这次,我们采用更标准的检索-重新排序流程,检索 25 个文档(top_k=25),并重新排序到前三个文档(top_n=3)。
0 -> 0 1 -> 23 2 -> 14 原始: [1] 我们检查RLHF培训量的影响有两个原因。首先,RLHF [13, 57]是一种越来越受欢迎的技术,用于减少大型语言模型[3, 21, 52]中的有害行为。其中一些模型已经部署[52],因此我们认为RLHF的影响值得进一步审查。其次,先前的工作表明,RLHF培训量可以显著改变给定模型大小的一系列人格、政治偏好和伤害评估指标[41]。因此,在分析我们的实验时,控制RLHF培训量非常重要。 3.2 实验 3.2.1 概述 我们测试自然语言指令对两种相关但不同的道德现象的影响:刻板印象和歧视。刻板印象涉及以通常是有害或不良的方式使用有关群体的概括。4为了衡量刻板印象,我们使用两个知名的刻板印象基准,BBQ[40](§3.2.2)和Windogender[49](§3.2.3)。对于歧视,我们关注模型是否基于不应与结果相关的受保护特征对个体做出不同的决策。5为了衡量歧视,我们构建了一个新的基准,以测试种族在法学课程中的影响。
RERANKED: [23] 我们已经证明,可以使用来自人类反馈的强化学习来训练语言模型,使其成为有益且无害的助手。我们的RLHF训练还提高了诚实度,尽管我们预计其他技术可能做得更好。与最近与对齐大型语言模型相关的其他作品一样[Stiennon等,2020年,Thoppilan等,2022年,Ouyang等,2022年,Nakano等,2021年,Menick等,2022年],与简单地扩大模型相比,RLHF在提高有益性和无害性方面取得了巨大进步。 我们的对齐干预实际上增强了大型模型的能力,并且可以轻松与专业技能的训练(如编码或摘要)相结合,而不会降低对齐或性能。具有不到约10B参数的模型的行为不同,它们在能力上要付出“对齐税”。这提供了一个例子,即从对齐研究中获得正确教训可能需要接近最先进水平的模型。 我们似乎发现的整体情况——大型模型可以以一种相互兼容的方式学习各种技能,包括对齐——似乎并不令人意外。以对齐方式行事只是另一种能力,许多作品已经表明,更大的模型更有能力[Kaplan等,2020年
模型用于估计更大的RL策略的最终性能。这些线的斜率还解释了RLHF训练如何能够产生如此大的模型尺寸有效增益,例如它解释了图1中的RLHF和上下文精炼线为什么大致平行。 • 人们可以对RLHF训练提出一个微妙的、也许是不太明确的问题——它是在教模型新技能,还是简单地专注于生成现有行为的子分布。我们可以尝试通过将后一类行为与RL奖励保持线性的区域相关联来明确这种区别。 • 为了做一些更大胆的猜测——也许线性关系实际上提供了RL奖励的上限,作为KL的函数。人们还可以尝试通过用Fisher几何中的测地线长度替换KL来进一步扩展这种关系。 通过使RL学习更加可预测,并识别新的行为定量类别,我们可能希望在RL训练期间检测到意想不到的行为的出现。 4.4 RLHF训练中的帮助性和无害性之间的紧张关系 在这里,我们讨论了我们在RLHF训练中遇到的一个问题。在项目的早期阶段,我们发现许多RLHF策略经常对所有远程敏感问题产生相同夸张的反应(例如,建议用户在遇到问题时寻求治疗和专业帮助)。
重新排名: [14] 模型输出安全响应,通常比普通注释者写的更详细。因此,在收集了几千个受监督的示范之后,我们完全转向了RLHF,教导模型如何写出更加细致的响应。通过RLHF进行全面调整的另一个好处是,它可能使模型更加抵抗越狱尝试(Bai等,2022a)。我们首先通过收集类似于第3.2.2节的安全性的人类偏好数据来进行RLHF:注释者编写一个他们认为可能引发不安全行为的提示,然后比较多个模型响应与提示,根据一组指南选择最安全的响应。然后我们使用人类偏好数据来训练一个安全奖励模型(参见第3.2.2节),并且在RLHF阶段重复使用对抗性提示来从模型中采样。 更好的长尾安全鲁棒性而不损害帮助性 安全性本质上是一个长尾问题,挑战来自于少数非常特定的情况。我们调查了安全性的影响
查看这些内容,我们已经从文档1中删除了一个相关的文本块,从文档2中没有删除任何相关的文本块 —— 现在以下相关的信息替换了这些内容:
| 原始位置 | 重新排名位置 | 分块 | | ----------------- | --------------- | ------------------------------------------------------------------- | | 23 | 1 | "训练语言模型,使其成为有益且无害的助手" | | 23 | 1 | "RLHF 训练还提高了诚实度" | | 23 | 1 | "RLHF 大幅提高了有益性和无害性" | | 23 | 1 | "增强大型模型的能力" | | 14 | 2 | "模型输出安全响应" | | 14 | 2 | "通常比普通标注者写的更详细" | | 14 | 2 | "RLHF 教会模型如何写出更细致的响应" | | 14 | 2 | "使模型更加抵御越狱尝试" |
我们在重新排名后获得了更多相关信息。当然,这可能会显著提高RAG的性能。这意味着我们最大化相关信息,同时最小化输入到我们的LLM中的噪音。
重新排序是在检索增强生成(RAG)或任何其他基于检索的流程中显著提高召回性能的最简单方法之一。
我们已经探讨了为什么重新排序器可以比其嵌入模型对应物提供更好的性能,以及两阶段检索系统如何使我们能够兼得两者的优势,实现大规模搜索的同时保持高质量性能。
参考资料
[1] 引入 100K 上下文窗口 (2023), Anthropic
N. 刘, K. 林, J. 休伊特, A. 帕兰贾佩, M. 贝维拉夸, F. 佩特罗尼, P. 梁, 《中间迷失:语言模型如何使用长上下文》(2023),
[3] N. Reimers, I. Gurevych, Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (2019), UKP-TUDA