LLMs 承诺从根本上改变我们在所有行业中使用人工智能的方式。然而,实际为这些模型提供服务具有挑战性,即使在昂贵的硬件上也可能会出现令人惊讶的缓慢。今天,我们很高兴地介绍 vLLM,这是一个用于快速 LLM 推断和服务的开源库。vLLM 利用了我们的新注意力算法 PagedAttention,有效地管理注意力键和值。配备 PagedAttention 的 vLLM 重新定义了 LLM 服务的最新技术水平:它的吞吐量比 HuggingFace Transformers 高出多达 24 倍,而无需进行任何模型架构更改。
vLLM已在加州大学伯克利分校开发,并在过去两个月部署在Chatbot Arena和Vicuna Demo。这是使LLM服务即使对于像LMSYS这样拥有有限计算资源的小型研究团队也能负担得起的核心技术。立即通过我们的GitHub存储库用一个命令尝试vLLM。
超越最先进的性能
我们将vLLM的吞吐量与HuggingFace Transformers (HF)(最流行的LLM库)和HuggingFace Text Generation Inference (TGI)(先前的最先进技术)进行比较。我们在两种设置下进行评估:在NVIDIA A10G GPU上进行LLaMA-7B评估,在NVIDIA A100 GPU(40GB)上进行LLaMA-13B评估。我们从ShareGPT数据集中对请求的输入/输出长度进行采样。在我们的实验中,与HF相比,vLLM的吞吐量高出24倍,比TGI高出3.5倍。
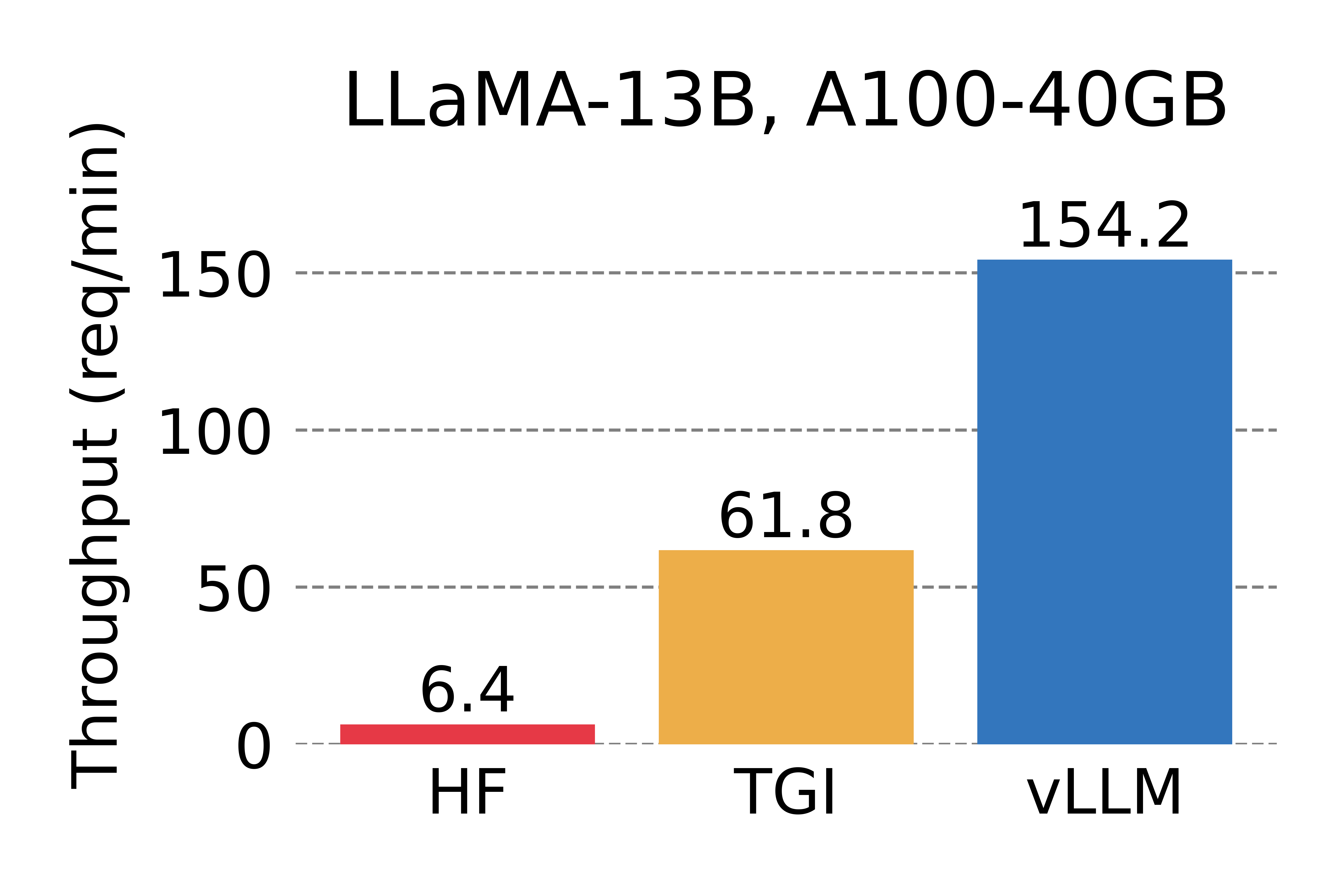
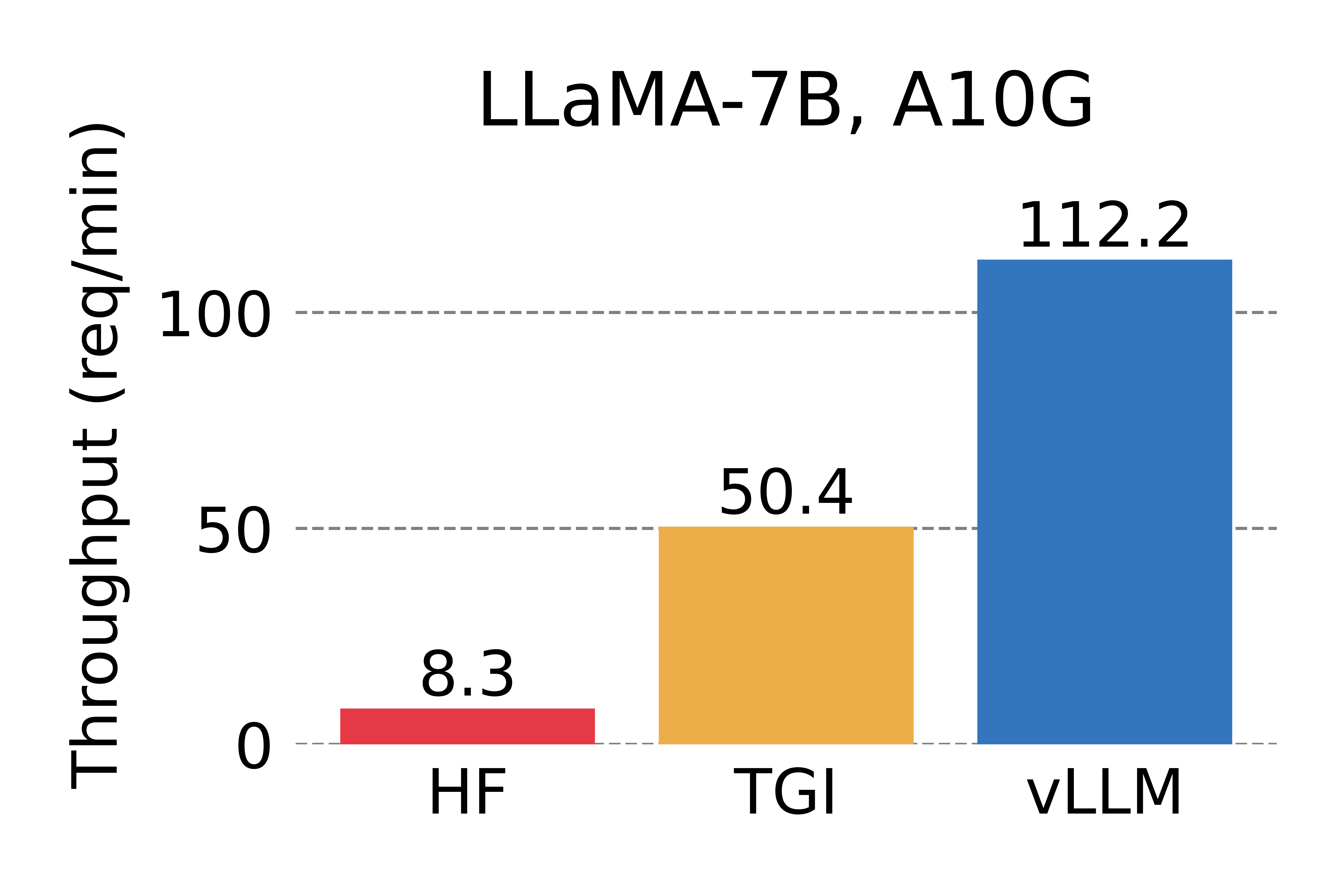
Serving throughput when each request asks for one output completion. vLLM achieves 14x - 24x higher throughput than HF and 2.2x - 2.5x higher throughput than TGI.
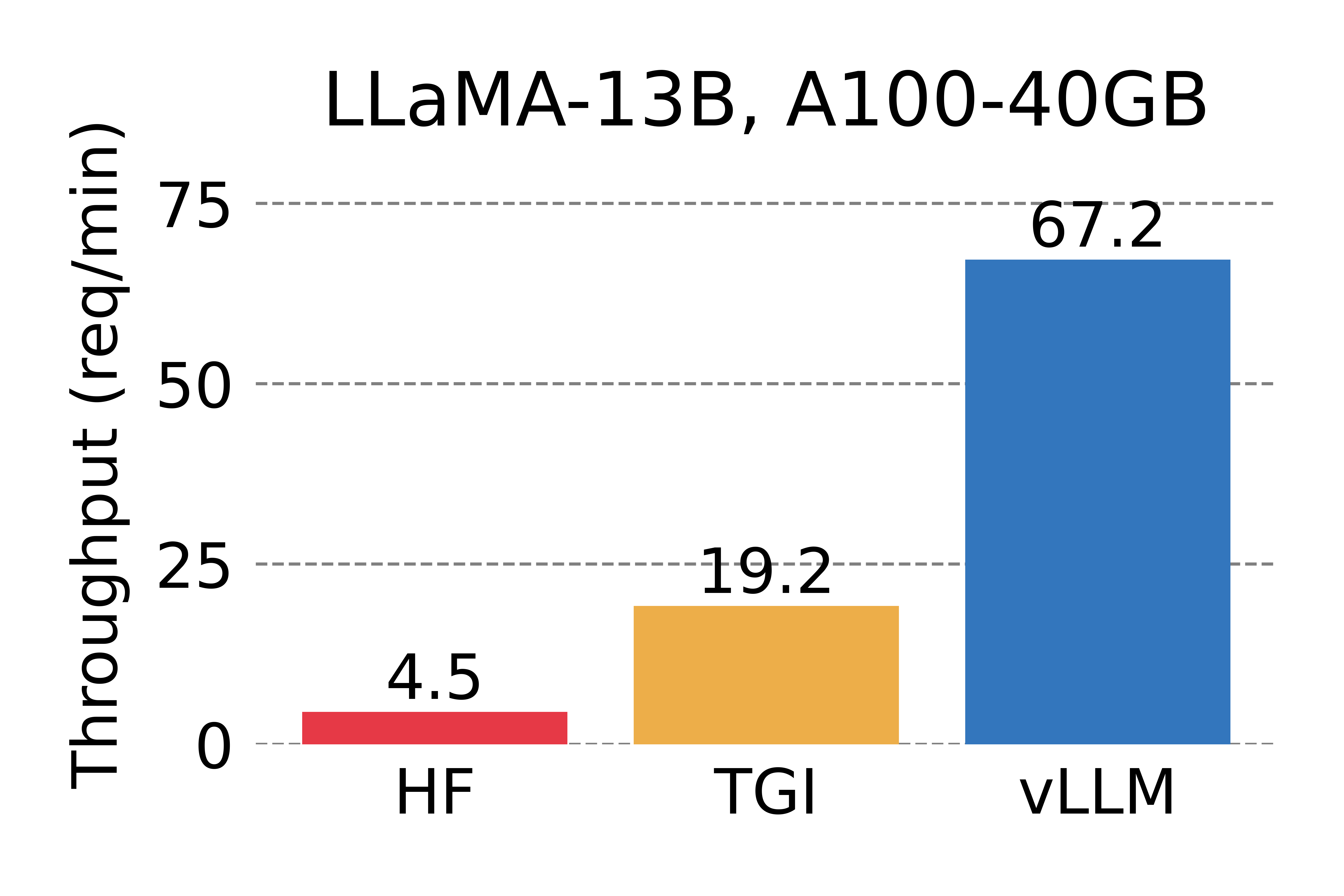
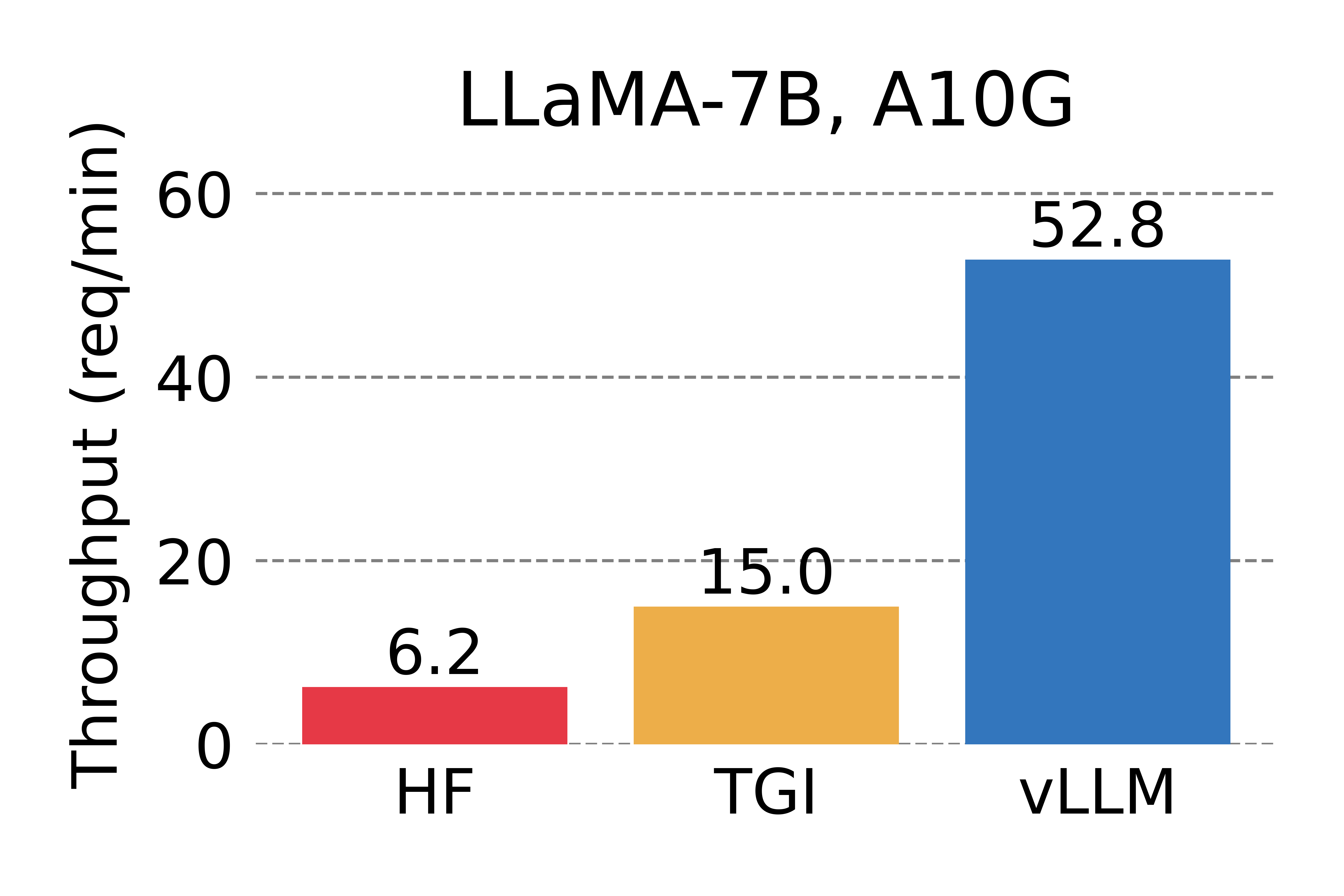
Serving throughput when each request asks for three parallel output completions. vLLM achieves 8.5x - 15x higher throughput than HF and 3.3x - 3.5x higher throughput than TGI.
秘密武器:PagedAttention
在 vLLM 中,我们发现 LLM 服务的性能受到内存的瓶颈限制。在自回归解码过程中,LLM 的所有输入标记都会产生它们的注意力键和值张量,并且这些张量会保存在 GPU 内存中以生成下一个标记。这些缓存的键和值张量通常被称为 KV 缓存。KV 缓存是
- 大: 在LLaMA-13B中,单个序列最多占用1.7GB的空间。
- 动态: 其大小取决于序列长度,这是高度可变且难以预测的。因此,有效管理KV缓存是一个重大挑战。我们发现现有系统由于碎片化和过度保留而浪费了**60% – 80%**的内存。
为解决这个问题,我们引入了PagedAttention,这是一种受操作系统虚拟内存和分页概念启发的注意力算法。与传统的注意力算法不同,PagedAttention 允许在非连续的内存空间中存储连续的键和值。具体而言,PagedAttention 将每个序列的 KV 缓存划分为块,每个块包含固定数量的令牌的键和值。在注意力计算过程中,PagedAttention 内核能够高效地识别和获取这些块。
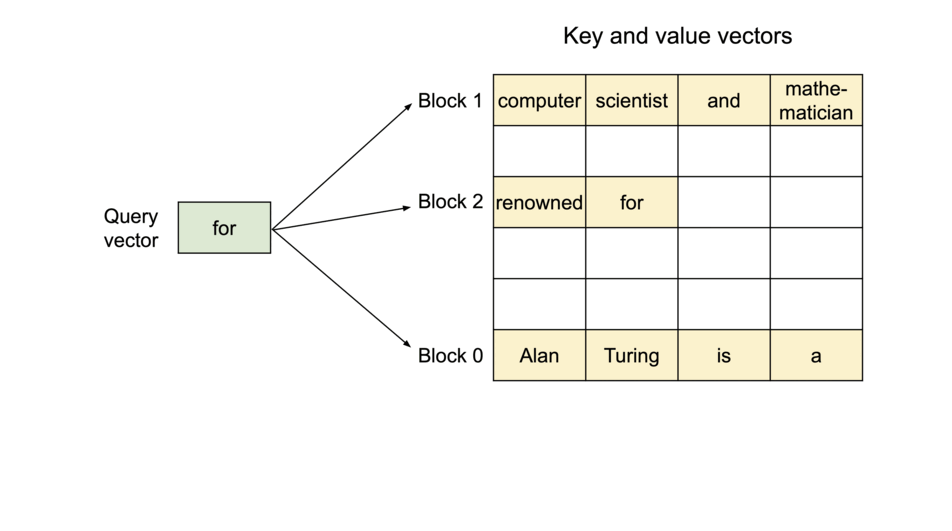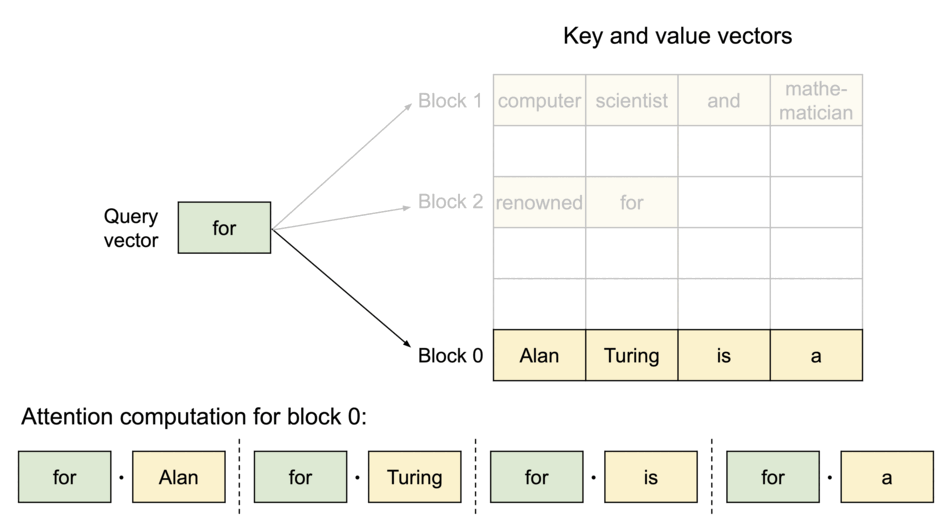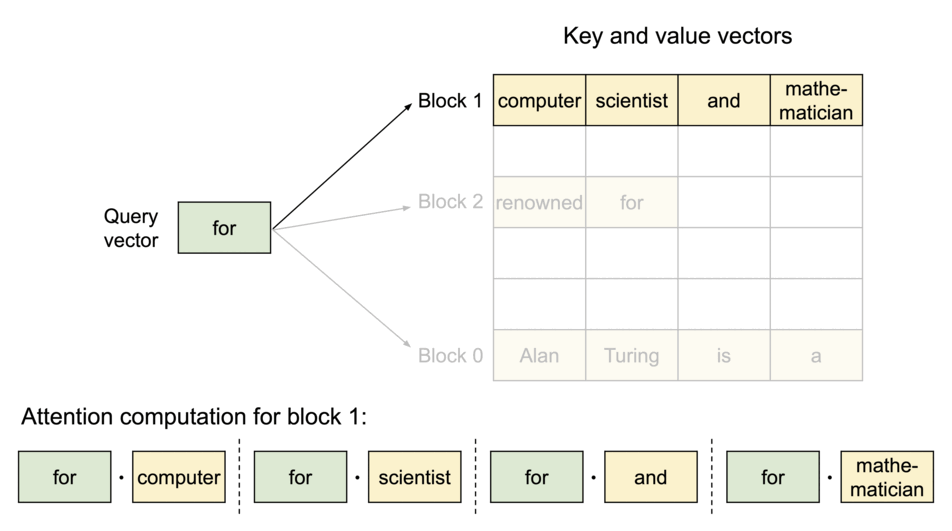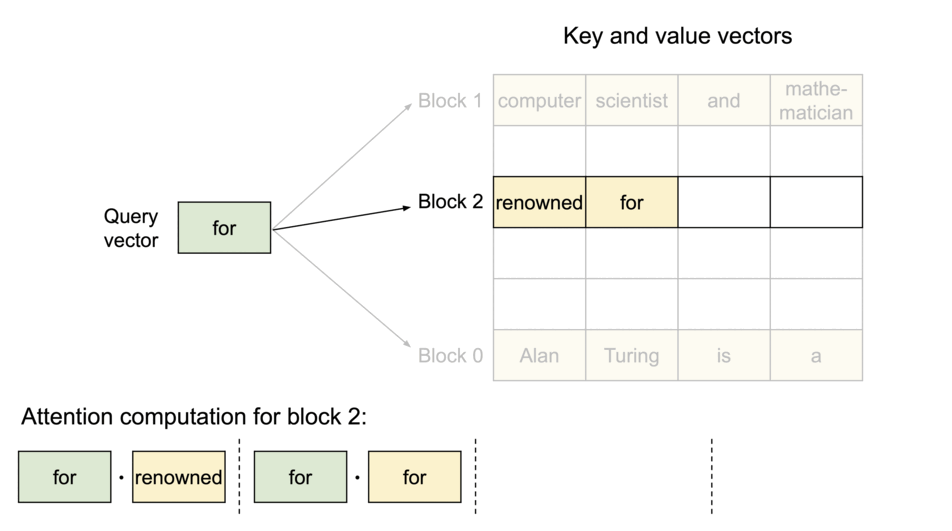
PagedAttention: KV Cache are partitioned into blocks. Blocks do not need to be contiguous in memory space.
由于块在内存中不需要连续,我们可以像操作系统的虚拟内存一样以更灵活的方式管理密钥和值:可以将块视为页面,令牌视为字节,序列视为进程。序列的连续逻辑块通过块表映射到非连续的物理块。随着生成新令牌,物理块会根据需要进行分配。
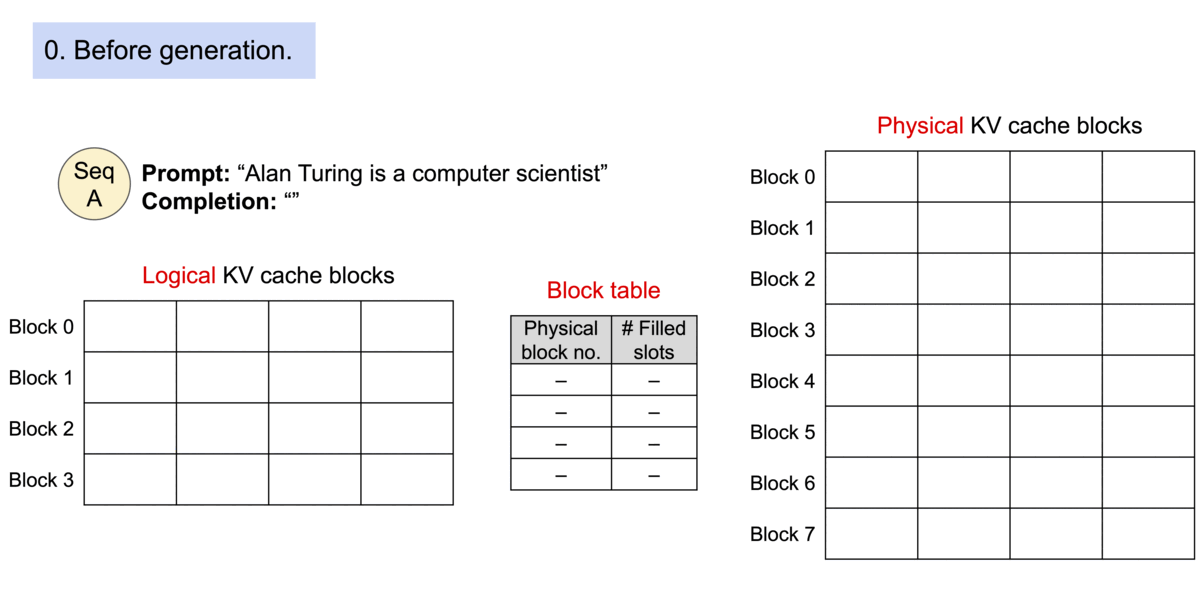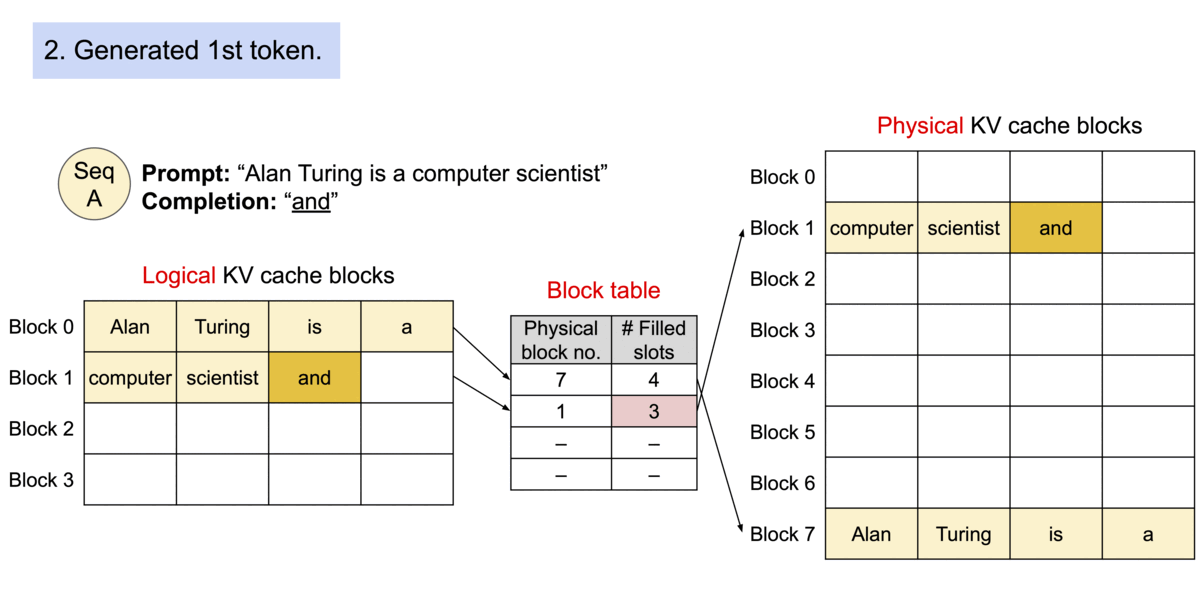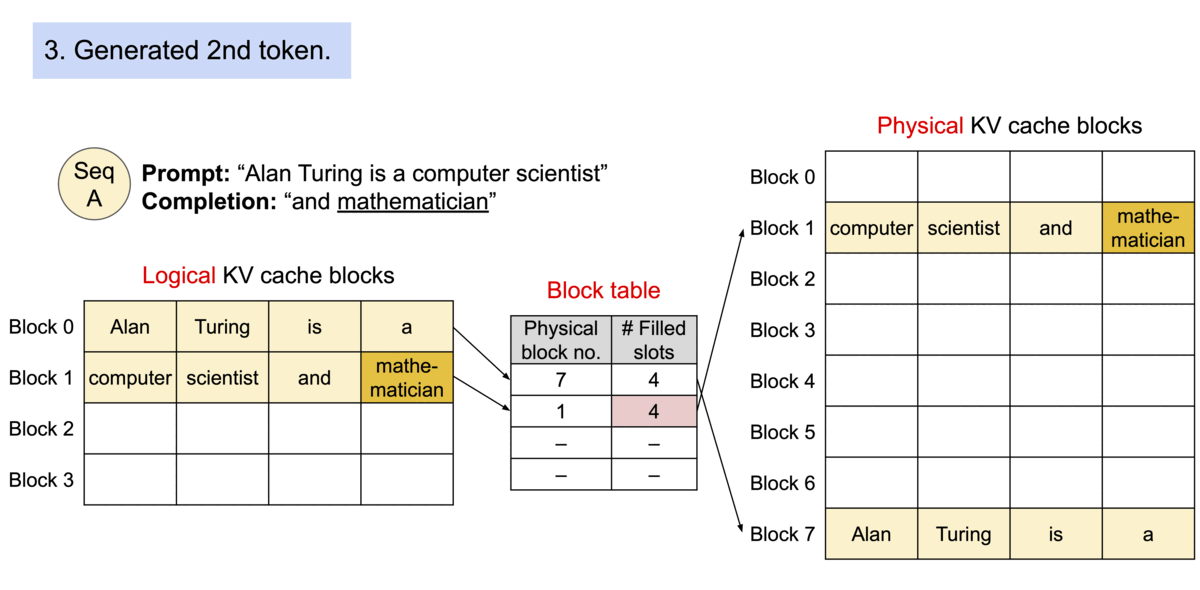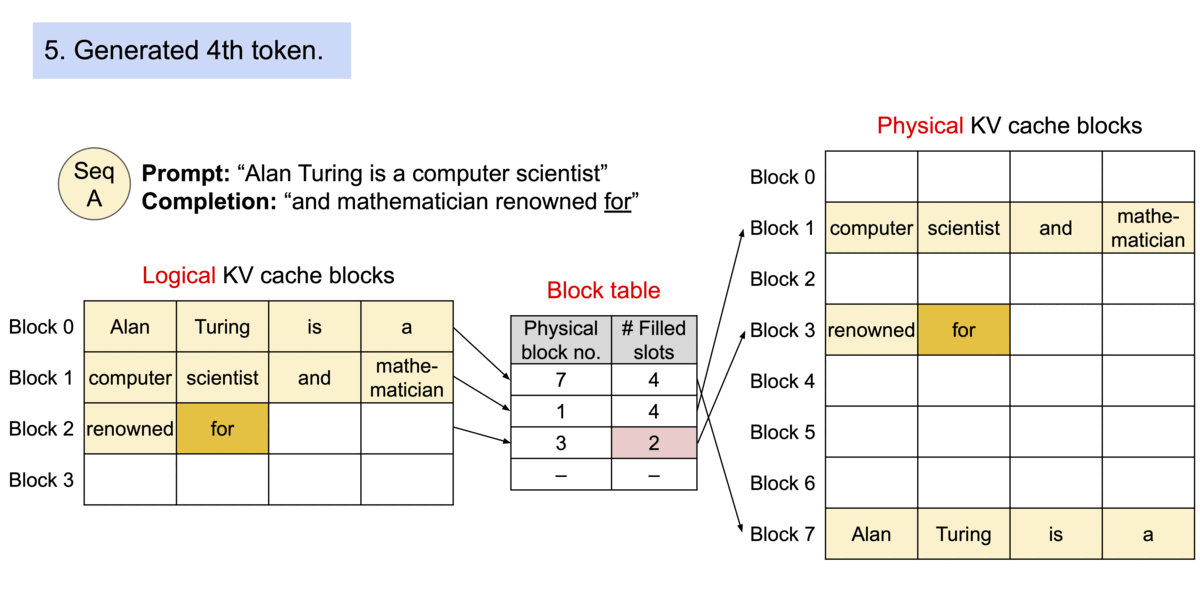
Example generation process for a request with PagedAttention.
在 PagedAttention 中,内存浪费仅发生在序列的最后一个块中。在实践中,这导致接近最佳内存使用率,仅浪费不到 4%。这种内存效率的提升非常有益:它允许系统将更多序列批处理在一起,提高 GPU 利用率,从而显著增加吞吐量,如上述性能结果所示。
PagedAttention还有另一个关键优势:高效的内存共享。例如,在_parallel sampling_中,可以从相同的提示生成多个输出序列。在这种情况下,提示的计算和内存可以在输出序列之间共享。
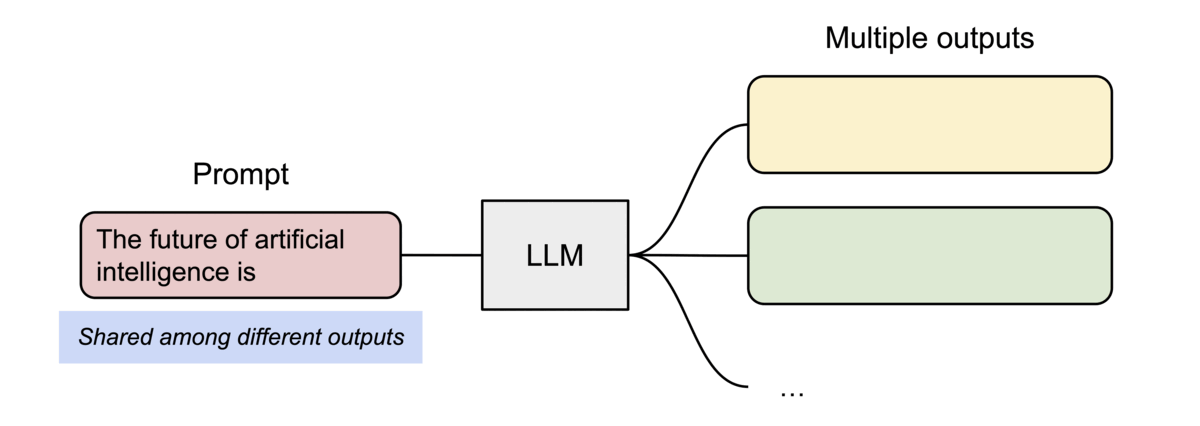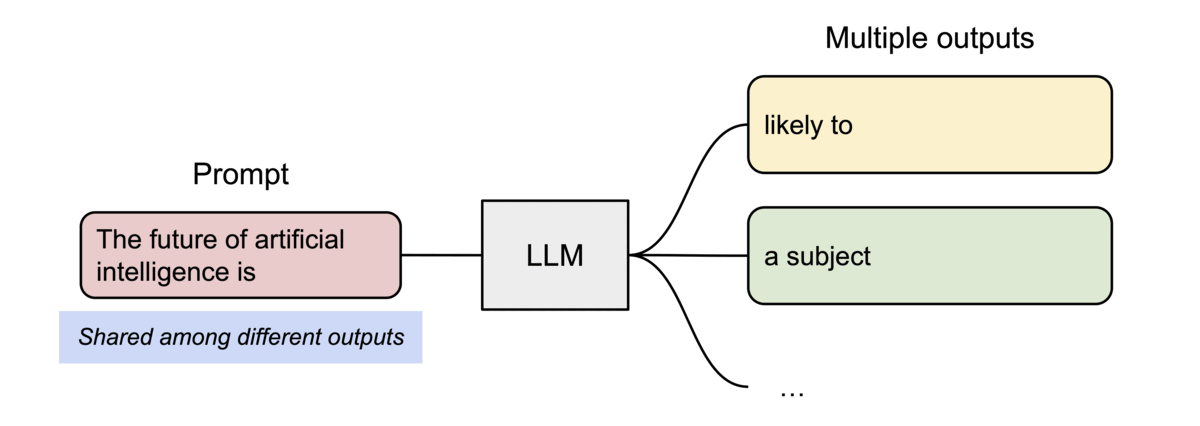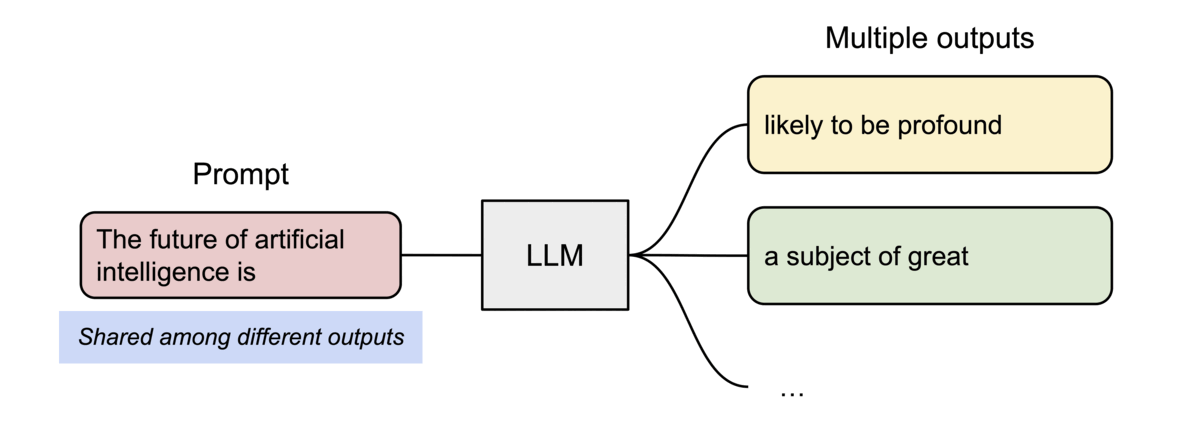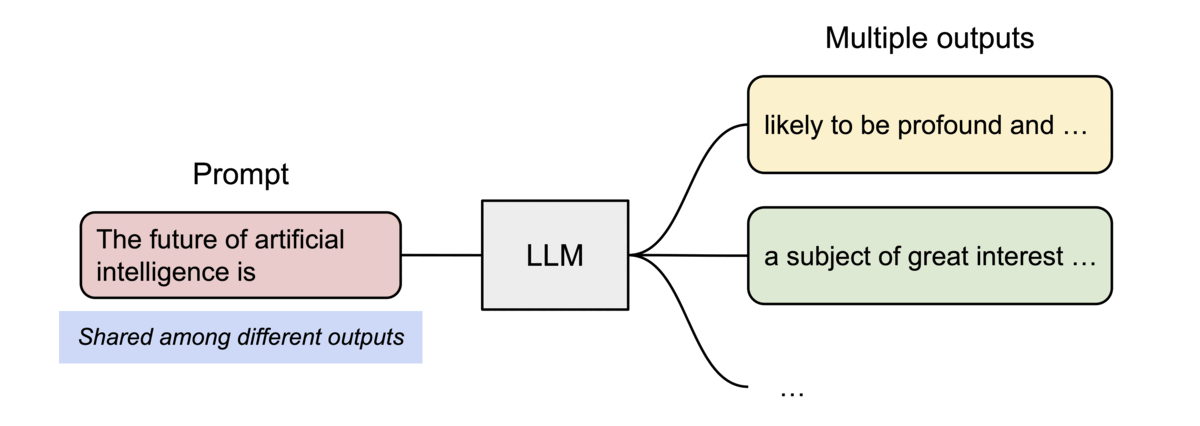
Example of parallel sampling.
PagedAttention 通过其块表自然地实现了内存共享。类似于进程共享物理页面,PagedAttention 中的不同序列可以通过将它们的逻辑块映射到相同的物理块来共享块。为了确保安全共享,PagedAttention 跟踪物理块的引用计数,并实现了 写时复制 机制。
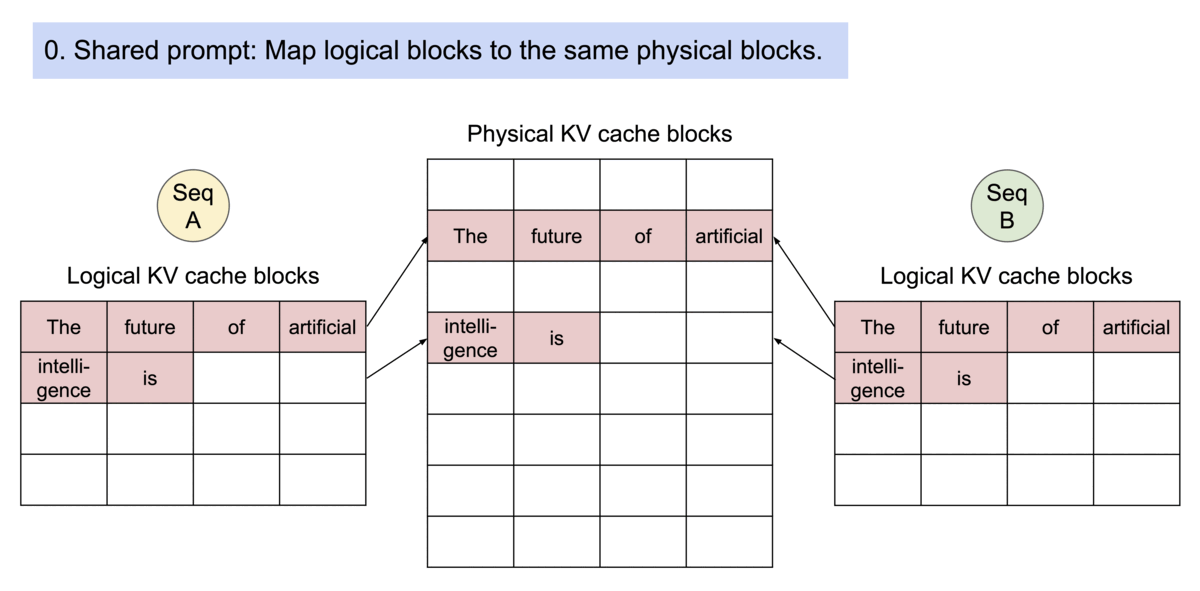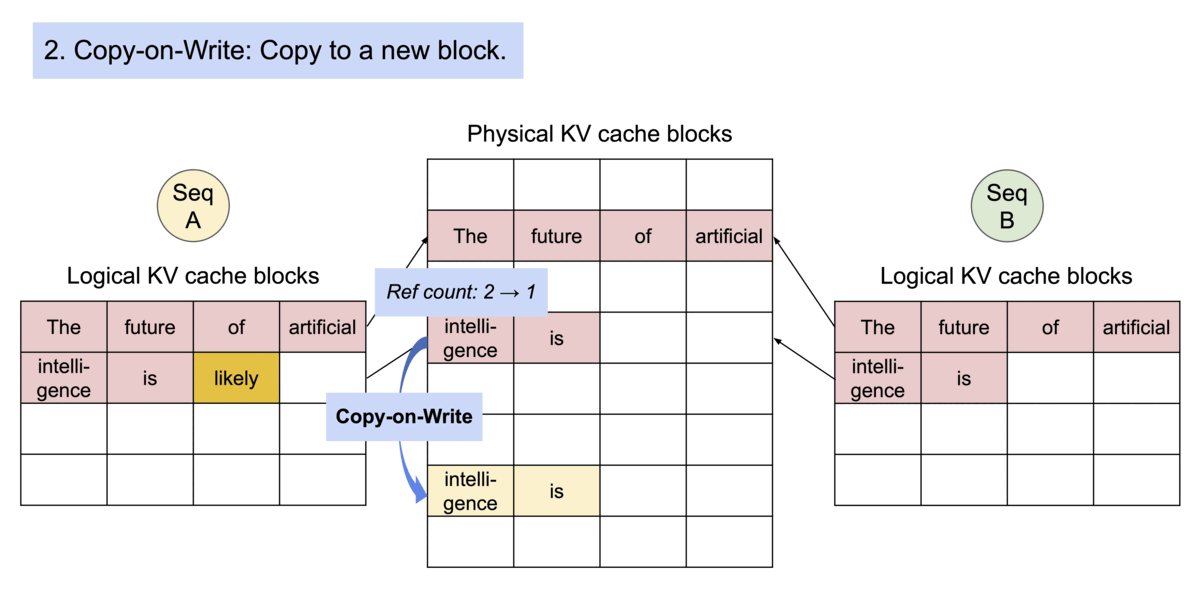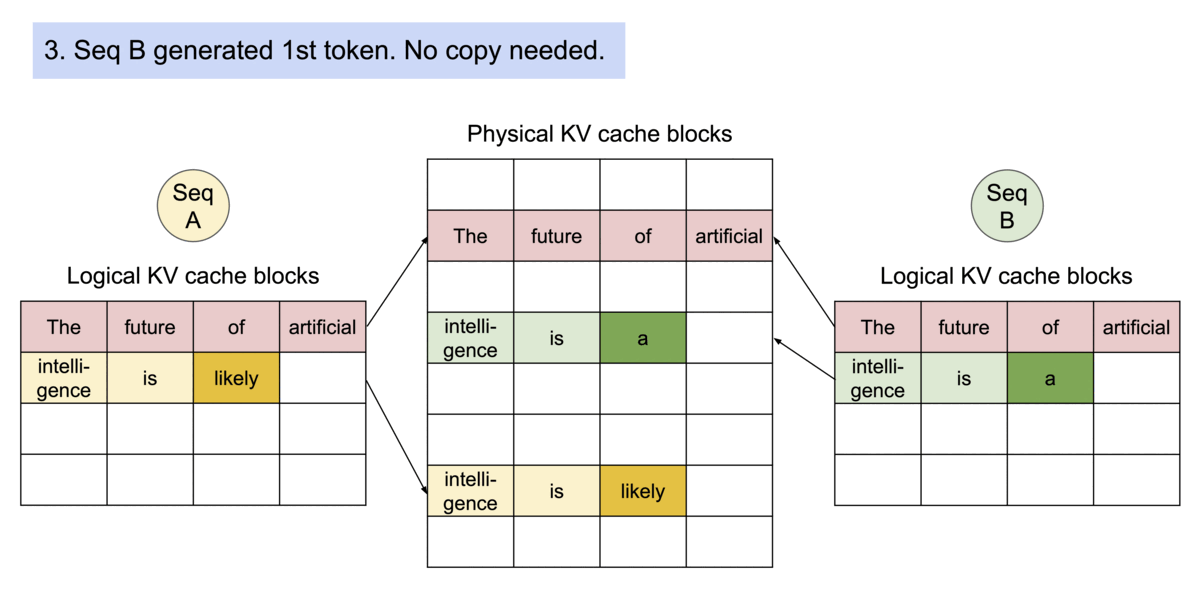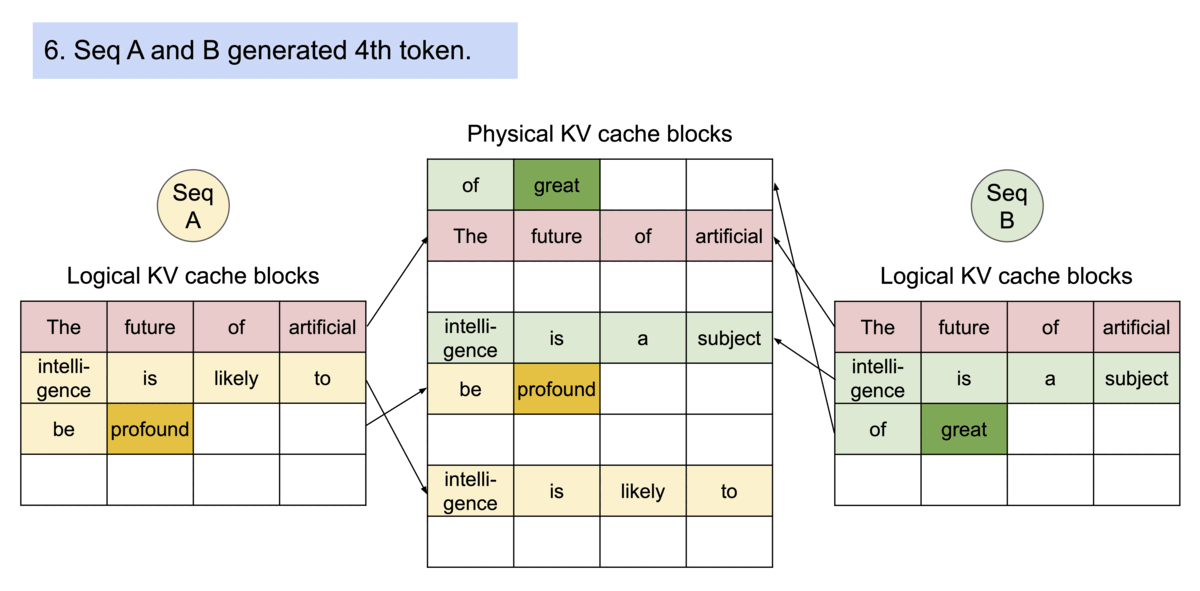
Example generation process for a request that samples multiple outputs.
PageAttention的内存共享大大降低了复杂采样算法的内存开销,例如并行采样和束搜索,将它们的内存使用量减少了高达55%。这可以转化为高达2.2倍的吞吐量提升。这使得这些采样方法在LLM服务中变得实用。
PagedAttention 是 vLLM 的核心技术,是我们的 LLM 推理和服务引擎,支持各种模型,具有高性能和易于使用的界面。有关 vLLM 和 PagedAttention 的更多技术细节,请查看我们的 GitHub 仓库,敬请关注我们的论文。
LMSYS维库纳和聊天机器人竞技场背后的无声英雄
今年四月,LMSYS 开发了备受欢迎的维库纳聊天机器人模型,并将其公开发布。从那时起,维库纳已在Chatbot Arena 为数百万用户提供服务。最初,LMSYS FastChat 采用了基于 HF Transformers 的服务后端 来提供聊天演示。随着演示变得越来越受欢迎,峰值流量增加了数倍,使 HF 后端成为一个重要的瓶颈。LMSYS 和 vLLM 团队共同努力,很快开发了 FastChat-vLLM 集成,以使用 vLLM 作为新的后端 以支持不断增长的需求(高达 5 倍的流量)。在 LMSYS 进行的早期内部微基准测试 中,vLLM 服务后端的吞吐量可达到初始 HF 后端的 30 倍。
自四月中旬以来,Vicuna、Koala 和 LLaMA 等最受欢迎的模型都已成功使用 FastChat-vLLM 集成服务——FastChat 作为多模型聊天服务前端,vLLM 作为推理后端,LMSYS 能够利用有限数量的大学赞助的 GPU 为数百万用户提供 Vicuna,实现高吞吐量和低延迟。LMSYS 正在将 vLLM 的使用扩展到更广泛的模型,包括 Databricks Dolly、LAION 的 OpenAsssiant 和 Stability AI 的 stableLM。支持更多模型 正在开发中并即将推出。
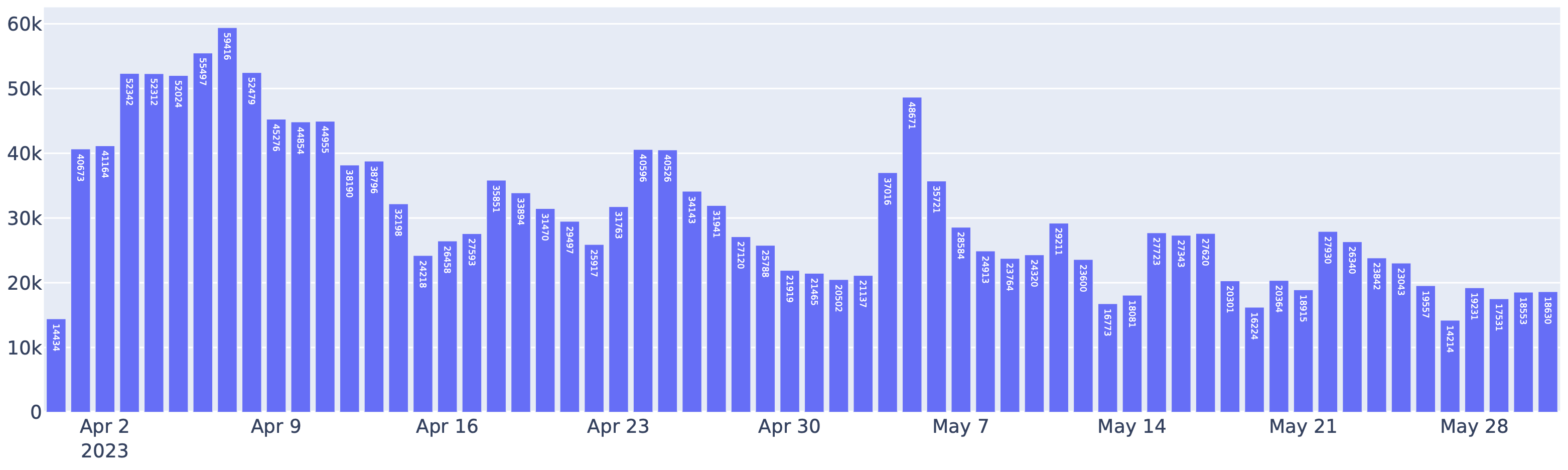
Requests served by FastChat-vLLM integration in the Chatbot Arena between April to May. Indeed, more than half of the requests to Chatbot Arena use vLLM as the inference backend.
vLLM的应用还显著降低了运营成本。通过vLLM,LMSYS成功将用于处理上述流量的GPU数量减少了50%。vLLM每天处理平均30K个请求,峰值达到60K,这清楚展示了vLLM的稳健性。
开始使用 vLLM
使用以下命令安装 vLLM(查看我们的安装指南了解更多):
vLLM可用于离线推断和在线服务。要将vLLM用于离线推断,您可以导入vLLM并在Python脚本中使用LLM类:
prompts = ["你好,我的名字是", "法国的首都是"] # 示例提示。 llm = LLM(model="lmsys/vicuna-7b-v1.3") # 创建一个LLM。 outputs = llm.generate(prompts) # 从提示生成文本。
要在线使用 vLLM,您可以通过以下方式启动一个兼容 OpenAI API 的服务器:
您可以使用与OpenAI API相同的格式查询服务器:
$ curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "lmsys/vicuna-7b-v1.3",
"prompt": "旧金山是一个",
"max_tokens": 7,
"temperature": 0
}''
要了解更多使用 vLLM 的方法,请查看快速入门指南。
_由Woosuk Kwon和Zhuohan Li(加州大学伯克利分校)撰写的博客。特别感谢Hao Zhang整合vLLM和FastChat,并撰写相应部分。我们感谢整个团队——Siyuan Zhuang、Ying Sheng、Lianmin Zheng(加州大学伯克利分校)、Cody Yu(独立研究员)、Joey Gonzalez(加州大学伯克利分校)、Hao Zhang(加州大学伯克利分校和加州大学圣地亚哥分校)以及Ion Stoica(加州大学伯克利分校)。