不久前,我在谈论一个ahead-of-time Ruby 编译器。我们在开始这个项目时有一些目标和假设,虽然原始编译器的完成度接近90%,但仍然有另外90%的工作需要完成。
与此同时,我们决定将其简化到最低限度,仅实现足够的功能以验证假设。
就像我们使用的原始编译器一样,我们使用 MLIR 来弥合 Ruby VM 的字节码与代码生成之间的差距,但我们不是直接针对 LLVM IR,而是通过 EmitC 方言并针对 C 语言,因为这显著简化了操作系统/CPU 的支持。我们稍后会详细讨论。
我们的极简 Ruby 编译器的源代码在这里: https://github.com/dragonruby/lightstorm。
文章的其余部分涵盖了我们为什么决定构建它,我们是如何解决这个问题的,以及我们在过程中发现了什么。
动机与使用案例
我们的用例非常简单:我们正在构建 一个以独立开发者为中心、富有生产力且易于使用的跨平台游戏引擎。游戏引擎本身是用 C 和 Ruby 混合编写的,但主要用户界面是 Ruby 本身。
一旦游戏开发完成,游戏准备好“部署”,代码或多或少是静态的,因此我们问自己是否可以将其预编译为机器代码以使其运行更快。
但是考虑到 Ruby 的所有活力,为什么编译会让它更快呢?
所以我们的假设来了。但首先让我们看一些高层次的实现细节,以了解假设的来源。
编译器与解释器
虽然一种语言本身不能严格地被归类为编译型或解释型,但典型的实现确实是。
在“编译型”语言的情况下,编译器会将整个程序进行分析,并生成针对特定硬件(真实或虚拟)的机器代码,而解释器则会立即执行程序,一次执行一条“指令”。
上面的定义有点模糊:放大到足够远,一切都是编译器;放大到足够近,一切都是解释器。但你明白大意了.
大多数 Ruby 实现是基于解释器的,在我们的案例中我们使用 mruby。
mruby 解释器是一个轻量级的基于寄存器的虚拟机 (VM)。
让我们看一个具体的例子。以下这段代码:
被转换为以下 VM 字节码,由各种操作(简称 ops)组成:
加载 R1 42
加载 R2 15
加法 R1 R2
停止
虚拟机的解释器循环如下所示(伪代码):
dispatch_next:
Op op = bytecode.next_op();
switch (op.opcode) {
case LOADI: {
vstack.store(op.dest, mrb_int(op.literal));
goto dispatch_next;
}
case ADD: {
mrb_value lhs = vstack.load(op.lhs);
mrb_value rhs = vstack.load(op.rhs);
vstack.store(op.dest, mrb_add(lhs, rhs));
goto dispatch_next;
}
// 更多操作...
case HALT: goto halt_vm;
}
停止虚拟机:
// ...
对于每个字节码操作,虚拟机将跳转/分支到正确的操作码处理程序,然后再分支回调度循环的开始。与此同时,每个操作码处理程序将使用一个虚拟栈(混淆地位于堆上)来存储中间结果。
如果我们手动展开上述字节码,那么代码可能看起来像这样:
goto loadi_1;
loadi_1:
// LOADI R1 42
mrb_value t1 = mrb_int(42);
vstack.store(1, t1);
goto loadi_2;
loadi_2:
// LOADI R2 42
mrb_value t2 = mrb_int(15);
vstack.store(2, t2);
goto add;
添加:
// 添加 R1 R2
mrb_value lhs = vstack.load(1);
mrb_value rhs = vstack.load(2);
mrb_value t3 = mrb_add(lhs, rhs);
vstack.store(1, t3);
goto halt;
停止:
// 关闭虚拟机
在这个例子中,许多项目可以被消除:具体来说,我们可以避免从堆中加载/存储,并且我们可以安全地消除 goto/分支:
mrb_value t1 = mrb_int(42);
mrb_value t2 = mrb_int(15);;
mrb_value t3 = mrb_add(t1, t2);
vstack.store(1, t3);
goto halt;
停止:
// 关闭虚拟机
所以我们的假设是:
通过预编译/展开虚拟机调度循环,我们可以消除许多加载/存储和分支以及分支错误预测,这应该会提高最终程序的性能。
我们还可以尝试基于高级字节码分析应用一些优化,但由于 Ruby 的动态性,静态优化的表面是有限的。
方法
正如开头所提到的,构建一个完整的 AOT 编译器是一项繁重的任务,需要时间并且有一定的限制。
对于简约版,我们决定更改/放宽一些约束,如下所示:
- 编译后的代码必须与现有生态系统/运行时兼容
- 现有运行时不应需要任何更改
- 支持的语言特性应该能够在 C 中轻松“表示”
与原始编译器不同,我们并不是直接针对机器代码,而是针对 C。这消除了很多复杂性,但这也意味着我们只支持语言的一个子集(例如,目前缺少块和异常)。
这显然不是理想的,但它有重要的目的 - 我们此时的目标是验证假设。
一个经典的编译管道如下所示:
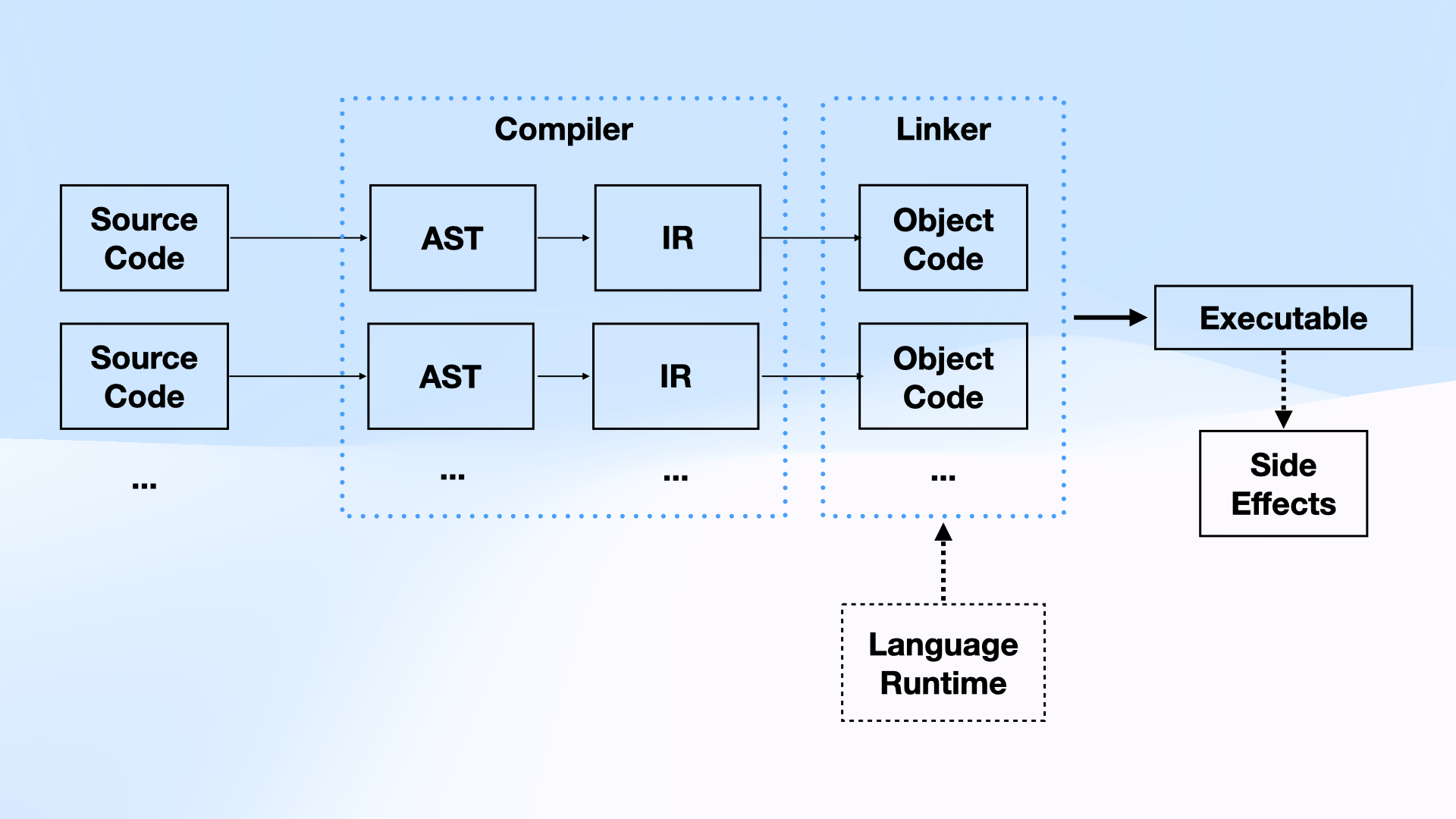
要构建一个编译器,需要实现从原始源文件到机器代码和语言运行时库的转换。由于我们针对现有的实现,因此可以重用前端(解析 + 抽象语法树)和运行时库的优势。
不过,我们需要实现从 AST 到机器代码的转换。这就是 MLIR 的强大之处:我们构建了一个自定义方言 (Rite),它表示 mruby VM 的字节码,然后使用多个内置方言 (cf, func, arith, emitc) 将我们的 IR 转换为 C 代码。
在这一点上,我们可以直接使用 clang 将代码与现有的运行时编译/链接在一起,就这样。
最终的编译管道如下所示:
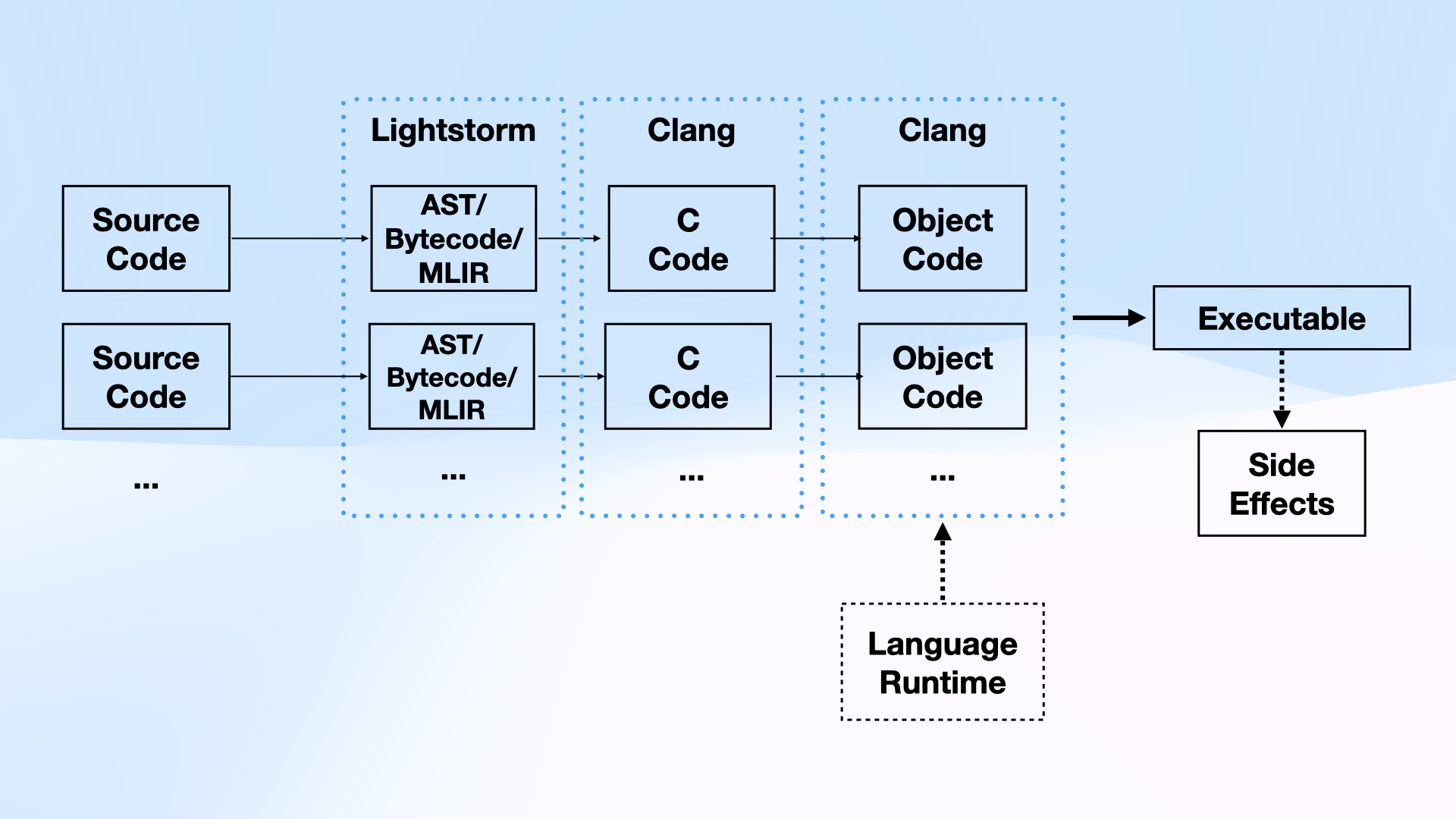
借助 MLIR 的优势,我们能够在仅仅几千行代码中构建一个功能完整的编译器!
现在让我们看看它的表现。
一些数字
基准测试很难,所以对这些数字要持保留态度。
我们运行了各种(微)基准测试,显示的结果在1%到1200%的加速范围内,但我们坚持使用aobench,因为它与我们目标的游戏开发工作负载非常接近。
mruby 还使用 aobench 作为其基准测试套件的一部分,尽管我们稍微修改了它,将 Number.each 块替换为显式的 while 循环。
接下来我们使用了优秀的 simple-kpc 库来捕获 Apple M1 CPU 上的 CPU 计数器,即我们收集总周期、总指令计数、分支、分支错误预测和加载/存储(FIXED_CYCLES、FIXED_INSTRUCTIONS、INST_BRANCH、BRANCH_MISPRED_NONSPEC 和 INST_LDST)。
当然,我们也会收集总执行时间。
所有基准测试将普通字节码解释与“展开”的编译版本进行比较。
我们正在使用 mruby 3.0。虽然在撰写时它不是最新版本,但在我们构建编译器时它是最新版本。
下图显示了我们的测量结果。我们比较的三个版本分别是左侧的基线、中间没有优化的编译版本,以及右侧的编译版本加上 简单逃逸分析 和公共子表达式消除 (CSE)。
原始数据和公式在 这里.
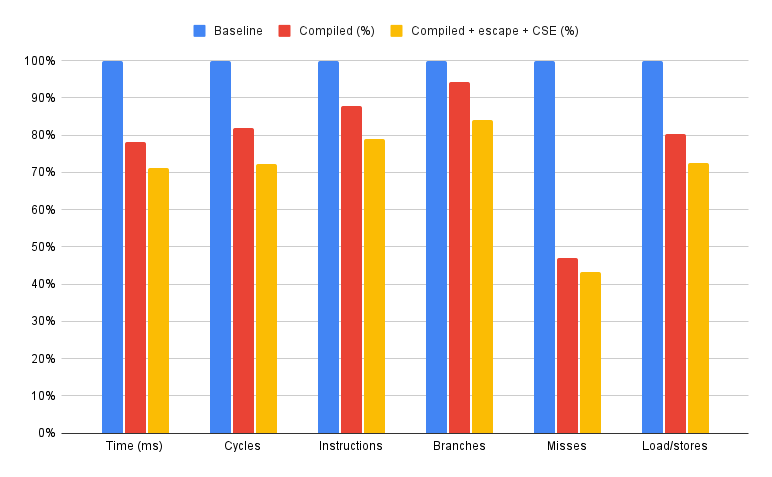
在当前所有优化到位的情况下,周期数和总执行时间大约减少了 ~30%。
我们能够消除约17%的分支和约28%的加载/存储,同时分支未命中减少了一半,下降了约55%。
这些数字看起来很有前景,尽管随着我们实现所有语言特性,负载/存储和分支的数量肯定会增加,因为块和异常的处理方式。
另一方面,我们没有触及运行时实现,结合 LTO 将会由于更多的内联而实现一些更大的改进。
接下来去哪里?
正如开头提到的,发动机的某些部分是用 C 编写的,部分则纯粹是出于性能原因。我们正在考虑用编译后的 Ruby 替换那些关键部分。虽然我们可能仍然会付出性能代价,但我们希望维护的便利性是值得的。