Trong bài viết này, chúng tôi sẽ đào sâu vào cách hoạt động bên trong của Google, một công cụ mà chúng ta đều sử dụng hàng ngày nhưng ít người thực sự hiểu biết. Sau vụ rò rỉ tài liệu gần đây trong một vụ kiện chống độc quyền đối với Google, chúng ta có cơ hội độc đáo để khám phá các thuật toán của Google. Một số trong số các thuật toán này đã được biết trước, nhưng điều thú vị là thông tin nội bộ mà chưa bao giờ được chia sẻ với chúng ta.
Chúng tôi sẽ xem xét cách các công nghệ này xử lý các tìm kiếm của chúng ta và xác định kết quả chúng ta thấy. Trong phân tích này, tôi nhằm cung cấp một cái nhìn rõ ràng và chi tiết về các hệ thống phức tạp đằng sau mỗi tìm kiếm trên Google.
Hơn nữa, tôi sẽ cố gắng biểu diễn kiến trúc của Google trong một sơ đồ, xem xét các phát hiện mới.
Tôi sẽ cố gắng giải thích mỗi thuật toán dựa trên thông tin chính thức, nếu có sẵn, và sau đó đưa thông tin được trích xuất từ thử nghiệm vào một hình ảnh.

Navboost
Điều này rất quan trọng đối với Google và là một trong những yếu tố quan trọng nhất. Điều này cũng được tiết lộ trong vụ rò rỉ thông tin năm 2019 của «Project Veritas» vì Paul Haar đã thêm nó vào CV của mình

Navboost thu thập dữ liệu về cách người dùng tương tác với kết quả tìm kiếm, cụ thể là thông qua việc họ nhấp chuột vào các truy vấn khác nhau. Hệ thống này tổng hợp các lượt nhấp và sử dụng các thuật toán học từ các xếp hạng chất lượng do con người tạo ra để cải thiện thứ hạng của kết quả. Ý tưởng là nếu một kết quả thường được chọn (và được đánh giá tích cực) cho một truy vấn cụ thể, có lẽ nó nên có một thứ hạng cao hơn. Thú vị là, Google đã thử nghiệm nhiều năm trước việc loại bỏ Navboost và phát hiện ra rằng kết quả trở nên tồi hơn.

RankBrain
Ra mắt vào năm 2015, RankBrain là một hệ thống trí tuệ nhân tạo và học máy của Google, quan trọng trong việc xử lý kết quả tìm kiếm. Thông qua học máy, nó liên tục cải thiện khả năng hiểu ngôn ngữ và ý định đằng sau các tìm kiếm và đặc biệt hiệu quả trong việc diễn giải các truy vấn mơ hồ hoặc phức tạp. Nó được cho là đã trở thành yếu tố quan trọng thứ ba trong việc xếp hạng của Google, sau nội dung và liên kết. Nó sử dụng một Tensor Processing Unit (TPU) để cải thiện đáng kể khả năng xử lý và hiệu suất năng lượng.

Tôi suy luận rằng QBST và Term Weighting là các thành phần của RankBrain. Vì vậy, tôi bao gồm chúng ở đây.
QBST (Query Based Salient Terms) tập trung vào các thuật ngữ quan trọng nhất trong một truy vấn và tài liệu liên quan, sử dụng thông tin này để ảnh hưởng đến cách kết quả được xếp hạng. Điều này có nghĩa là công cụ tìm kiếm có thể nhanh chóng nhận ra các khía cạnh quan trọng nhất của truy vấn của người dùng và ưu tiên kết quả liên quan. Ví dụ, điều này đặc biệt hữu ích đối với các truy vấn mơ hồ hoặc phức tạp.
Trong tài liệu lời khai, QBST được đề cập trong ngữ cảnh của các hạn chế của BERT. Đề cập cụ thể là «BERT không thể thay thế các hệ thống ghi nhớ lớn như navboost, QBST, v.v.» Điều này có nghĩa là mặc dù BERT rất hiệu quả trong việc hiểu và xử lý ngôn ngữ tự nhiên, nhưng nó vẫn có những hạn chế, trong đó có khả năng xử lý hoặc thay thế các hệ thống ghi nhớ quy mô lớn như QBST.

Định trọng từ điều chỉnh mức độ quan trọng tương đối của các từ cá nhân trong một truy vấn, dựa trên cách người dùng tương tác với kết quả tìm kiếm. Điều này giúp xác định mức độ liên quan của một số từ cụ thể trong ngữ cảnh của truy vấn. Định trọng này cũng xử lý một cách hiệu quả các từ rất phổ biến hoặc rất hiếm trong cơ sở dữ liệu của công cụ tìm kiếm, từ đó cân bằng kết quả.

DeepRank
Đi một bước xa hơn trong việc hiểu ngôn ngữ tự nhiên, giúp cho công cụ tìm kiếm hiểu rõ hơn ý định và ngữ cảnh của các truy vấn. Điều này được thực hiện nhờ BERT; thực tế, DeepRank là tên nội bộ cho BERT. Bằng việc tiền huấn luyện trên một lượng lớn dữ liệu tài liệu và điều chỉnh với phản hồi từ việc nhấp chuột và đánh giá của con người, DeepRank có thể điều chỉnh kết quả tìm kiếm để trở nên trực quan và phù hợp hơn với những gì người dùng thực sự đang tìm kiếm.

RankEmbed
RankEmbed có lẽ tập trung vào việc nhúng các đặc tính liên quan để xếp hạng. Mặc dù không có thông tin cụ thể về chức năng và khả năng trong tài liệu, chúng ta có thể suy luận rằng đó là một hệ thống học sâu được thiết kế để cải thiện quá trình phân loại tìm kiếm của Google.
RankEmbed-BERT
RankEmbed-BERT là phiên bản cải tiến của RankEmbed, tích hợp thuật toán và cấu trúc của BERT. Việc tích hợp này được thực hiện để cải thiện đáng kể khả năng hiểu ngôn ngữ của RankEmbed. Hiệu quả của nó có thể giảm nếu không được đào tạo lại với dữ liệu gần đây. Đối với việc đào tạo, nó chỉ sử dụng một phần nhỏ của lưu lượng truy cập, cho thấy rằng không cần thiết phải sử dụng tất cả dữ liệu có sẵn.
RankEmbed-BERT đóng góp, cùng với các mô hình học sâu khác như RankBrain và DeepRank, vào điểm xếp hạng cuối cùng trong hệ thống tìm kiếm của Google, nhưng sẽ hoạt động sau khi kết quả ban đầu được lấy ra lại (sắp xếp lại). Nó được huấn luyện trên dữ liệu click và truy vấn và được điều chỉnh tinh tế bằng dữ liệu từ các người đánh giá con người (IS) và tốn nhiều chi phí tính toán hơn để huấn luyện so với các mô hình feedforward như RankBrain.

MUM
Nó mạnh khoảng 1.000 lần so với BERT và đại diện cho một bước tiến lớn trong tìm kiếm của Google. Được ra mắt vào tháng 6 năm 2021, nó không chỉ hiểu được 75 ngôn ngữ mà còn là đa dạng, có nghĩa là nó có thể hiểu và xử lý thông tin ở các định dạng khác nhau. Khả năng đa dạng này cho phép MUM cung cấp phản hồi toàn diện và ngữ cảnh hơn, giảm cần phải tìm kiếm nhiều lần để có thông tin chi tiết. Tuy nhiên, việc sử dụng nó rất lựa chọn do yêu cầu tính toán cao của nó.

Tangram và Keo
Tất cả các hệ thống này hoạt động cùng nhau trong khuôn khổ của Tangram, có trách nhiệm lắp ráp SERP với dữ liệu từ Glue. Điều này không chỉ là vấn đề xếp hạng kết quả, mà còn là việc tổ chức chúng một cách hữu ích và dễ tiếp cận đối với người dùng, xem xét các yếu tố như carousel hình ảnh, câu trả lời trực tiếp và các yếu tố không phải là văn bản khác.

Cuối cùng, Freshness Node và Instant Glue đảm bảo rằng kết quả là hiện tại, đặt nhiều trọng số hơn cho thông tin gần đây, điều này đặc biệt quan trọng trong việc tìm kiếm tin tức hoặc sự kiện hiện tại.

Trong phiên tòa, họ đề cập đến vụ tấn công tại Nice, nơi ý định chính của truy vấn đã thay đổi vào ngày tấn công, dẫn đến Instant Glue ngăn chặn hình ảnh tổng quát sang Tangram và thay vào đó quảng bá tin tức và hình ảnh liên quan từ Nice («nice pictures» vs «Nice pictures»):

Với tất cả điều này, Google sẽ kết hợp những thuật toán này để:
- Hiểu câu truy vấn: Giải mã ý định đằng sau những từ và cụm từ mà người dùng nhập vào thanh tìm kiếm.
- Xác định sự liên quan: Xếp hạng kết quả dựa trên mức độ phù hợp với câu truy vấn, sử dụng tín hiệu từ các tương tác trước đó và xếp hạng chất lượng.
- Ưu tiên sự mới mẻ: Đảm bảo rằng thông tin mới nhất và phù hợp nhất sẽ nổi lên trong xếp hạng khi cần thiết.
- Cá nhân hóa kết quả: Tùy chỉnh kết quả tìm kiếm không chỉ dựa trên câu truy vấn mà còn dựa trên ngữ cảnh của người dùng, như vị trí và thiết bị họ đang sử dụng. Không có sự cá nhân hóa nhiều hơn thế này nữa.
Từ tất cả những gì chúng tôi đã thấy cho đến nay, tôi tin rằng Tangram, Glue, và RankEmbed-BERT là những sản phẩm mới duy nhất đã bị rò rỉ cho đến nay.
Như chúng ta đã thấy, những thuật toán này được cung cấp bởi các chỉ số khác nhau mà chúng ta sẽ phân tích chi tiết ngay bây giờ, một lần nữa, để rút thông tin từ thử nghiệm.
Các chỉ số được Google sử dụng để đánh giá chất lượng tìm kiếm
Trong phần này, chúng tôi sẽ tập trung lại vào Lời chứng bác bỏ của Giáo sư Douglas W. Oard và bao gồm thông tin từ một vụ rò rỉ trước đó, vụ rò rỉ «Project Veritas».
Trong một trong những slide, đã được cho thấy rằng Google sử dụng các chỉ số sau để phát triển và điều chỉnh các yếu tố mà thuật toán của mình xem xét khi xếp hạng kết quả tìm kiếm và để theo dõi cách thay đổi trong thuật toán của mình ảnh hưởng đến chất lượng kết quả tìm kiếm. Mục tiêu là cố gắng nắm bắt ý định của người dùng thông qua chúng.
1. Điểm IS
Người đánh giá đóng vai trò quan trọng trong việc phát triển và hoàn thiện các sản phẩm tìm kiếm của Google. Qua công việc của họ, chỉ số được biết đến là «IS score» (Điểm Hài lòng Thông tin từ 0 đến 100) được tạo ra, phát sinh từ việc đánh giá của người đánh giá và được sử dụng như một chỉ số chính về chất lượng trong Google.
Nó được đánh giá một cách ẩn danh, nơi người đánh giá không biết họ đang kiểm tra Google hay Bing, và nó được sử dụng để so sánh hiệu suất của Google so với đối thủ chính của nó.
Các điểm IS này không chỉ phản ánh chất lượng được cảm nhận mà còn được sử dụng để huấn luyện các mô hình khác nhau trong hệ thống tìm kiếm của Google, bao gồm các thuật toán phân loại như RankBrain và RankEmbed BERT.
Theo tài liệu, tính đến năm 2021, họ đang sử dụng IS4. IS4 được coi là một xấp xỉ của tiện ích cho người dùng và nên được xem xét như vậy. Nó được mô tả là có thể là thước đo xếp hạng quan trọng nhất, tuy nhiên họ nhấn mạnh rằng đó là một xấp xỉ và dễ mắc phải lỗi mà chúng ta sẽ thảo luận sau này.

Một đạo hàm của chỉ số này, IS4@5, cũng được đề cập.
Chỉ số IS4@5 được Google sử dụng để đo lường chất lượng của kết quả tìm kiếm, tập trung đặc biệt vào năm vị trí đầu tiên. Chỉ số này bao gồm cả các tính năng tìm kiếm đặc biệt, như OneBoxes (được biết đến với tên gọi là «blue links»). Có một biến thể của chỉ số này, được gọi là IS4@5 web, tập trung duy nhất vào việc đánh giá năm kết quả web đầu tiên, loại bỏ các yếu tố khác như quảng cáo trong kết quả tìm kiếm.

Mặc dù IS4@5 hữu ích để nhanh chóng đánh giá chất lượng và sự liên quan của kết quả hàng đầu trong một cuộc tìm kiếm, phạm vi của nó bị hạn chế. Nó không bao phủ tất cả các khía cạnh của chất lượng tìm kiếm, đặc biệt là bỏ qua các yếu tố như quảng cáo trong kết quả. Do đó, chỉ số này cung cấp một cái nhìn một phần về chất lượng tìm kiếm. Để đánh giá đầy đủ và chính xác về chất lượng của kết quả tìm kiếm của Google, cần phải xem xét một loạt các chỉ số và yếu tố rộng hơn, tương tự như cách sức khỏe tổng quát được đánh giá thông qua một loạt các chỉ số và không chỉ dựa vào cân nặng.
**Hạn chế của các người đánh giá
Người đánh giá đối mặt với một số vấn đề, như là hiểu các truy vấn kỹ thuật hoặc đánh giá sự phổ biến của sản phẩm hoặc các diễn giải của các truy vấn. Ngoài ra, các mô hình ngôn ngữ như MUM có thể hiểu ngôn ngữ và kiến thức toàn cầu tương tự như người đánh giá, đặt ra cả cơ hội và thách thức cho tương lai của việc đánh giá sự liên quan.
Mặc dù quan trọng, quan điểm của họ khác biệt đáng kể so với quan điểm của người dùng thực sự. Người đánh giá có thể thiếu kiến thức cụ thể hoặc kinh nghiệm trước đó mà người dùng có thể có liên quan đến một chủ đề truy vấn, có thể ảnh hưởng đến đánh giá của họ về tính liên quan và chất lượng của kết quả tìm kiếm.
Từ các tài liệu rò rỉ từ năm 2018 và 2021, tôi đã có thể biên soạn một danh sách của tất cả các lỗi mà Google nhận ra trong các bài thuyết trình nội bộ của họ.
- Sự không phù hợp về thời gian: Có thể xảy ra sai lệch vì các truy vấn, đánh giá và tài liệu có thể từ các thời điểm khác nhau, dẫn đến việc đánh giá không phản ánh chính xác sự liên quan hiện tại của tài liệu. 2. Tái sử dụng đánh giá: Thói quen tái sử dụng đánh giá để nhanh chóng đánh giá và kiểm soát chi phí có thể dẫn đến việc đánh giá không đại diện cho sự tươi mới hoặc sự liên quan hiện tại của nội dung. 3. Hiểu biết về truy vấn kỹ thuật: Người đánh giá có thể không hiểu rõ về các truy vấn kỹ thuật, dẫn đến khó khăn trong việc đánh giá sự liên quan của các chủ đề chuyên ngành hoặc chuyên sâu. 4. Đánh giá sự phổ biến: Có khó khăn vốn có cho người đánh giá trong việc đánh giá sự phổ biến giữa các truy vấn cạnh tranh hoặc các sản phẩm đối thủ, điều này có thể ảnh hưởng đến độ chính xác của đánh giá của họ. 5. Đa dạng về người đánh giá: Sự thiếu đa dạng trong số người đánh giá ở một số địa điểm, và thực tế rằng họ đều là người lớn tuổi, không phản ánh sự đa dạng của người dùng của Google, bao gồm cả trẻ em. 6. Nội dung do người dùng tạo ra: Người đánh giá thường khắc nghiệt với nội dung do người dùng tạo ra, điều này có thể dẫn đến đánh giá thấp giá trị và sự liên quan của nó, mặc dù nó có ích và liên quan. 7. Huấn luyện nút Tươi mới: Họ chỉ ra một vấn đề với việc điều chỉnh mô hình tươi mới do thiếu nhãn huấn luyện đủ. Người đánh giá thường không chú ý đủ đến khía cạnh tươi mới của sự liên quan hoặc thiếu bối cảnh thời gian cho truy vấn. Điều này dẫn đến việc đánh giá thấp kết quả gần đây cho các truy vấn tìm kiếm tính mới mẻ. Công cụ Tangram hiện có, dựa trên IS và được sử dụng để huấn luyện các đường cong Đánh giá và điểm số khác, gặp phải vấn đề tương tự. Do hạn chế của nhãn con người, các đường cong điểm số của Nút Tươi mới đã được điều chỉnh thủ công khi phát hành lần đầu.
Tôi tin tưởng rằng những người đánh giá con người đã đóng vai trò quan trọng trong việc hoạt động hiệu quả của "Parasite SEO", một điều đã thu hút sự chú ý của Danny Sullivan và được chia sẻ trong tweet này:

Nếu chúng ta nhìn vào những thay đổi trong hướng dẫn chất lượng mới nhất, chúng ta có thể thấy cách họ cuối cùng đã điều chỉnh định nghĩa của các chỉ số Đáp ứng Nhu cầu và đã bao gồm một ví dụ mới để các người đánh giá xem xét, ngay cả khi một kết quả có tính quyền lực, nếu nó không chứa thông tin mà người dùng đang tìm kiếm, thì không nên được đánh giá cao.

Sự ra mắt của Google Notes mới, theo tôi, cũng chỉ ra điều này. Google không thể biết chắc chắn 100% điều gì là nội dung chất lượng.

Tôi tin rằng những sự kiện mà tôi đang thảo luận, đã xảy ra gần như đồng thời, không phải là một sự trùng hợp và chúng ta sẽ sớm thấy những thay đổi.
2. PQ (Page Quality)
Tôi suy luận rằng họ đang nói về Chất lượng Trang, vì vậy đây là sự giải thích của tôi. Nếu đúng như vậy, không có gì trong các tài liệu thử nghiệm ngoài việc đề cập đến nó như một chỉ số đã sử dụng. Điều duy nhất chính thức mà tôi có đề cập đến PQ là từ Hướng dẫn Đánh giá Chất lượng Tìm kiếm, mà thay đổi theo thời gian. Vì vậy, đó sẽ là một nhiệm vụ khác cho các người đánh giá con người.

Thông tin này cũng được gửi đến các thuật toán để tạo ra các mô hình. Ở đây chúng ta có thể thấy một đề xuất về điều này đã bị rò rỉ trong «Project Veritas»:

Một điểm thú vị ở đây, theo tài liệu, người đánh giá chất lượng chỉ đánh giá các trang trên thiết bị di động.

3. Cạnh nhau
Điều này có thể liên quan đến các bài kiểm tra trong đó hai bộ kết quả tìm kiếm được đặt cạnh nhau để người đánh giá có thể so sánh chất lượng tương đối của chúng. Điều này giúp xác định bộ kết quả nào phù hợp hơn hoặc hữu ích hơn đối với một truy vấn tìm kiếm cụ thể. Nếu đúng như vậy, tôi nhớ rằng Google đã có công cụ có thể tải xuống cho việc này, là sxse.

Công cụ cho phép người dùng bình chọn cho bộ kết quả tìm kiếm mà họ ưa thích, do đó cung cấp phản hồi trực tiếp về hiệu quả của các điều chỉnh hoặc phiên bản khác nhau của hệ thống tìm kiếm.
4. Thực nghiệm Trực tiếp
Thông tin chính thức được công bố trong Cách Tìm Kiếm Hoạt Động cho biết rằng Google tiến hành các thử nghiệm với lưu lượng thực để kiểm tra cách mà mọi người tương tác với một tính năng mới trước khi triển khai nó cho tất cả mọi người. Họ kích hoạt tính năng cho một phần trăm nhỏ người dùng và so sánh hành vi của họ với một nhóm kiểm soát không có tính năng đó. Các chỉ số chi tiết về tương tác của người dùng với kết quả tìm kiếm bao gồm:
- Số lần nhấp vào kết quả
- Số lần tìm kiếm thực hiện
- Từ bỏ truy vấn
- Thời gian mất để người dùng nhấp vào kết quả
Dữ liệu này giúp đo lường xem việc tương tác với tính năng mới có tích cực không và đảm bảo rằng những thay đổi tăng cường tính liên quan và tính hữu ích của kết quả tìm kiếm.
Nhưng tài liệu thử nghiệm chỉ nổi bật hai chỉ số:

- Chỉ số click dài có trọng số vị trí: Chỉ số này sẽ xem xét thời lượng của các lần click và vị trí của chúng trên trang kết quả, phản ánh sự hài lòng của người dùng với kết quả họ tìm thấy. 2. Sự chú ý: Điều này có thể ám chỉ việc đo lường thời gian dành cho trang, cho một ý tưởng về việc người dùng tương tác với kết quả và nội dung của chúng trong bao lâu.
Hơn nữa, trong bản biên bản lời khai của Pandu Nayak, được giải thích rằng họ tiến hành nhiều thử nghiệm thuật toán sử dụng phương pháp xen kẽ thay vì thử nghiệm truyền thống A/B. Điều này cho phép họ thực hiện các thử nghiệm nhanh chóng và đáng tin cậy, từ đó giúp họ hiểu rõ sự biến động trong thứ hạng.
5. Tươi mát
Sự tươi mới là một khía cạnh quan trọng của cả kết quả và Tính năng Tìm kiếm. Việc hiển thị thông tin liên quan ngay khi nó có sẵn và ngừng hiển thị nội dung khi nó trở nên lỗi thời là rất quan trọng.
Để các thuật toán xếp hạng hiển thị tài liệu mới nhất trong kết quả trang SERP, hệ thống lập chỉ mục và phục vụ phải có khả năng khám phá, lập chỉ mục và phục vụ tài liệu mới với độ trễ rất thấp. Mặc dù lý tưởng, toàn bộ chỉ mục sẽ cập nhật càng nhanh càng tốt, nhưng có các ràng buộc kỹ thuật và chi phí ngăn cản việc lập chỉ mục mọi tài liệu với độ trễ thấp. Hệ thống lập chỉ mục ưu tiên các tài liệu trên các đường dẫn riêng biệt, cung cấp các sự đánh đổi khác nhau giữa độ trễ, chi phí và chất lượng.
Có nguy cơ rằng nội dung rất mới sẽ bị đánh giá thấp về mức độ liên quan và, ngược lại, nội dung có nhiều bằng chứng về mức độ liên quan sẽ trở nên ít quan trọng hơn do sự thay đổi trong ý nghĩa của truy vấn.

Vai trò của Freshness Node là để thêm sửa đổi vào các điểm số lỗi thời. Đối với các truy vấn tìm kiếm nội dung mới, nó thúc đẩy nội dung mới và giảm giá trị của nội dung lỗi thời.
Không lâu trước, đã có tin rò rỉ rằng Google Caffeine không còn tồn tại (còn được biết đến với tên hệ thống lập chỉ mục dựa trên Percolator). Mặc dù bên trong, tên cũ vẫn được sử dụng, nhưng thực tế hiện tại là một hệ thống hoàn toàn mới. «Caffeine» mới thực sự là một tập hợp các dịch vụ siêu nhỏ giao tiếp với nhau. Điều này ngụ ý rằng các phần khác nhau của hệ thống lập chỉ mục hoạt động như các dịch vụ độc lập nhưng liên kết với nhau, mỗi dịch vụ thực hiện một chức năng cụ thể. Cấu trúc này có thể cung cấp tính linh hoạt, khả năng mở rộng và dễ dàng cập nhật và cải tiến.
Khi tôi giải thích, một phần của các dịch vụ micro này sẽ là Tangram và Glue, cụ thể là Freshness Node và Instant Glue. Tôi nói điều này vì trong một tài liệu rò rỉ khác từ «Project Veritas» tôi thấy rằng đã có một đề xuất từ năm 2016 để tạo ra hoặc tích hợp một «Instant Navboost» như một tín hiệu Freshness, cũng như lượt truy cập từ Chrome.

Cho đến nay, họ đã tích hợp «Freshdocs-instant» (được trích từ một danh sách pubsub gọi là freshdocs-instant-docs pubsub, nơi họ lấy tin tức được đăng bởi các phương tiện truyền thông đó trong vòng 1 phút kể từ khi được đăng) và các đỉnh tìm kiếm và tương quan tạo nội dung:

Trong các chỉ số Freshness, chúng tôi có một số chỉ số được phát hiện nhờ phân tích của Correlated Ngrams và Correlated Salient Terms:
- Các NGram Tương quan: Đây là nhóm từ xuất hiện cùng nhau theo một mô hình có ý nghĩa thống kê. Sự tương quan có thể tăng đột ngột trong một sự kiện hoặc chủ đề đang nổi, cho thấy sự tăng đột ngột. 2. Các Thuật ngữ Nổi bật Tương quan: Đây là những thuật ngữ nổi bật mà chặt chẽ liên kết với một chủ đề hoặc sự kiện và tần suất xuất hiện của chúng tăng trong tài liệu trong một khoảng thời gian ngắn, gợi ý đến sự tăng đột ngột trong sự quan tâm hoặc hoạt động liên quan.
Sau khi phát hiện được các đỉnh, các chỉ số Freshness sau có thể được sử dụng:
- Unigrams (RTW): Đối với mỗi tài liệu, tiêu đề, văn bản gốc và 400 ký tự đầu tiên của văn bản chính được sử dụng. Chúng được chia thành các từ đơn liên quan đến việc phát hiện xu hướng và được thêm vào chỉ số Hivemind. Văn bản chính thường chứa nội dung chính của bài viết, loại bỏ các phần lặp đi lặp lại hoặc phổ biến (boilerplate).
- Half Hours since epoch (TEHH): Đây là một đơn vị thời gian được biểu diễn dưới dạng số lượng nửa giờ kể từ thời điểm bắt đầu của thời gian Unix. Nó giúp xác định thời điểm xảy ra sự kiện với độ chính xác nửa giờ.
- Knowledge Graph Entities (RTKG): Tham chiếu đến các đối tượng trong Knowledge Graph của Google, đó là cơ sở dữ liệu về các thực thể thực tế (người, địa điểm, vật) và mối liên kết của chúng. Nó giúp làm phong phú kết quả tìm kiếm với sự hiểu biết ngữ nghĩa và bối cảnh.
- S2 Cells (S2): Tham chiếu đến các đối tượng trong Knowledge Graph của Google, đó là cơ sở dữ liệu về các thực thể thực tế (người, địa điểm, vật) và mối liên kết của chúng. Nó giúp làm phong phú kết quả tìm kiếm với sự hiểu biết ngữ nghĩa và bối cảnh.
- Freshbox Article Score (RTF): Đây là các phân vùng hình học của bề mặt Trái Đất được sử dụng cho chỉ mục hóa địa lý trong bản đồ. Chúng giúp kết nối nội dung web với các vị trí địa lý chính xác.
- Document NSR (RTN): Điều này có thể liên quan đến Độ phù hợp Tin tức của Tài liệu và dường như là một chỉ số xác định mức độ phù hợp và đáng tin cậy của một tài liệu đối với các tin tức hiện tại hoặc sự kiện đang hot. Chỉ số này cũng có thể giúp lọc bỏ nội dung chất lượng thấp hoặc spam, đảm bảo rằng các tài liệu được chỉ mục và nổi bật là chất lượng cao và quan trọng cho tìm kiếm thời gian thực.
- Kích thước Địa lý: Các đặc điểm xác định vị trí địa lý của một sự kiện hoặc chủ đề được đề cập trong tài liệu. Chúng có thể bao gồm tọa độ, tên địa điểm hoặc các định danh như S2 cells.
Nếu bạn làm việc trong ngành truyền thông, thông tin này rất quan trọng và tôi luôn bao gồm nó trong các buổi đào tạo cho biên tập viên kỹ thuật số của mình.
Tầm quan trọng của việc nhấp chuột
Trong phần này, chúng tôi sẽ tập trung vào bản trình bày nội bộ của Google được chia sẻ trong một email, có tiêu đề «Dự đoán Click Thống nhất», bản trình bày «Google là Phép màu», bản trình bày Search All Hands, một email nội bộ từ Danny Sullivan, và các tài liệu từ vụ rò rỉ «Project Veritas».
Trong suốt quá trình này, chúng ta thấy sự quan trọng cơ bản của việc nhấp chuột trong việc hiểu hành vi/nhu cầu của người dùng. Nói cách khác, Google cần dữ liệu của chúng ta. Thú vị là một trong những điều mà Google bị cấm nói về là việc nhấp chuột.

Trước khi bắt đầu, quan trọng phải lưu ý rằng các tài liệu chính được thảo luận về việc nhấp chuột trước năm 2016, và Google đã trải qua những thay đổi đáng kể kể từ đó. Mặc dù có sự tiến hóa này, cơ sở của phương pháp của họ vẫn là phân tích hành vi người dùng, coi đó là một tín hiệu chất lượng. Bạn có nhớ bằng sáng chế nơi họ giải thích mô hình CAS không?

Mỗi lần tìm kiếm và nhấp chuột của người dùng đều đóng góp vào quá trình học tập và cải tiến liên tục của Google. Vòng lặp phản hồi này cho phép Google thích nghi và "học" về sở thích và hành vi tìm kiếm, duy trì ấn tượng rằng nó hiểu được nhu cầu của người dùng.

Hàng ngày, Google phân tích hơn một tỷ hành vi mới trong một hệ thống được thiết kế để liên tục điều chỉnh và vượt qua dự đoán tương lai dựa trên dữ liệu quá khứ. Ít nhất cho đến năm 2016, điều này vượt quá khả năng của các hệ thống trí tuệ nhân tạo vào thời điểm đó, đòi hỏi công việc thủ công mà chúng ta đã thấy trước đó và cũng các điều chỉnh được thực hiện bởi RankLab.
RankLab, Tôi hiểu, là một phòng thí nghiệm kiểm tra các trọng số khác nhau trong tín hiệu và yếu tố xếp hạng, cũng như tác động sau đó của chúng. Họ cũng có thể chịu trách nhiệm cho công cụ nội bộ «Twiddler» (một điều tôi cũng đọc từ «Project Veritas» cách đây vài năm), với mục đích thay đổi thủ công điểm IR của một số kết quả cụ thể, hoặc nói cách khác, có thể thực hiện tất cả các công việc sau đây:

Sau khoảnh khắc ngắn này, tôi tiếp tục.
Mặc dù đánh giá của người đánh giá cung cấp một cái nhìn cơ bản, nhưng việc nhấp chuột cung cấp một bức tranh chi tiết hơn về hành vi tìm kiếm.


Điều này tiết lộ ra những mẫu phức tạp và cho phép học hỏi về những tác động cấp hai và cấp ba.
- Hiệu ứng cấp hai phản ánh các mẫu hiện ra: Nếu đa số thích và chọn các bài viết chi tiết hơn so với danh sách nhanh, Google sẽ phát hiện. Theo thời gian, nó sẽ điều chỉnh thuật toán để ưu tiên những bài viết chi tiết hơn trong các tìm kiếm liên quan.
- Hiệu ứng cấp ba là những thay đổi rộng lớn, lâu dài: Nếu xu hướng click ưa thích các hướng dẫn toàn diện, người tạo nội dung sẽ thích nghi. Họ sẽ bắt đầu sản xuất nhiều bài viết chi tiết hơn và ít danh sách hơn, từ đó thay đổi bản chất của nội dung có sẵn trên web.
Trong các tài liệu được phân tích, một trường hợp cụ thể được trình bày, trong đó tính liên quan của kết quả tìm kiếm được cải thiện thông qua phân tích click. Google đã xác định một sự không nhất quán trong sở thích của người dùng, dựa trên việc click, đối với một số tài liệu mà cuối cùng được xác định là liên quan, mặc dù bị bao quanh bởi một tập hợp 15.000 tài liệu được coi là không liên quan. Phát hiện này làm nổi bật tầm quan trọng của việc click của người dùng như một công cụ quý giá để phân biệt tính liên quan ẩn trong lượng lớn dữ liệu.

Google «huấn luyện với quá khứ để dự đoán tương lai» để tránh việc quá khớp. Thông qua việc đánh giá liên tục và cập nhật dữ liệu, các mô hình luôn được cập nhật và phù hợp. Một khía cạnh quan trọng của chiến lược này là cá nhân hóa địa phương, đảm bảo rằng kết quả phù hợp với các người dùng khác nhau ở các khu vực khác nhau.
Về tùy chỉnh cá nhân, trong một tài liệu gần đây hơn, Google khẳng định rằng nó bị hạn chế và hiếm khi thay đổi thứ hạng. Họ cũng đề cập rằng nó không bao giờ xuất hiện trong phần «Top Stories». Lần sử dụng nó là để hiểu rõ hơn về những gì đang được tìm kiếm, ví dụ, sử dụng ngữ cảnh của các tìm kiếm trước đó và cũng để đưa ra gợi ý dự đoán với tính năng tự động hoàn chỉnh. Họ đề cập rằng họ có thể nâng cao một nhà cung cấp video mà người dùng thường xem một chút, nhưng mọi người sẽ thấy gần như kết quả giống nhau. Theo họ, truy vấn quan trọng hơn dữ liệu người dùng.
Quan trọng phải nhớ rằng cách tiếp cận tập trung vào việc nhấp chuột này đối mặt với những thách thức, đặc biệt là với nội dung mới hoặc ít xảy ra. Đánh giá chất lượng kết quả tìm kiếm là một quá trình phức tạp vượt ra ngoài việc chỉ đếm số lần nhấp chuột. Mặc dù bài viết này của tôi đã được viết từ vài năm trước, tôi nghĩ nó có thể giúp đào sâu hơn vào vấn đề này.
Kiến trúc của Google
Theo phần trước, đây là hình ảnh tư duy mà tôi đã hình thành về cách chúng ta có thể đặt tất cả những yếu tố này trong một sơ đồ. Rất có thể rằng một số thành phần của kiến trúc của Google không ở những nơi cụ thể hoặc không liên quan như vậy, nhưng tôi tin rằng nó là đủ để xấp xỉ.
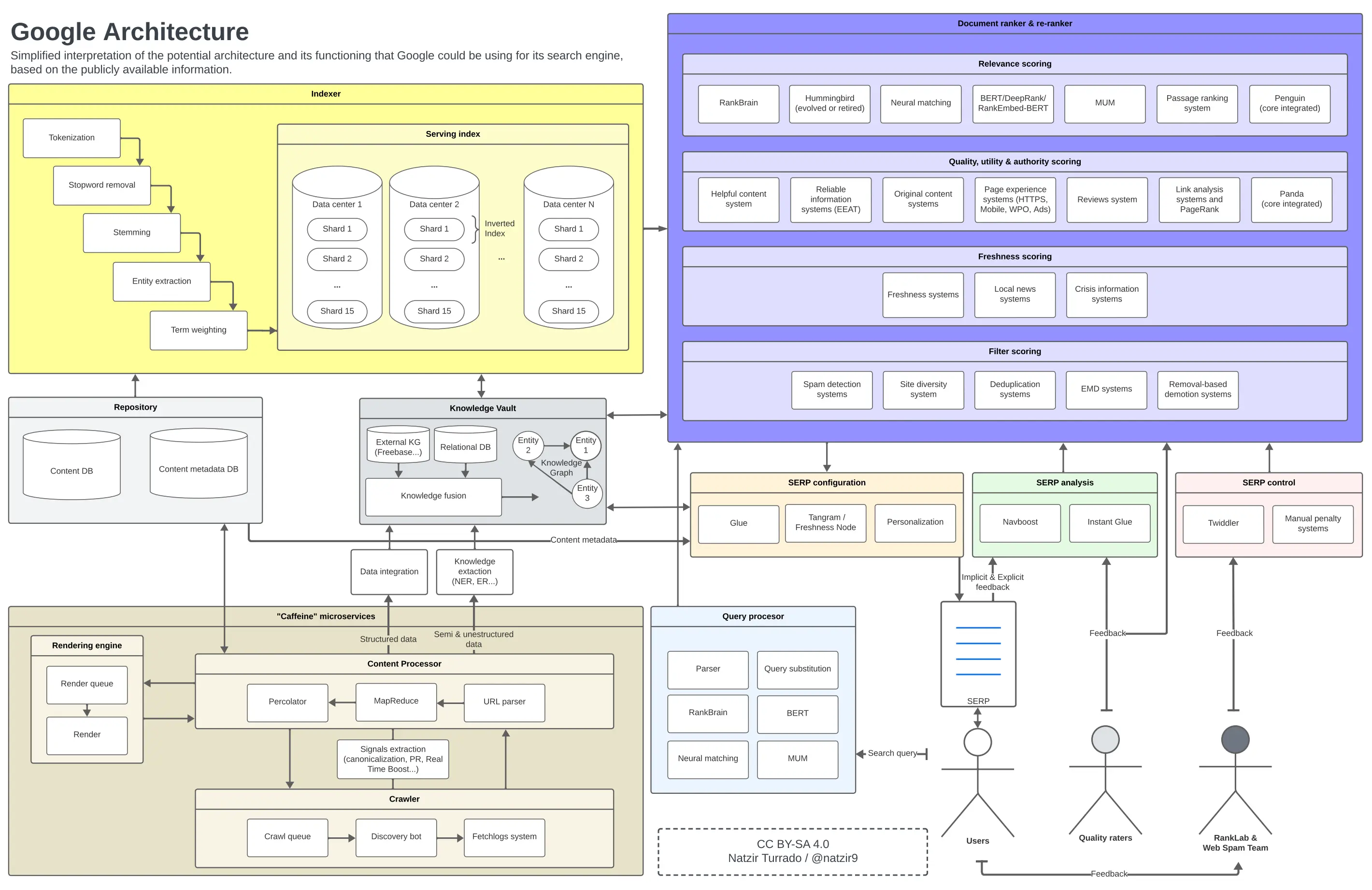
Khả năng hoạt động và kiến trúc của Google. Nhấn để phóng to hình ảnh.
Google và Chrome: Cuộc đấu tranh để trở thành công cụ tìm kiếm và trình duyệt mặc định
Trong phần cuối cùng này, chúng tôi tập trung vào lời khai của chuyên gia tư vấn Antonio Rangel, Nhà kinh tế hành vi và Giáo sư tại Caltech, về việc sử dụng tùy chọn mặc định để ảnh hưởng đến sự lựa chọn của người dùng, trong bài thuyết trình nội bộ được tiết lộ về "Giá trị chiến lược của Trang chủ Mặc định đối với Google", và trong các tuyên bố của Jim Kolotouros, Phó Chủ tịch tại Google, trong một email nội bộ.
Như Jim Kolotouros tiết lộ trong các thông tin nội bộ, Chrome không chỉ là một trình duyệt, mà còn là một phần quan trọng trong bức tranh chiếm ưu thế tìm kiếm của Google.
Trong số dữ liệu mà Google thu thập là các mẫu tìm kiếm, nhấp chuột vào kết quả tìm kiếm và tương tác với các trang web khác, điều này rất quan trọng để tinh chỉnh thuật toán của Google và cải thiện độ chính xác của kết quả tìm kiếm và hiệu quả của quảng cáo có định hướng.
Đối với Antonio Rangel, sự ưu việt của Chrome trên thị trường vượt xa sự phổ biến của nó. Nó hoạt động như một cổng vào hệ sinh thái của Google, ảnh hưởng đến cách người dùng truy cập thông tin và dịch vụ trực tuyến. Việc tích hợp của Chrome với Google Search, là công cụ tìm kiếm mặc định, mang lại cho Google một lợi thế đáng kể trong việc kiểm soát luồng thông tin và quảng cáo kỹ thuật số.

Mặc dù Google rất phổ biến, Bing không phải là một công cụ tìm kiếm kém hơn. Tuy nhiên, nhiều người dùng thích Google hơn do sự tiện lợi của cấu hình mặc định và các sai lầm nhận thức liên quan của nó. Trên thiết bị di động, tác động của công cụ tìm kiếm mặc định mạnh hơn do sự ma sát trong việc thay đổi chúng; cần tới 12 lần nhấp chuột để sửa đổi công cụ tìm kiếm mặc định.

Sở thích mặc định này cũng ảnh hưởng đến quyết định về quyền riêng tư của người tiêu dùng. Cài đặt quyền riêng tư mặc định của Google tạo ra sự ma sát đáng kể đối với những người ưa thích thu thập dữ liệu hạn chế hơn. Thay đổi tùy chọn mặc định đòi hỏi nhận thức về các phương án thay thế có sẵn, học cách thực hiện các bước cần thiết để thay đổi, và triển khai, đại diện cho sự ma sát đáng kể. Ngoài ra, các sai lệch hành vi như tình trạng hiện tại và kỳ vọng mất mát khiến người dùng thiên về việc duy trì các tùy chọn mặc định của Google. Tôi giải thích tất cả điều này tốt hơn ở đây
Lời khai của Antonio Rangel trực tiếp đồng thanh với những phát hiện trong phân tích nội bộ của Google. Tài liệu tiết lộ rằng cài đặt trang chủ trình duyệt có tác động đáng kể đến thị phần của các công cụ tìm kiếm và hành vi của người dùng. Cụ thể, một tỷ lệ cao người dùng có Google làm trang chủ mặc định thực hiện 50% tìm kiếm nhiều hơn trên Google so với những người không có.

Điều này cho thấy một mối tương quan mạnh mẽ giữa trang chủ mặc định và sở thích sử dụng công cụ tìm kiếm. Ngoài ra, ảnh hưởng của cài đặt này thay đổi theo khu vực, rõ ràng hơn ở châu Âu, Trung Đông, châu Phi và Latinh, và ít hơn ở châu Á-Thái Bình Dương và Bắc Mỹ. Phân tích cũng cho thấy rằng Google ít dễ bị ảnh hưởng bởi thay đổi trong cài đặt trang chủ so với các đối thủ như Yahoo và MSN, có thể gánh chịu tổn thất đáng kể nếu họ mất cài đặt này.

Thiết lập trang chủ được xác định là một công cụ chiến lược chính cho Google, không chỉ để duy trì thị phần của mình mà còn là một điểm yếu tiềm ẩn đối với các đối thủ. Ngoài ra, điều này nhấn mạnh rằng hầu hết người dùng không chủ động chọn một công cụ tìm kiếm, mà họ chọn theo mặc định được cung cấp bởi thiết lập trang chủ. Trong thuật ngữ kinh tế, ước tính giá trị sinh mệnh tăng thêm khoảng 3 đô la cho mỗi người dùng được đặt làm trang chủ cho Google.

Kết luận
Sau khi khám phá thuật toán và cách hoạt động nội bộ của Google, chúng tôi đã nhận thấy vai trò quan trọng của việc người dùng nhấp chuột và các người đánh giá đóng trong việc xếp hạng kết quả tìm kiếm.
Clicks, như là chỉ số trực tiếp của sở thích của người dùng, là rất quan trọng đối với Google để liên tục điều chỉnh và cải thiện tính liên quan và độ chính xác của các phản hồi của mình. Mặc dù đôi khi họ có thể muốn điều ngược lại khi số liệu không khớp...
Ngoài ra, người đánh giá đóng góp một tầng lớp quan trọng trong việc đánh giá và hiểu biết, mà ngay cả trong thời đại của trí tuệ nhân tạo, vẫn còn không thể thiếu. Cá nhân tôi rất ngạc nhiên ở điểm này, khi biết rằng người đánh giá quan trọng, nhưng không đến mức này.
Hai đầu vào này kết hợp, phản hồi tự động thông qua những cú nhấp và sự giám sát của con người, cho phép Google không chỉ hiểu tốt hơn các truy vấn tìm kiếm mà còn thích nghi với các xu hướng thay đổi và nhu cầu thông tin. Khi trí tuệ nhân tạo tiến bộ, sẽ thú vị để xem Google tiếp tục cân nhắc cách cân bằng những yếu tố này để cải thiện và cá nhân hóa trải nghiệm tìm kiếm trong một hệ sinh thái luôn thay đổi với sự tập trung vào quyền riêng tư.
Mặt khác, Chrome không chỉ là một trình duyệt; nó là thành phần quan trọng của sự thống trị kỹ thuật số của họ. Sự tương hợp với Tìm kiếm Google và việc triển khai mặc định trong nhiều lĩnh vực ảnh hưởng đến động lực thị trường và toàn bộ môi trường kỹ thuật số. Chúng ta sẽ xem xét xem vụ kiện chống độc quyền kết thúc như thế nào, nhưng họ đã phải trả khoảng 10.000 triệu euro tiền phạt vì lạm dụng vị thế thống trị trong hơn 10 năm.