Neste artigo, mergulhamos nos mecanismos internos do Google, uma ferramenta que todos nós usamos diariamente, mas poucos realmente entendem. Após o recente vazamento de documentos em um processo antitruste contra o Google, temos uma oportunidade única de explorar os algoritmos do Google. Alguns desses algoritmos já eram conhecidos, mas o interessante é a informação interna que nunca havia sido compartilhada conosco.
Vamos examinar como essas tecnologias processam nossas buscas e determinam os resultados que vemos. Nesta análise, meu objetivo é fornecer uma visão clara e detalhada dos sistemas complexos por trás de cada busca no Google.
Além disso, tentarei representar a arquitetura do Google em um diagrama, levando em consideração as novas descobertas.
Primeiro, vamos nos concentrar em extrair todos os algoritmos mencionados em 2 documentos. O primeiro é sobre o testemunho de Pandu Nayak (VP da Alphabet) e o segundo é sobre o Testemunho de Refutação do Professor Douglas W. Oard, em relação às opiniões oferecidas pelo especialista do Google, Prof. Edward A. Fox, em seu relatório datado de 3 de junho de 2022. Este último documento debateu o famoso e controverso «Relatório Fox», onde o Google manipulou dados experimentais para tentar demonstrar que os dados do usuário não são tão importantes para eles.
Vou tentar explicar cada algoritmo com base em informações oficiais, se disponíveis, e depois colocar as informações extraídas do teste em uma imagem.

Navboost
É fundamental para o Google e um dos fatores mais importantes. Isso também veio à tona no vazamento de 2019 do «Project Veritas» porque Paul Haar o adicionou ao seu CV

Navboost coleta dados sobre como os usuários interagem com os resultados da pesquisa, especificamente por meio de seus cliques em diferentes consultas. Este sistema tabula cliques e utiliza algoritmos que aprendem com classificações de qualidade feitas por humanos para melhorar a classificação dos resultados. A ideia é que se um resultado for frequentemente escolhido (e avaliado positivamente) para uma consulta específica, provavelmente deveria ter uma classificação mais alta. Curiosamente, o Google experimentou muitos anos atrás a remoção do Navboost e descobriu que os resultados pioraram.

RankBrain
Lançado em 2015, RankBrain é um sistema de inteligência artificial e aprendizado de máquina do Google, essencial no processamento de resultados de pesquisa. Através do aprendizado de máquina, ele melhora continuamente sua capacidade de entender a linguagem e as intenções por trás das pesquisas e é particularmente eficaz na interpretação de consultas ambíguas ou complexas. Diz-se que se tornou o terceiro fator mais importante no ranking do Google, após conteúdo e links. Ele usa uma Unidade de Processamento Tensorial (TPU) para melhorar significativamente sua capacidade de processamento e eficiência energética.

Deduzo que QBST e Ponderação de Termos são componentes do RankBrain. Portanto, eu os incluo aqui.
QBST (Query Based Salient Terms) concentra-se nos termos mais importantes dentro de uma consulta e documentos relacionados, usando essas informações para influenciar como os resultados são classificados. Isso significa que o mecanismo de busca pode reconhecer rapidamente os aspectos mais importantes de uma consulta do usuário e priorizar resultados relevantes. Por exemplo, isso é particularmente útil para consultas ambíguas ou complexas.
No documento de testemunho, QBST é mencionado no contexto das limitações do BERT. A menção específica é que «BERT não subsume sistemas de memorização extensos como navboost, QBST, etc.» Isso significa que, embora o BERT seja altamente eficaz na compreensão e processamento da linguagem natural, ele tem certas limitações, uma das quais é sua capacidade de lidar ou substituir sistemas de memorização em larga escala como o QBST.

Ponderação de Termos ajusta a importância relativa de termos individuais dentro de uma consulta, com base na interação dos usuários com os resultados da pesquisa. Isso ajuda a determinar quão relevantes certos termos são no contexto da consulta. Essa ponderação também lida de forma eficiente com termos que são muito comuns ou muito raros no banco de dados do mecanismo de busca, equilibrando assim os resultados.

DeepRank
Vai um passo além na compreensão da linguagem natural, permitindo que o mecanismo de busca compreenda melhor a intenção e o contexto das consultas. Isso é alcançado graças ao BERT; na verdade, DeepRank é o nome interno para o BERT. Ao pré-treinar com uma grande quantidade de dados de documentos e ajustar com feedback de cliques e avaliações humanas, o DeepRank pode ajustar os resultados da pesquisa para serem mais intuitivos e relevantes para o que os usuários estão realmente procurando.

RankEmbed
RankEmbed provavelmente se concentra na tarefa de incorporar características relevantes para classificação. Embora não haja detalhes específicos sobre sua função e capacidades nos documentos, podemos inferir que é um sistema de aprendizado profundo projetado para melhorar o processo de classificação de pesquisa do Google.
RankEmbed-BERT
RankEmbed-BERT é uma versão aprimorada do RankEmbed, integrando o algoritmo e a estrutura do BERT. Essa integração foi realizada para melhorar significativamente as capacidades de compreensão de linguagem do RankEmbed. Sua eficácia pode diminuir se não for retreinado com dados recentes. Para seu treinamento, ele usa apenas uma pequena fração do tráfego, indicando que não é necessário usar todos os dados disponíveis.
RankEmbed-BERT contribui, juntamente com outros modelos de aprendizado profundo, como RankBrain e DeepRank, para a pontuação final de classificação no sistema de busca do Google, mas operaria após a recuperação inicial dos resultados (reclassificação). Ele é treinado com base em dados de cliques e consultas, e ajustado com precisão usando dados de avaliadores humanos (IS), sendo mais caro computacionalmente para treinar do que modelos feedforward, como o RankBrain.

MÃE
É aproximadamente 1.000 vezes mais poderoso do que BERT e representa um avanço significativo na pesquisa do Google. Lançado em junho de 2021, ele não apenas compreende 75 idiomas, mas também é multimodal, o que significa que pode interpretar e processar informações em diferentes formatos. Essa capacidade multimodal permite que o MUM ofereça respostas mais abrangentes e contextuais, reduzindo a necessidade de várias pesquisas para obter informações detalhadas. No entanto, seu uso é muito seletivo devido à sua alta demanda computacional.

Tangram e Cola
Todos esses sistemas trabalham juntos dentro do framework do Tangram, que é responsável por montar a SERP com dados do Glue. Isso não se resume apenas a classificar os resultados, mas organizá-los de forma útil e acessível aos usuários, considerando elementos como carrosséis de imagens, respostas diretas e outros elementos não textuais.

Finalmente, Freshness Node e Instant Glue garantem que os resultados estão atualizados, dando mais peso às informações recentes, o que é especialmente crucial em pesquisas sobre notícias ou eventos atuais.

No julgamento, eles fazem referência ao ataque em Nice, onde o principal objetivo da consulta mudou no dia do ataque, levando o Instant Glue a suprimir imagens gerais para Tangram e, em vez disso, promover notícias relevantes e fotografias de Nice («nice pictures» vs «Nice pictures»):

Com tudo isso, o Google combinaria esses algoritmos para:
- Compreender a consulta: Decifrar a intenção por trás das palavras e frases que os usuários inserem na barra de pesquisa.
- Determinar relevância: Classificar os resultados com base em como o conteúdo corresponde à consulta, usando sinais de interações passadas e classificações de qualidade.
- Priorizar frescor: Garantir que as informações mais recentes e relevantes subam no ranking quando for importante fazê-lo.
- Personalizar resultados: Adaptar os resultados da pesquisa não apenas à consulta, mas também ao contexto do usuário, como sua localização e o dispositivo que estão usando. Dificilmente há mais personalização do que esta aqui.
Até agora, acredito que Tangram, Glue e RankEmbed-BERT são os únicos itens inéditos vazados até o momento.
Como vimos, esses algoritmos são alimentados por várias métricas que agora vamos analisar detalhadamente, mais uma vez, extraindo informações do teste.
Métricas Usadas pelo Google para Avaliar a Qualidade da Pesquisa
Nesta seção, vamos nos concentrar novamente no Testemunho de Refutação do Professor Douglas W. Oard e incluir informações de um vazamento anterior, o vazamento do «Project Veritas».
Em um dos slides, foi mostrado que o Google usa as seguintes métricas para desenvolver e ajustar os fatores que seu algoritmo considera ao classificar os resultados da pesquisa e para monitorar como as mudanças em seu algoritmo afetam a qualidade dos resultados da pesquisa. O objetivo é tentar capturar a intenção do usuário com elas.
1. Pontuação IS
Os avaliadores humanos desempenham um papel crucial no desenvolvimento e refinamento dos produtos de busca do Google. Através de seu trabalho, a métrica conhecida como «pontuação IS» (Pontuação de Satisfação da Informação variando de 0 a 100) é gerada, derivada das avaliações dos avaliadores e usada como um indicador primário de qualidade no Google.
É avaliado de forma anônima, onde os avaliadores não sabem se estão testando o Google ou o Bing, e é usado para comparar o desempenho do Google com seu principal concorrente.
Essas pontuações de IS não apenas refletem a qualidade percebida, mas também são usadas para treinar vários modelos dentro do sistema de busca do Google, incluindo algoritmos de classificação como RankBrain e RankEmbed BERT.
De acordo com os documentos, até 2021, eles estão usando IS4. IS4 é considerado uma aproximação de utilidade para o usuário e deve ser tratado como tal. É descrito como possivelmente a métrica de classificação mais importante, mas eles enfatizam que é uma aproximação e propenso a erros que discutiremos mais tarde.

Uma derivada desta métrica, o IS4@5, também é mencionada.
A métrica IS4@5 é usada pelo Google para medir a qualidade dos resultados de pesquisa, focando especificamente nas primeiras cinco posições. Esta métrica inclui tanto recursos especiais de pesquisa, como OneBoxes (conhecidos como «links azuis»). Existe uma variante desta métrica, chamada IS4@5 web, que se concentra exclusivamente na avaliação dos primeiros cinco resultados da web, excluindo outros elementos como publicidade nos resultados da pesquisa.

Embora o IS4@5 seja útil para avaliar rapidamente a qualidade e relevância dos principais resultados em uma pesquisa, seu escopo é limitado. Ele não abrange todos os aspectos da qualidade da pesquisa, especialmente omitindo elementos como publicidade nos resultados. Portanto, a métrica fornece uma visão parcial da qualidade da pesquisa. Para uma avaliação completa e precisa da qualidade dos resultados de pesquisa do Google, é necessário considerar uma gama mais ampla de métricas e fatores, semelhante à forma como a saúde geral é avaliada por meio de uma variedade de indicadores e não apenas pelo peso.
**Limitações dos Avaliadores Humanos
Os avaliadores enfrentam vários problemas, como entender consultas técnicas ou julgar a popularidade de produtos ou interpretações de consultas. Além disso, modelos de linguagem como o MUM podem vir a entender a linguagem e o conhecimento global de forma semelhante aos avaliadores humanos, apresentando tanto oportunidades quanto desafios para o futuro da avaliação de relevância.
Apesar de sua importância, sua perspectiva difere significativamente da dos usuários reais. Os avaliadores podem não ter conhecimento específico ou experiências anteriores que os usuários possam ter em relação a um tópico de consulta, potencialmente influenciando sua avaliação de relevância e a qualidade dos resultados da pesquisa.
A partir de documentos vazados de 2018 e 2021, consegui compilar uma lista de todos os erros que o Google reconhece que eles têm em suas apresentações internas.
- Discrepâncias Temporais: Discrepâncias podem ocorrer porque as consultas, avaliações e documentos podem ser de tempos diferentes, levando a avaliações que não refletem com precisão a relevância atual dos documentos.
- Reutilização de Avaliações: A prática de reutilizar avaliações para avaliar rapidamente e controlar custos pode resultar em avaliações que não são representativas da atual frescura ou relevância do conteúdo.
- Compreensão de Consultas Técnicas: Os avaliadores podem não entender consultas técnicas, levando a dificuldades na avaliação da relevância de tópicos especializados ou de nicho.
- Avaliação de Popularidade: Existe uma dificuldade inerente para os avaliadores em julgar a popularidade entre interpretações de consultas competitivas ou produtos concorrentes, o que poderia afetar a precisão de suas avaliações.
- Diversidade de Avaliadores: A falta de diversidade entre os avaliadores em algumas localidades, e o fato de que todos são adultos, não reflete a diversidade da base de usuários do Google, que inclui menores de idade.
- Conteúdo Gerado pelo Usuário: Os avaliadores tendem a ser rigorosos com o conteúdo gerado pelo usuário, o que pode levar a subestimar seu valor e relevância, apesar de ser útil e relevante.
- Treinamento do Nó de Frescor: Eles sinalizam um problema com a afinação dos modelos de frescor devido à falta de rótulos de treinamento adequados. Os avaliadores humanos muitas vezes não prestam atenção suficiente ao aspecto de frescor da relevância ou não têm o contexto temporal para a consulta. Isso resulta na subvalorização de resultados recentes para consultas que buscam novidade. O Tangram Utility existente, baseado em IS e usado para treinar Curvas de Relevância e outras pontuações, sofreu do mesmo problema. Devido à limitação de rótulos humanos, as curvas de pontuação do Nó de Frescor foram ajustadas manualmente em seu primeiro lançamento.
Eu sinceramente acredito que os avaliadores humanos têm sido responsáveis pelo funcionamento eficaz do «Parasite SEO», algo que finalmente chamou a atenção de Danny Sullivan e é compartilhado neste tweet:

Se olharmos para as mudanças nas últimas diretrizes de qualidade, podemos ver como finalmente ajustaram a definição das métricas de Atendimento às Necessidades e incluíram um novo exemplo para os avaliadores considerarem, mesmo que um resultado seja autoritativo, se não contiver as informações que o usuário está procurando, não deve ser classificado como altamente.

O novo lançamento do Google Notes, eu acredito, também aponta para essa razão. O Google é incapaz de saber com 100% de certeza o que constitui conteúdo de qualidade.

Acredito que esses eventos que estou discutindo, que ocorreram quase simultaneamente, não são uma coincidência e em breve veremos mudanças.
2. PQ (Page Quality)
Aqui deduzo que estão falando sobre a Qualidade da Página, então esta é a minha interpretação. Se for o caso, não há nada nos documentos do julgamento além da menção como métrica utilizada. A única coisa oficial que tenho que menciona PQ é do Search Quality Rater Guidelines, que muda ao longo do tempo. Portanto, seria mais uma tarefa para os avaliadores humanos.

Esta informação também é enviada para os algoritmos para criar modelos. Aqui podemos ver uma proposta disso vazada no «Project Veritas»:

Um ponto interessante aqui, de acordo com os documentos, os avaliadores de qualidade avaliam apenas páginas em dispositivos móveis.

3. Lado a lado
Isso provavelmente se refere a testes nos quais dois conjuntos de resultados de pesquisa são colocados lado a lado para que os avaliadores possam comparar sua qualidade relativa. Isso ajuda a determinar qual conjunto de resultados é mais relevante ou útil para uma determinada consulta de pesquisa. Se for o caso, lembro que o Google tinha sua própria ferramenta para download, o sxse.

A ferramenta permite aos usuários votar no conjunto de resultados de pesquisa que preferem, fornecendo assim um feedback direto sobre a eficácia de diferentes ajustes ou versões dos sistemas de busca.
4. Experimentos ao Vivo
A informação oficial publicada em Como a Pesquisa Funciona diz que o Google realiza experimentos com tráfego real para testar como as pessoas interagem com um novo recurso antes de disponibilizá-lo para todos. Eles ativam o recurso para uma pequena porcentagem de usuários e comparam seu comportamento com um grupo de controle que não possui o recurso. Métricas detalhadas sobre a interação do usuário com os resultados da pesquisa incluem:
- Clicar nos resultados
- Número de pesquisas realizadas
- Abandono de consulta
- Quanto tempo levou para as pessoas clicarem em um resultado
Estes dados ajudam a medir se a interação com a nova funcionalidade é positiva e garantem que as mudanças aumentem a relevância e a utilidade dos resultados da pesquisa.
Mas os documentos do julgamento destacam apenas duas métricas:

- Cliques longos ponderados pela posição: Esta métrica consideraria a duração dos cliques e sua posição na página de resultados, refletindo a satisfação do usuário com os resultados que encontram. 2. Atenção: Isso poderia implicar medir o tempo gasto na página, dando uma ideia de quanto tempo os usuários estão interagindo com os resultados e seu conteúdo.
Além disso, no depoimento de Pandu Nayak, é explicado que eles realizam inúmeros testes de algoritmo usando intercalação em vez de testes A/B tradicionais. Isso lhes permite realizar experimentos rápidos e confiáveis, possibilitando assim a interpretação de flutuações nas classificações.
5. Frescor
A frescura é um aspecto crucial tanto dos resultados quanto das Funcionalidades de Pesquisa. É essencial mostrar informações relevantes assim que estiverem disponíveis e parar de exibir conteúdo quando se tornar desatualizado.
Para que os algoritmos de classificação exibam documentos recentes na SERP, os sistemas de indexação e servidores devem ser capazes de descobrir, indexar e servir documentos recentes com latência muito baixa. Embora idealmente, todo o índice estivesse o mais atualizado possível, existem restrições técnicas e de custo que impedem a indexação de todos os documentos com baixa latência. O sistema de indexação prioriza documentos em caminhos separados, oferecendo diferentes compensações entre latência, custo e qualidade.
Existe o risco de que conteúdo muito recente tenha sua relevância subestimada e, inversamente, que conteúdo com muitas evidências de relevância se torne menos relevante devido a uma mudança no significado da consulta.

O papel do Nó de Frescor é adicionar correções às pontuações desatualizadas. Para consultas em busca de conteúdo fresco, ele promove conteúdo fresco e degrada conteúdo desatualizado.
Não faz muito tempo, vazou a informação de que o Google Caffeine não existe mais (também conhecido como o sistema de indexação baseado no Percolator). Embora internamente o nome antigo ainda seja usado, o que existe agora é na verdade um sistema completamente novo. O novo «cafeína» é na verdade um conjunto de microsserviços que se comunicam entre si. Isso implica que diferentes partes do sistema de indexação operam como serviços independentes, mas interconectados, cada um realizando uma função específica. Essa estrutura pode oferecer maior flexibilidade, escalabilidade e facilidade para realizar atualizações e melhorias.
Ao interpretar parte desses microsserviços, seriam Tangram e Glue, especificamente o Nó de Frescor e a Cola Instantânea. Digo isso porque em outro documento vazado do «Project Veritas» descobri que houve uma proposta de 2016 para criar ou incorporar um «Impulso de Navegação Instantânea» como sinal de Frescor, assim como visitas ao Chrome.

Até agora, eles já haviam incorporado «Freshdocs-instant» (extraído de uma lista de pubsub chamada freshdocs-instant-docs pubsub, onde eles pegaram as notícias publicadas por esses meios dentro de 1 minuto de sua publicação) e picos de busca e correlações de geração de conteúdo:

Dentro das métricas de Frescor, temos várias que são detectadas graças à análise de Ngramas Correlacionados e Termos Salientes Correlacionados:
- NGramas Correlacionados: Estes são grupos de palavras que aparecem juntas em um padrão estatisticamente significativo. A correlação pode aumentar repentinamente durante um evento ou tópico em tendência, indicando um pico. 2. Termos Salientes Correlacionados: Estes são termos destacados que estão intimamente associados a um tópico ou evento e cuja frequência de ocorrência aumenta em documentos ao longo de um curto período, sugerindo um pico de interesse ou atividade relacionada.
Uma vez que os picos são detectados, as seguintes métricas de Atualização podem estar sendo usadas:
- Unigramas (RTW): Para cada documento, o título, textos âncora e os primeiros 400 caracteres do texto principal são usados. Eles são divididos em unigramas relevantes para detecção de tendências e adicionados ao índice Hivemind. O texto principal geralmente contém o conteúdo principal do artigo, excluindo elementos repetitivos ou comuns (boilerplate).
- Meias horas desde o início da época (TEHH): Esta é uma medida de tempo expressa como o número de meias horas desde o início do tempo Unix. Isso ajuda a estabelecer quando algo aconteceu com precisão de meia hora.
- Entidades do Knowledge Graph (RTKG): Referências a objetos no Knowledge Graph do Google, que é um banco de dados de entidades reais (pessoas, lugares, coisas) e suas interconexões. Isso ajuda a enriquecer a pesquisa com compreensão semântica e contexto.
- Células S2 (S2): Referências a objetos no Knowledge Graph do Google, que é um banco de dados de entidades reais (pessoas, lugares, coisas) e suas interconexões. Isso ajuda a enriquecer a pesquisa com compreensão semântica e contexto.
- Pontuação do Artigo Freshbox (RTF): Estas são divisões geométricas da superfície da Terra usadas para indexação geográfica em mapas. Elas facilitam a associação de conteúdo da web com localizações geográficas precisas.
- NSR do Documento (RTN): Isso pode se referir à Relevância de Notícias do Documento e parece ser uma métrica que determina o quão relevante e confiável um documento é em relação a notícias atuais ou eventos em tendência. Essa métrica também pode ajudar a filtrar conteúdo de baixa qualidade ou spam, garantindo que os documentos indexados e destacados sejam de alta qualidade e significativos para pesquisas em tempo real.
- Dimensões Geográficas: Recursos que definem a localização geográfica de um evento ou tópico mencionado no documento. Estes podem incluir coordenadas, nomes de lugares ou identificadores como células S2.
Se você trabalha na mídia, esta informação é fundamental e eu sempre a incluo em meus treinamentos para editores digitais.
A Importância dos Cliques
Nesta seção, vamos nos concentrar na apresentação interna do Google compartilhada em um e-mail, intitulada «Previsão de Clique Unificado», na apresentação «Google é Mágico», na apresentação Search All Hands, em um e-mail interno de Danny Sullivan e nos documentos vazados do «Project Veritas».
Ao longo deste processo, vemos a importância fundamental dos cliques na compreensão do comportamento/necessidades do usuário. Em outras palavras, o Google precisa dos nossos dados. Curiosamente, uma das coisas que o Google foi proibido de falar foram os cliques.

Antes de começar, é importante observar que os principais documentos discutidos sobre cliques são anteriores a 2016, e o Google passou por mudanças significativas desde então. Apesar dessa evolução, a base de sua abordagem continua sendo a análise do comportamento do usuário, considerando-o um sinal de qualidade. Você se lembra da patente onde eles explicam o modelo CAS?

Cada pesquisa e clique fornecido pelos usuários contribui para a aprendizagem e melhoria contínua do Google. Esse ciclo de feedback permite ao Google se adaptar e "aprender" sobre as preferências e comportamentos de busca, mantendo a ilusão de que compreende as necessidades do usuário.

Diariamente, o Google analisa mais de um bilhão de novos comportamentos dentro de um sistema projetado para ajustar continuamente e superar previsões futuras com base em dados passados. Pelo menos até 2016, isso excedia a capacidade dos sistemas de IA na época, exigindo o trabalho manual que vimos anteriormente e também ajustes feitos pelo RankLab.
RankLab, entendo, é um laboratório que testa diferentes pesos em sinais e fatores de classificação, bem como seu impacto subsequente. Eles também podem ser responsáveis pela ferramenta interna «Twiddler» (algo que também li anos atrás do «Project Veritas»), com o propósito de modificar manualmente as pontuações de IR de certos resultados, ou em outras palavras, ser capaz de fazer o seguinte:

Após este breve interlúdio, continuo.
Enquanto as avaliações de avaliadores humanos oferecem uma visão básica, os cliques fornecem um panorama muito mais detalhado do comportamento de busca.


Isso revela padrões complexos e permite a aprendizagem de efeitos de segunda e terceira ordem.
- Efeitos de segunda ordem refletem padrões emergentes: Se a maioria prefere e escolhe artigos detalhados em vez de listas rápidas, o Google detecta. Com o tempo, ajusta seus algoritmos para priorizar esses artigos mais detalhados em pesquisas relacionadas.
- Efeitos de terceira ordem são mudanças mais amplas e de longo prazo: Se as tendências de cliques favorecem guias abrangentes, os criadores de conteúdo se adaptam. Eles começam a produzir mais artigos detalhados e menos listas, alterando assim a natureza do conteúdo disponível na web.
Nos documentos analisados, é apresentado um caso específico em que a relevância dos resultados da pesquisa foi melhorada por meio da análise de cliques. O Google identificou uma discrepância na preferência do usuário, com base nos cliques, em relação a alguns documentos que se revelaram relevantes, apesar de estarem cercados por um conjunto de 15.000 documentos considerados irrelevantes. Essa descoberta destaca a importância dos cliques do usuário como uma ferramenta valiosa para discernir a relevância oculta em grandes volumes de dados.

Google «treina com o passado para prever o futuro» para evitar overfitting. Através de avaliações constantes e atualização de dados, os modelos permanecem atuais e relevantes. Um aspecto chave dessa estratégia é a personalização da localização, garantindo que os resultados sejam pertinentes para diferentes usuários em várias regiões.
Em relação à personalização, em um documento mais recente, o Google afirma que é limitada e raramente altera as classificações. Eles também mencionam que nunca ocorre em «Principais notícias». As vezes em que é usada é para entender melhor o que está sendo procurado, por exemplo, usando o contexto de pesquisas anteriores e também para fazer sugestões preditivas com o autocompletar. Eles mencionam que podem elevar ligeiramente um provedor de vídeos que o usuário usa com frequência, mas todos veriam basicamente os mesmos resultados. Segundo eles, a consulta é mais importante do que os dados do usuário.
É importante lembrar que essa abordagem focada em cliques enfrenta desafios, especialmente com conteúdo novo ou pouco frequente. Avaliar a qualidade dos resultados de pesquisa é um processo complexo que vai além de apenas contar cliques. Embora este artigo que escrevi tenha vários anos, acredito que pode ajudar a aprofundar-se nisso.
Arquitetura do Google
Seguindo a seção anterior, esta é a imagem mental que eu formei de como poderíamos colocar todos esses elementos em um diagrama. É muito provável que alguns componentes da arquitetura do Google não estejam em determinados lugares ou não se relacionem como tal, mas acredito que é mais do que suficiente como uma aproximação.
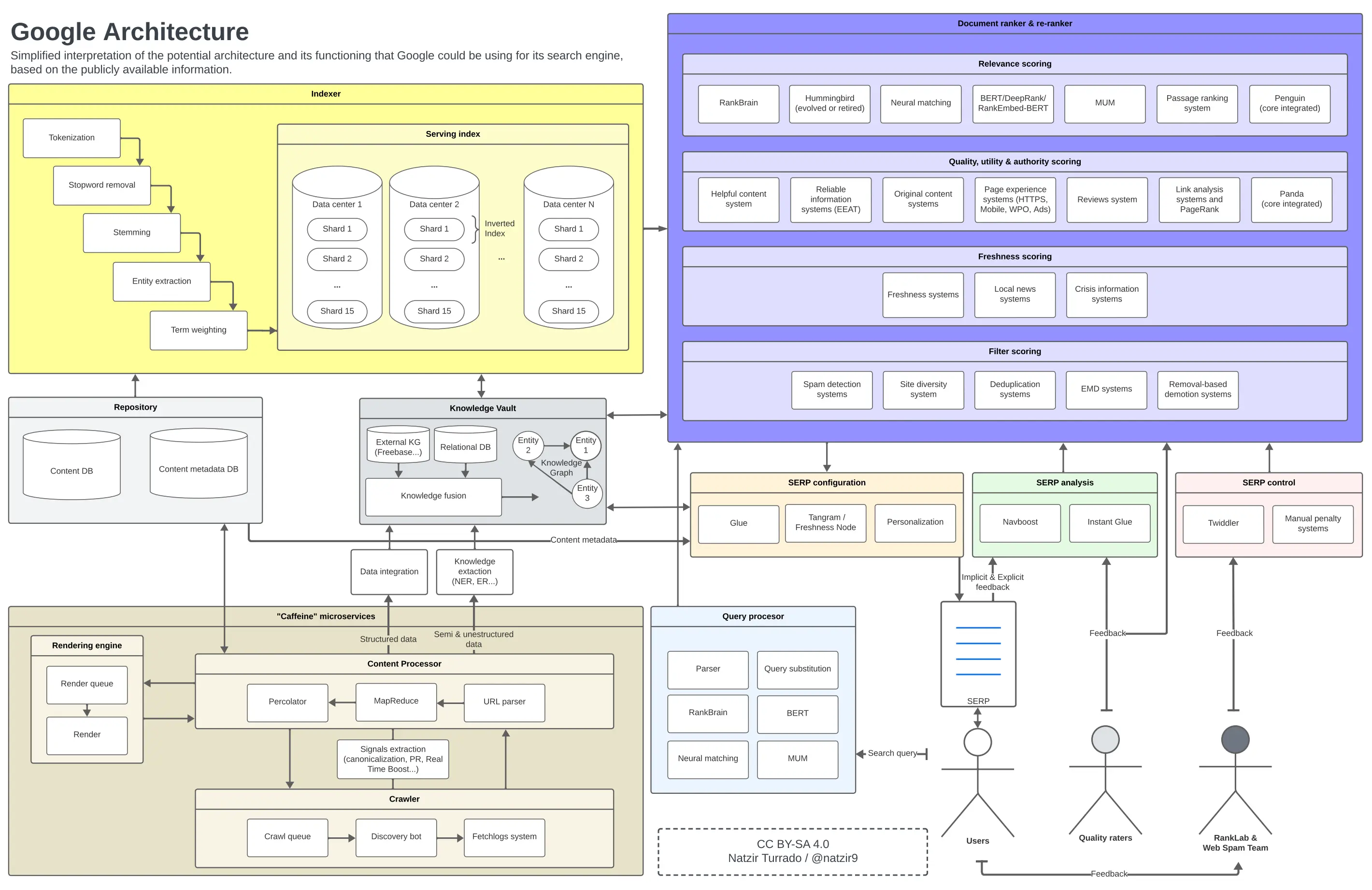
Possível funcionamento e arquitetura do Google. Clique para ampliar a imagem.
Google e Chrome: A Luta para Ser o Motor de Busca e Navegador Padrão
Nesta última seção, focamos no testemunho do especialista Antonio Rangel, Economista Comportamental e Professor da Caltech, sobre o uso de opções padrão para influenciar as escolhas do usuário, na apresentação interna revelada «Sobre o Valor Estratégico da Página Inicial Padrão para o Google», e em declarações de Jim Kolotouros, VP do Google, em um e-mail interno
Como Jim Kolotouros revela em comunicações internas, o Chrome não é apenas um navegador, mas uma peça-chave no quebra-cabeça de dominação da busca do Google.
Entre os dados que o Google coleta estão os padrões de busca, cliques nos resultados de busca e interações com diferentes sites, o que é crucial para refinar os algoritmos do Google e melhorar a precisão dos resultados de busca e a eficácia da publicidade direcionada.
Para Antonio Rangel, a supremacia de mercado do Chrome transcende sua popularidade. Ele atua como um gateway para o ecossistema do Google, influenciando como os usuários acessam informações e serviços online. A integração do Chrome com a Pesquisa Google, sendo o mecanismo de busca padrão, concede ao Google uma vantagem significativa no controle do fluxo de informações e publicidade digital.

Apesar da popularidade do Google, o Bing não é um mecanismo de busca inferior. No entanto, muitos usuários preferem o Google devido à conveniência de sua configuração padrão e aos vieses cognitivos associados. Em dispositivos móveis, os efeitos dos mecanismos de busca padrão são mais fortes devido ao atrito envolvido em alterá-los; são necessários até 12 cliques para modificar o mecanismo de busca padrão.

Essa preferência padrão também influencia as decisões de privacidade do consumidor. As configurações padrão de privacidade do Google apresentam fricção significativa para aqueles que preferem uma coleta de dados mais limitada. Alterar a opção padrão requer consciência das alternativas disponíveis, aprender as etapas necessárias para a mudança e implementação, representando uma fricção considerável. Além disso, vieses comportamentais como status quo e aversão à perda fazem com que os usuários tendam a manter as opções padrão do Google. Eu explico tudo isso melhor aqui.
O testemunho de Antonio Rangel ressoa diretamente com as revelações da análise interna do Google. O documento revela que a configuração da página inicial do navegador tem um impacto significativo na participação de mercado dos mecanismos de busca e no comportamento do usuário. Especificamente, um alto percentual de usuários que têm o Google como página inicial padrão realizam 50% mais buscas no Google do que aqueles que não o têm.

Isso sugere uma forte correlação entre a página inicial padrão e a preferência do mecanismo de busca. Além disso, a influência dessa configuração varia regionalmente, sendo mais pronunciada na Europa, Oriente Médio, África e América Latina, e menos na Ásia-Pacífico e América do Norte. A análise também mostra que o Google é menos vulnerável a mudanças na configuração da página inicial em comparação com concorrentes como o Yahoo e o MSN, que poderiam sofrer perdas significativas se perderem essa configuração.

A configuração da página inicial é identificada como uma ferramenta estratégica chave para o Google, não apenas para manter sua participação de mercado, mas também como uma vulnerabilidade potencial para seus concorrentes. Além disso, destaca que a maioria dos usuários não escolhe ativamente um mecanismo de busca, mas tende a usar o acesso padrão fornecido pela configuração de sua página inicial. Em termos econômicos, um valor vitalício incremental de aproximadamente $3 por usuário é estimado para o Google quando definido como a página inicial.

Conclusão
Após explorar os algoritmos e funcionamento interno do Google, vimos o papel significativo que os cliques dos usuários e os avaliadores humanos desempenham na classificação dos resultados de pesquisa.
Cliques, como indicadores diretos das preferências do usuário, são essenciais para o Google ajustar e melhorar continuamente a relevância e precisão de suas respostas. Embora às vezes eles possam querer o oposto quando os números não se encaixam...
Além disso, os avaliadores humanos contribuem com uma camada crucial de avaliação e compreensão que, mesmo na era da inteligência artificial, continua sendo indispensável. Pessoalmente, estou muito surpreso neste ponto, sabendo que os avaliadores eram importantes, mas não a esse ponto.
Essas duas entradas combinadas, feedback automático por meio de cliques e supervisão humana, permitem que o Google não apenas compreenda melhor as consultas de pesquisa, mas também se adapte às tendências e necessidades de informação em constante mudança. À medida que a IA avança, será interessante ver como o Google continua a equilibrar esses elementos para melhorar e personalizar a experiência de pesquisa em um ecossistema em constante mudança, com foco na privacidade.
Por outro lado, o Chrome é muito mais do que um navegador; é o componente crítico de sua dominação digital. Sua sinergia com a Pesquisa Google e sua implementação padrão em muitas áreas impactam a dinâmica do mercado e todo o ambiente digital. Veremos como termina o julgamento antitruste, mas eles têm passado mais de 10 anos sem pagar cerca de 10.000 milhões de euros em multas por abuso de posição dominante.