Recuperação Aumentada Geração (RAG) é um termo sobrecarregado. Promete o mundo, mas depois de desenvolver um pipeline RAG, muitos de nós ficam se perguntando por que não funciona tão bem quanto esperávamos.
Como acontece com a maioria das ferramentas, RAG é fácil de usar, mas difícil de dominar. A verdade é que há mais no RAG do que colocar documentos em um banco de vetores e adicionar um LLM por cima. Isso pode funcionar, mas nem sempre.
Este ebook tem como objetivo dizer-lhe o que fazer quando o RAG padrão não funciona. Neste primeiro capítulo, vamos ver qual é frequentemente a solução mais fácil e rápida de implementar para pipelines RAG subótimos — vamos aprender sobre rerankers.
Vídeo complementar para este capítulo.
Comparação entre Recuperação e Janelas de Contexto
Antes de mergulharmos na solução, vamos falar sobre o problema. Com RAG, estamos realizando uma busca semântica em muitos documentos de texto — estes podem ser dezenas de milhares até dezenas de bilhões de documentos.
Para garantir tempos de busca rápidos em escala, geralmente usamos a busca vetorial - ou seja, transformamos nosso texto em vetores, colocamos todos eles em um espaço vetorial e comparamos sua proximidade com um vetor de consulta usando uma métrica de similaridade como a similaridade de cosseno.
Para que a busca vetorial funcione, precisamos de vetores. Esses vetores são essencialmente compressões do 'significado' por trás de algum texto em vetores de (tipicamente) 768 ou 1536 dimensões. Há alguma perda de informação porque estamos comprimindo essa informação em um único vetor.
Devido a essa perda de informação, frequentemente vemos que os três principais (por exemplo) documentos de busca vetorial deixarão passar informações relevantes. Infelizmente, a recuperação pode retornar informações relevantes abaixo do nosso limite superior de k.
O que fazemos se informações relevantes em uma posição inferior ajudariam nosso LLM a formular uma resposta melhor? A abordagem mais fácil é aumentar o número de documentos que estamos retornando (aumentar o top_k) e passá-los todos para o LLM.
A métrica que mediríamos aqui é recall - significando 'quantos dos documentos relevantes estamos recuperando'. Recall não considera o número total de documentos recuperados - então podemos manipular a métrica e obter um recall perfeito retornando tudo.
recall@K = # de documentos relevantes retornados# de documentos relevantes no conjunto de dadosrecall@K = \frac{#;de;documentos;relevantes;retornados}{#;de;documentos;relevantes;no;conjunto;de;dados}
Infelizmente, não podemos retornar tudo. Os LLMs têm limites sobre a quantidade de texto que podemos passar para eles - chamamos esse limite de janela de contexto. Alguns LLMs têm janelas de contexto enormes, como o Claude da Anthropic, com uma janela de contexto de 100 mil tokens [1"]. Com isso, poderíamos incluir muitas dezenas de páginas de texto - então poderíamos retornar muitos documentos (não todos) e
Novamente, não. Não podemos usar o contexto stuffing porque isso reduz o desempenho de recall do LLM — observe que este é o recall do LLM, que é diferente do recall de recuperação que temos discutido até agora.
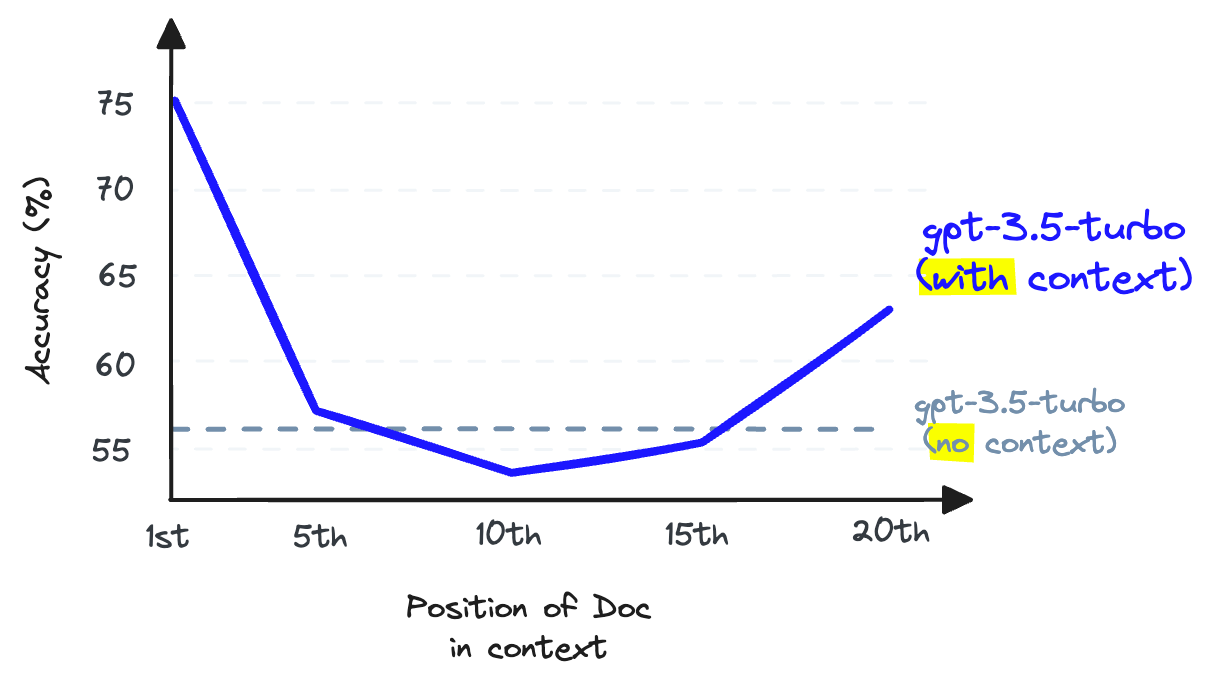
Ao armazenar informações no meio de uma janela de contexto, a capacidade de um LLM de lembrar essas informações se torna pior do que se elas não tivessem sido fornecidas em primeiro lugar [2].
O recall do LLM refere-se à capacidade de um LLM de encontrar informações do texto colocado dentro da sua janela de contexto. Pesquisas mostram que o recall do LLM degrada à medida que colocamos mais tokens na janela de contexto [2]. LLMs também são menos propensos a seguir instruções à medida que lotamos a janela de contexto — portanto, o excesso de contexto é uma má ideia.
Podemos aumentar o número de documentos retornados pelo nosso banco de vetores para aumentar a recordação de recuperação, mas não podemos passá-los para o nosso LLM sem prejudicar a recordação do LLM.
A solução para este problema é maximizar a recuperação lembrança ao recuperar muitos documentos e, em seguida, maximizar a lembrança LLM minimizando o número de documentos que chegam ao LLM. Para fazer isso, reordenamos os documentos recuperados e mantemos apenas os mais relevantes para o nosso LLM — para isso, usamos reranking.
Poder dos Rerankers
Um modelo de reclassificação - também conhecido como um cross-encoder - é um tipo de modelo que, dado um par de consulta e documento, irá produzir uma pontuação de similaridade. Usamos essa pontuação para reordenar os documentos por relevância para nossa consulta.
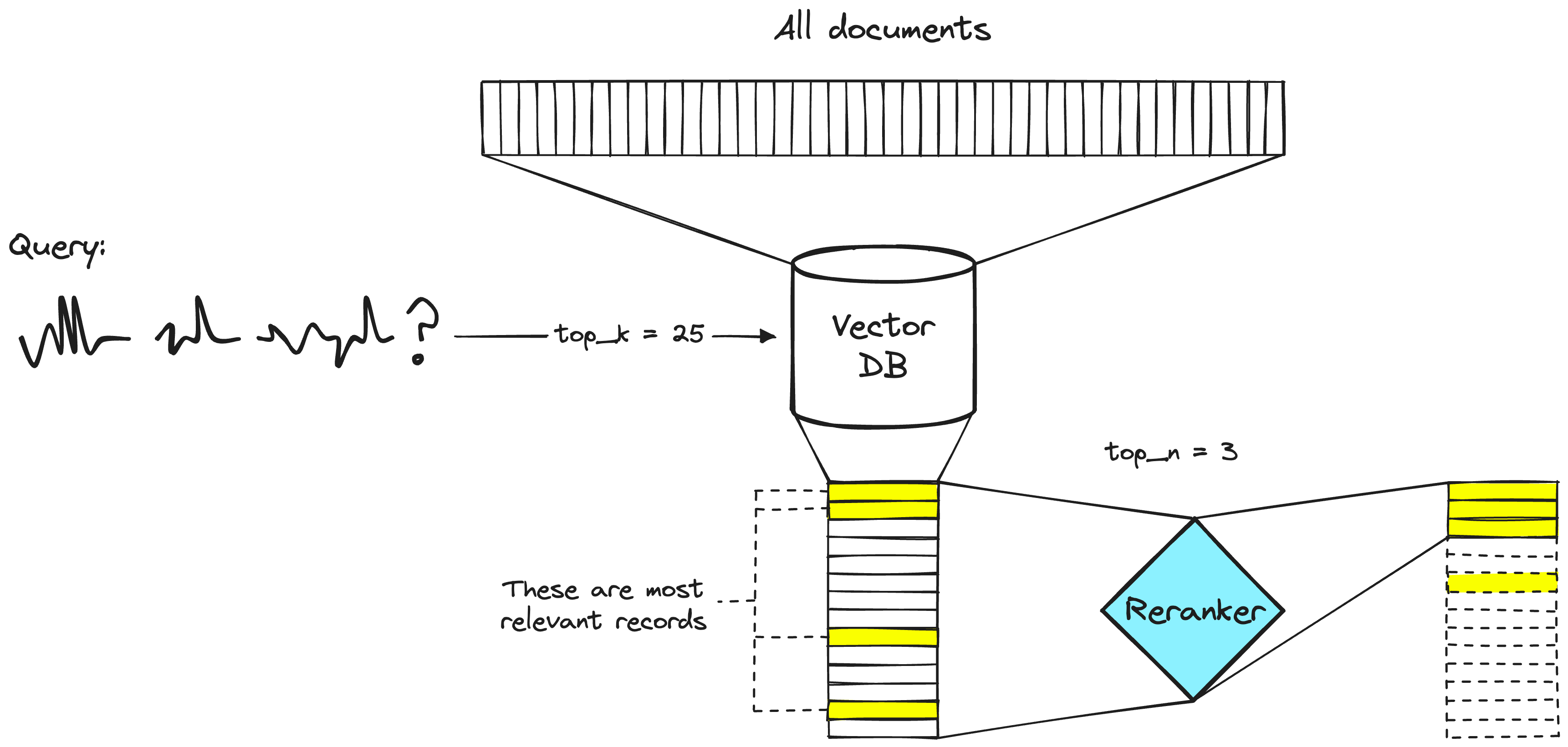
Um sistema de recuperação de duas etapas. A etapa de banco de dados vetorial normalmente incluirá um modelo de codificador duplo ou modelo de incorporação esparsa.
Engenheiros de busca têm usado rerankers em sistemas de recuperação de duas etapas há muito tempo. Nestes sistemas de duas etapas, um modelo de primeira etapa (um modelo de incorporação/recuperador) recupera um conjunto de documentos relevantes de um conjunto de dados maior. Em seguida, um modelo de segunda etapa (o reranker) é usado para reclassificar esses documentos recuperados pelo modelo de primeira etapa.
Nós usamos dois estágios porque recuperar um pequeno conjunto de documentos de um grande conjunto de dados é muito mais rápido do que reclassificar um grande conjunto de documentos - discutiremos em breve por que isso é o caso - mas resumindo, os reclassificadores são lentos e os recuperadores são rápidos.
Por que reclassificadores?
Se um reranker é tão mais lento, por que se incomodar em usá-los? A resposta é que os rerankers são muito mais precisos do que os modelos de incorporação.
A intuição por trás da precisão inferior de um bi-codificador é que os bi-codificadores precisam comprimir todos os possíveis significados de um documento em um único vetor, o que significa que perdemos informação. Além disso, os bi-codificadores não têm contexto sobre a consulta porque não conhecemos a consulta até recebê-la (criamos incorporações antes do tempo da consulta do usuário).
Por outro lado, um reranker pode receber as informações brutas diretamente na grande computação do transformador, o que significa menos perda de informação. Como estamos executando o reranker no momento da consulta do usuário, temos o benefício adicional de analisar o significado de nossos documentos específico para a consulta do usuário — em vez de tentar produzir um significado genérico e médio.
Os reclassificadores evitam a perda de informação dos bi-codificadores - mas eles vêm com uma penalidade diferente - tempo.