Este artigo é principalmente 'compilado' do Capítulo 40 do livro 'Operating Systems: Three Easy Pieces', que é um livro muito aprofundado e acessível, recomendado para todos os alunos que se sentem confusos em relação aos sistemas operacionais. Este sistema de arquivos é baseado em um espaço de disco muito pequeno, com estruturas de dados e fluxos de leitura/escrita como linha principal, derivando todos os elementos básicos do zero, o que pode ajudá-lo a estabelecer rapidamente uma intuição sobre sistemas de arquivos.
Sistemas de arquivos em sua maioria são construídos em cima de armazenamento em bloco. No entanto, alguns sistemas de arquivos distribuídos atuais, como o JuiceFS, são baseados em armazenamento de objetos. Mas, seja armazenamento em bloco ou armazenamento de objetos, ambos essencialmente realizam endereçamento e troca de dados por meio de 'blocos de dados'.
Primeiro, vamos discutir a estrutura de dados completa de um sistema de arquivos no disco rígido, ou seja, o layout; em seguida, vamos conectar os vários submódulos por meio dos processos de abertura, fechamento, leitura e escrita, a fim de cobrir os pontos principais de um sistema de arquivos.
Autor: Notas Diversas de Mu Niao https://www.qtmuniao.com/2024/02/28/mini-filesystem Por favor, mencione a fonte ao republicar
本文来自我的大规模数据系统专栏《系统日知录》,专注存储、数据库、分布式系统、AI Infra 和计算机基础知识。欢迎订阅支持,解锁更多文章。你的支持,是我前行的最大动力。

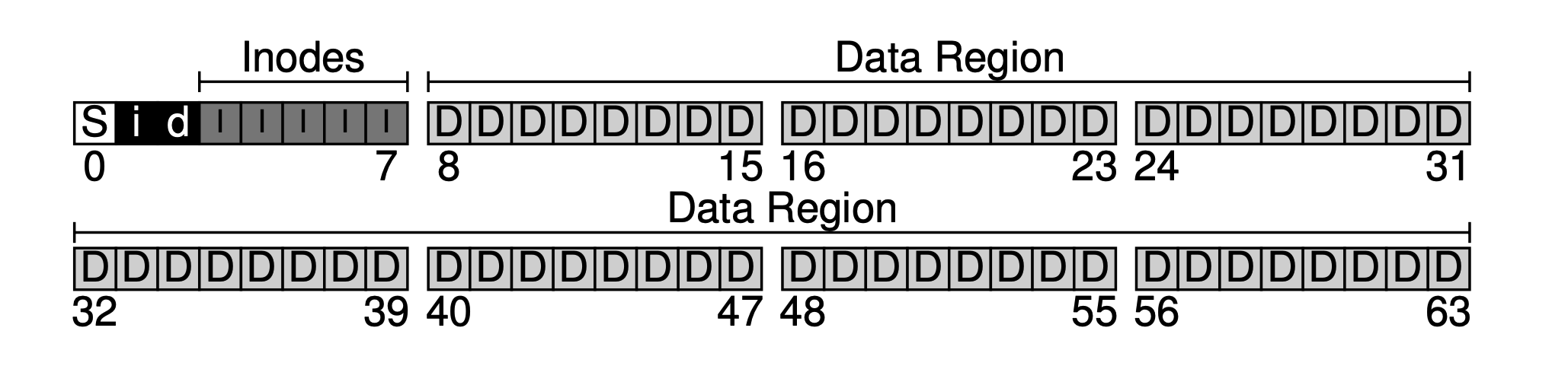
Suponha que o tamanho do nosso bloco seja 4KB, e então temos um disco muito pequeno, com apenas 64 blocos (então o tamanho total é de 64 * 4KB = 256KB), e este disco é usado apenas pelo sistema de arquivos. Como o disco é endereçado por blocos, o espaço de endereço é de 0 a 63.
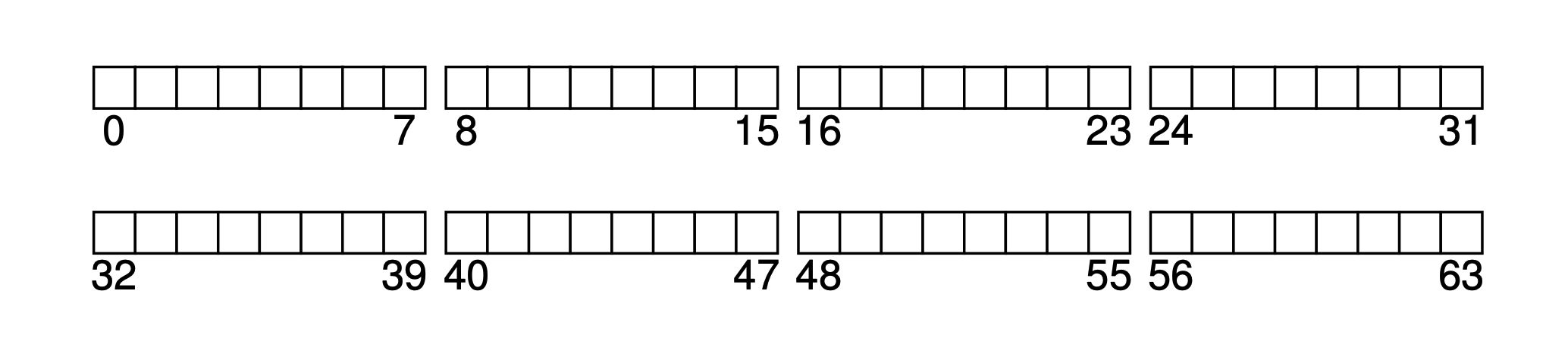
Com base nesse disco rígido miniatura, vamos juntos passo a passo deduzir este sistema de arquivos extremamente simples.
O principal objetivo de um sistema de arquivos certamente é armazenar dados do usuário, para isso reservamos uma área de dados no disco (Data Region). Suponha que estamos usando os últimos 56 blocos como a área de dados. Por que 56? Podemos calcular isso a partir dos blocos posteriores - na verdade, podemos calcular aproximadamente a proporção entre metadados e dados reais, e assim determinar o tamanho de ambas as partes.
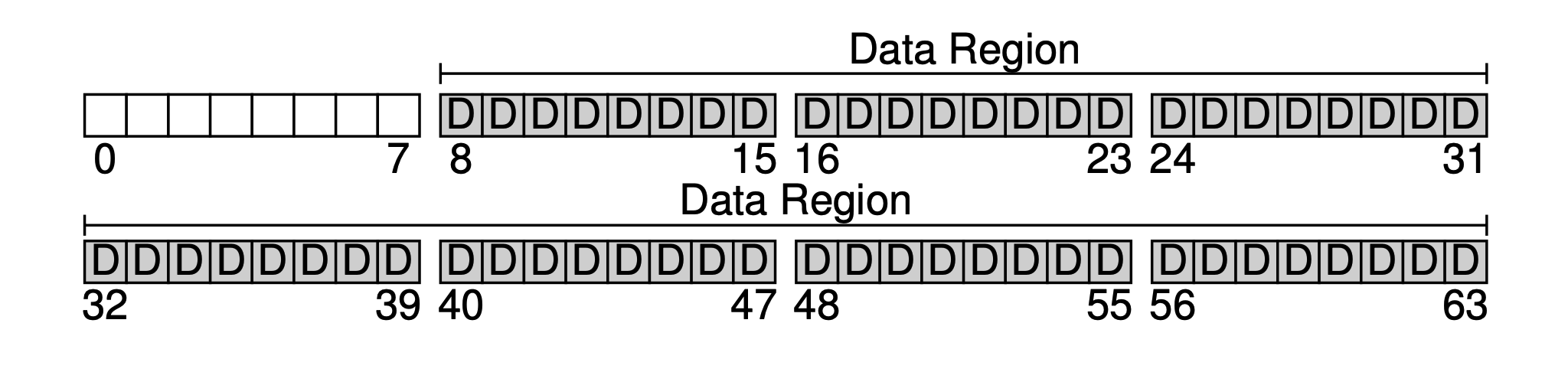
A seguir, precisamos salvar algumas metainformações para cada arquivo no sistema, como por exemplo:
- Nome do arquivo
- Tamanho do arquivo
- Proprietário do arquivo
- Permissão de acesso
- Horário de criação e modificação
Espere. O bloco de dados que armazena essas metainformações é geralmente chamado de inode (nó de índice). Aqui, atribuímos 5 blocos ao inode.
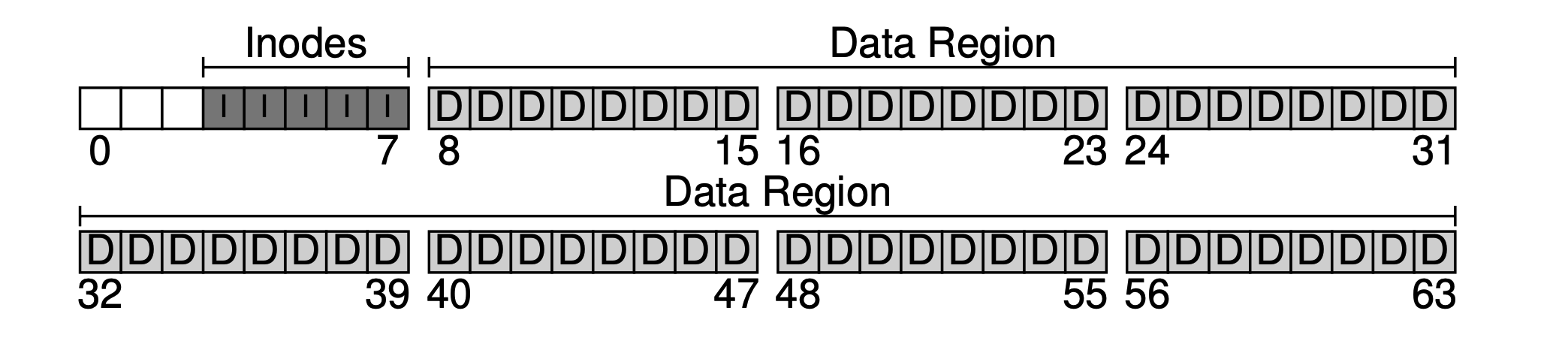
Os metadados ocupam relativamente pouco espaço, como 128B ou 256B, aqui assumimos que cada inode ocupa 256B. Então, cada bloco de 4KB pode conter 16 inodes, o que significa que nosso sistema de arquivos pode suportar no máximo 5 * 16 = 80 inodes, ou seja, nosso sistema de arquivos mínimo pode suportar no máximo 80 arquivos, mas como os diretórios também ocupam inodes, o número real de arquivos disponíveis é menor que 80.
Agora temos a área de dados e a área de metadados do arquivo, mas em um sistema de arquivos em uso normal, também precisamos rastrear quais blocos de dados estão sendo usados e quais ainda não estão sendo usados. Chamamos essa estrutura de dados de estrutura de alocação. Os métodos comuns usados na indústria incluem lista livre (free list), que encadeia todos os blocos livres em uma lista. No entanto, para simplificar, aqui usamos uma estrutura de dados mais simples: bitmap, onde a área de dados usa um bitmap, chamado de bitmap de dados; e a tabela de inode usa um, chamado de bitmap de inode.
A ideia por trás do bitmap é muito simples: usar um bit de dados para cada inode ou bloco de dados para marcar se está livre: 0 para livre, 1 para ocupado. Um bitmap de 4KB pode rastrear no máximo 32K objetos. Para conveniência, alocamos um bloco completo para o bitmap de inodes e para o pool de dados (embora não seja totalmente utilizado), como mostrado no diagrama abaixo.
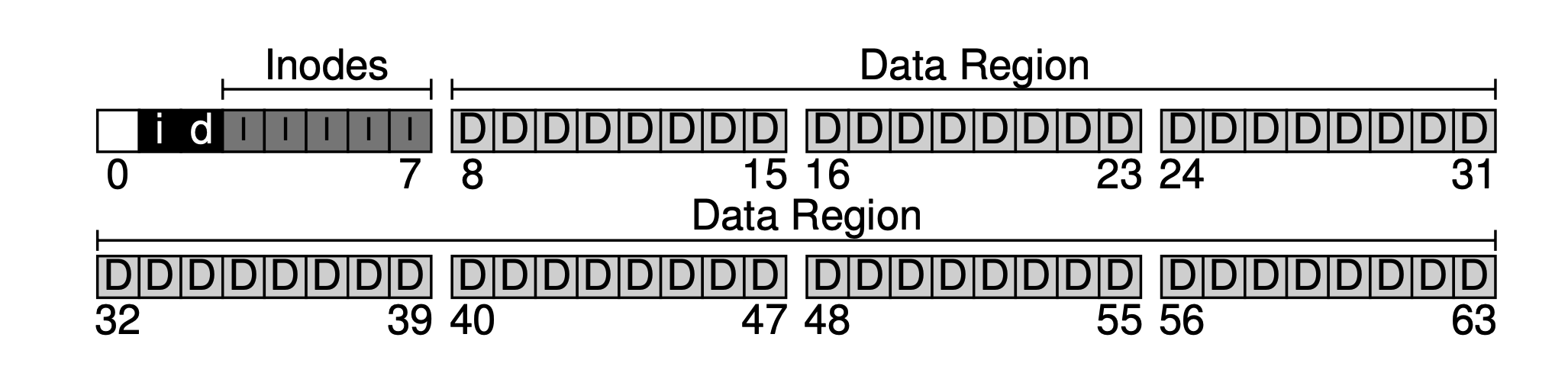
Pode-se ver que a nossa abordagem básica é organizar os dados de trás para a frente, deixando um bloco por último. Deixamos intencionalmente este bloco para servir como o superbloco do sistema de arquivos. O superbloco, como a entrada de um sistema de arquivos, geralmente armazena algumas informações de nível de sistema de arquivos, como quantos inodes e blocos de dados existem neste sistema de arquivos (80 e 56), o deslocamento inicial da tabela de inodes (3), e assim por diante.
Então, quando o sistema de arquivos é montado (mount), o sistema operacional primeiro lê o superbloco (por isso é colocado na frente), inicializa uma série de parâmetros com base nisso e monta-o como um volume de dados na árvore do sistema de arquivos. Com essas informações básicas, quando os arquivos no volume são acessados, sua localização pode ser gradualmente determinada, o que é o processo de leitura e escrita que discutiremos mais tarde.
Mas antes de falar sobre o processo de leitura e escrita, é necessário ampliar um pouco as estruturas de dados-chave para ver sua disposição interna.
inode é a abreviatura de nó de índice (index node), que é o nó de índice de arquivos e pastas. Para simplificar, usamos arrays para organizar os nós de índice, e cada inode estará associado a um número de identificação (inumber), ou seja, seu índice (deslocamento) no array.
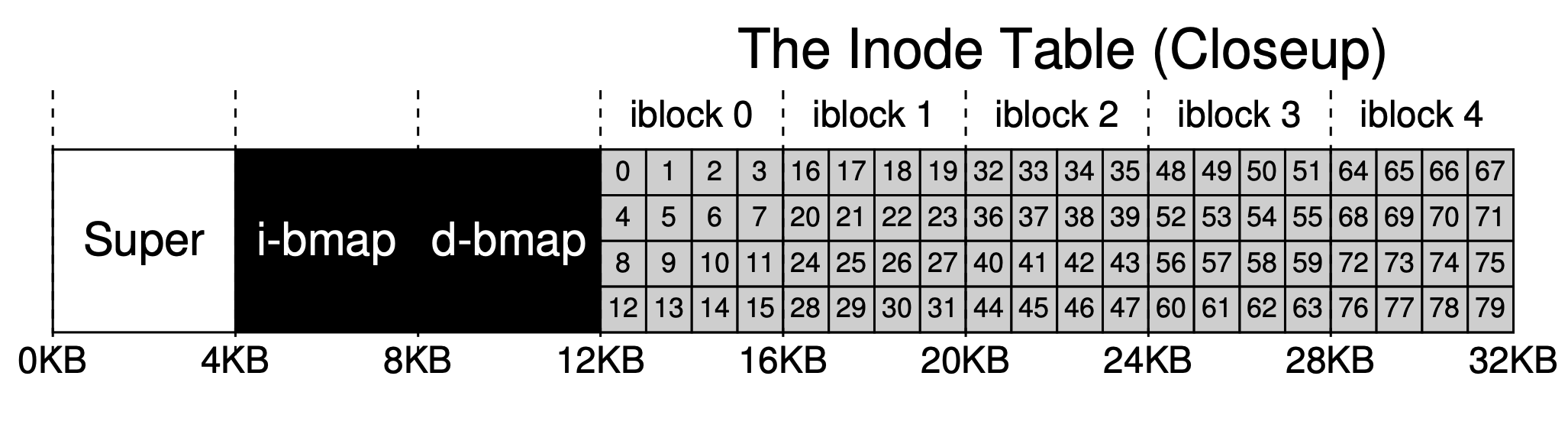
Como mencionado anteriormente, cada inode ocupa 256B. Dado um número de inode, podemos calcular o deslocamento no disco (12KB + inumber * 256), mas devido à troca entre memória interna e externa em blocos, podemos calcular em qual bloco do disco ele está localizado.
O inode principalmente armazena o nome do arquivo, algumas metainformações (controle de permissão, vários eventos, algumas flags) e índices de blocos de dados. Os índices de blocos de dados são, na verdade, também metainformações, mas são destacados porque são muito importantes.
Nós usamos um método de indexação relativamente simples: ponteiro indireto (indirect pointer). Ou seja, o inode não armazena um ponteiro direto para o bloco de dados, mas sim um ponteiro para um bloco de ponteiros (também alocado na área de dados, mas armazenando apenas ponteiros de segundo nível). Se o arquivo for grande o suficiente, pode até ser necessário usar ponteiros de terceiro nível (se nosso pequeno sistema realmente precisar disso, todos podem fazer uma estimativa).