Numpy 배열 추천 기사
NumPy 배열 소개
'NumPy 배열은 Python에서 과학 컴퓨팅에 필수적인 NumPy 라이브러리의 핵심 데이터 구조입니다. Python 리스트와 달리, NumPy 배열은 동종이며, 이는 동일한 데이터 유형의 요소를 포함함을 의미합니다. 이러한 일관성은 더 빠른 계산과 더 효율적인 메모리 사용을 가능하게 합니다.'
간단한 NumPy 배열 생성 예제로 시작해 봅시다:
import numpy as np
# 1D NumPy 배열 생성
arr = np.array([1, 2, 3, 4, 5])
print("numpyarray.com - 1D 배열:", arr)
출력:

이 예제에서는 NumPy를 가져오고 np.array() 함수를 사용하여 1차원 배열을 생성합니다. 결과 배열은 정수를 포함하며 다양한 NumPy 함수를 사용하여 쉽게 조작할 수 있습니다.
NumPy 배열 만들기
NumPy 배열을 생성하는 방법은 여러 가지가 있으며, 각 방법은 다양한 상황에 적합합니다. 몇 가지 일반적인 방법을 살펴보겠습니다:
np.array() 사용하기
NumPy 배열을 생성하는 가장 간단한 방법은 np.array() 함수를 사용하는 것입니다:
import numpy as np
# 2D NumPy 배열 생성
arr_2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("numpyarray.com - 2D 배열:")
print(arr_2d)
출력:

이 예제는 리스트의 리스트에서 2D 배열을 생성합니다. NumPy는 입력에 따라 배열의 형태를 자동으로 결정합니다.
np.zeros()와 np.ones() 사용하기
0이나 1로 채워진 배열을 만들기 위해 np.zeros()와 np.ones()를 사용할 수 있습니다:
import numpy as np
# 제로 배열 생성
zeros_arr = np.zeros((3, 4))
print("numpyarray.com - 제로 배열:")
print(zeros_arr)
# 하나의 배열 생성
ones_arr = np.ones((2, 3, 2))
print("numpyarray.com - 하나의 배열:")
print(ones_arr)
출력:

이 함수들은 배열의 형태를 지정하는 튜플을 인수로 받습니다. 결과 배열은 기본적으로 부동 소수점 0 또는 1로 채워집니다.
np.arange() 및 np.linspace() 사용하기
균일하게 간격이 있는 값을 가진 배열을 생성하기 위해 np.arange()와 np.linspace()가 유용합니다:
import numpy as np
# arange를 사용하여 고르게 간격이 있는 값으로 배열 생성
arange_arr = np.arange(0, 10, 2)
print("numpyarray.com - arange로 생성된 배열:", arange_arr)
# linspace를 사용하여 고르게 간격이 있는 값을 가진 배열 생성
linspace_arr = np.linspace(0, 1, 5)
print("numpyarray.com - linspace로 생성된 배열:", linspace_arr)
출력:

np.arange()는 0에서 10(미포함)까지 2의 간격으로 값을 가지는 배열을 생성하고, np.linspace()는 0과 1(포함) 사이에 5개의 고르게 분포된 값을 가지는 배열을 생성합니다.
배열 속성과 특성
NumPy 배열은 구조와 내용에 대한 유용한 정보를 제공하는 여러 속성과 특성을 가지고 있습니다. 가장 중요한 것들을 살펴보겠습니다:
형태와 크기
shape 속성은 배열의 차원을 나타내는 튜플을 반환하고, size는 총 요소 수를 제공합니다:
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
print("numpyarray.com - 배열 모양:", arr.shape)
print("numpyarray.com - 배열 크기:", arr.size)
출력:

이 예제에서는 2D 배열을 생성하고 그 형태(2행, 3열)와 크기(6개 요소)를 출력합니다.
데이터 유형
dtype 속성은 배열 요소의 데이터 유형에 대한 정보를 제공합니다:
import numpy as np
arr_int = np.array([1, 2, 3])
arr_float = np.array([1.0, 2.0, 3.0])
print("numpyarray.com - 정수 배열 dtype:", arr_int.dtype)
print("numpyarray.com - 부동 소수점 배열 dtype:", arr_float.dtype)
출력:

이 예제는 NumPy가 배열의 내용을 기반으로 적절한 데이터 유형을 자동으로 결정하는 방법을 보여줍니다.
치수
ndim 속성은 배열의 차원(축) 수를 반환합니다:
import numpy as np
arr_1d = np.array([1, 2, 3])
arr_2d = np.array([[1, 2], [3, 4]])
arr_3d = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
print("numpyarray.com - 1D array ndim:", arr_1d.ndim)
print("numpyarray.com - 2D array ndim:", arr_2d.ndim)
print("numpyarray.com - 3D array ndim:", arr_3d.ndim)
출력:

이 예제는 서로 다른 계급의 배열에 대한 차원 수를 결정하는 방법을 보여줍니다.
NumPy 배열의 인덱싱 및 슬라이싱
효율적인 데이터 접근 및 조작은 NumPy 배열을 사용할 때 매우 중요합니다. 다양한 인덱싱 및 슬라이싱 기법을 살펴보겠습니다:
기본 인덱싱
NumPy 배열은 Python 리스트와 유사한 정수 인덱싱을 지원합니다:
import numpy as np
arr = np.array([10, 20, 30, 40, 50])
print("numpyarray.com - 첫 번째 요소:", arr[0])
print("numpyarray.com - 마지막 요소:", arr[-1])
출력:

이 예제는 양수 및 음수 인덱스를 사용하여 1D 배열의 개별 요소에 접근하는 방법을 보여줍니다.
슬라이싱
슬라이싱을 통해 배열의 일부를 추출할 수 있습니다:
import numpy as np
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print("numpyarray.com - 인덱스 2부터 7까지 슬라이스:", arr[2:7])
print("numpyarray.com - 다른 요소들:", arr[::2])
출력:

이 예제에서는 인덱스 2에서 7(제외)까지의 슬라이스를 추출하고 스텝 슬라이싱을 사용하여 다른 요소를 선택합니다.
다차원 인덱싱
다차원 배열의 경우, 특정 요소에 접근하기 위해 쉼표로 구분된 인덱스를 사용할 수 있습니다:
import numpy as np
arr_2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("numpyarray.com - 1행 2열의 요소:", arr_2d[1, 2])
print("numpyarray.com - 두 번째 행:", arr_2d[1])
출력:

이 예제는 2D 배열의 개별 요소와 전체 행에 접근하는 방법을 보여줍니다.
불리언 인덱싱
부울 인덱싱을 사용하면 조건에 따라 요소를 선택할 수 있습니다:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
mask = arr > 2
print("numpyarray.com - 2보다 큰 요소:", arr[mask])
출력:

이 예제에서는 배열에서 2보다 큰 요소를 선택하기 위해 불리언 마스크를 생성합니다.
NumPy 배열 연산 및 수학 함수
NumPy는 배열에 효율적으로 적용할 수 있는 다양한 연산 및 수학 함수를 제공합니다. 몇 가지 일반적인 연산을 살펴보겠습니다:
요소별 연산
NumPy는 배열에 대한 요소별 연산을 지원합니다:
import numpy as np
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
print("numpyarray.com - Addition:", arr1 + arr2)
print("numpyarray.com - Multiplication:", arr1 * arr2)
print("numpyarray.com - Exponentiation:", arr1 ** 2)
출력:

이 예제는 배열의 요소별 덧셈, 곱셈 및 지수를 보여줍니다.
방송
브로드캐스팅은 NumPy가 서로 다른 형태의 배열에 대해 연산을 수행할 수 있게 해줍니다:
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
scalar = 10
print("numpyarray.com - Array + scalar:")
print(arr + scalar)
출력:

이 예제에서 스칼라 값은 배열의 형태에 맞게 브로드캐스트되어 요소별 덧셈을 가능하게 합니다.
유니버설 함수 (ufuncs)
NumPy는 배열에 대해 요소별로 작동하는 일련의 범용 함수를 제공합니다:
import numpy as np
arr = np.array([-1, 0, 1])
print("numpyarray.com - 절대값:", np.abs(arr))
print("numpyarray.com - 지수:", np.exp(arr))
print("numpyarray.com - 절대값의 제곱근:", np.sqrt(np.abs(arr)))
출력:

이 예제는 절대값, 지수 및 제곱근을 계산하기 위한 범용 함수의 사용을 보여줍니다.
배열 재구성 및 조작
NumPy는 배열을 재구성하고 조작하는 다양한 방법을 제공합니다. 몇 가지 일반적인 기술을 살펴보겠습니다:
배열 재구성
reshape() 메서드는 데이터는 변경하지 않고 배열의 형태를 변경할 수 있게 해줍니다:
import numpy as np
arr = np.arange(12)
reshaped_arr = arr.reshape((3, 4))
print("numpyarray.com - Reshaped array:")
print(reshaped_arr)
출력:
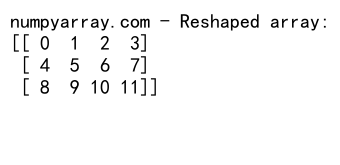
이 예제는 12개의 요소를 가진 1D 배열을 3행 4열의 2D 배열로 변형합니다.
배열 전치
transpose() 메서드 또는 T 속성을 사용하여 배열을 전치할 수 있습니다:
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
transposed_arr = arr.T
print("numpyarray.com - 전치 배열:")
print(transposed_arr)
출력:

이 예제는 2D 배열을 전치하여 행과 열을 교환하는 방법을 보여줍니다.
배열 쌓기
NumPy는 배열을 수직 또는 수평으로 쌓기 위한 함수를 제공합니다:
import numpy as np
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
vertical_stack = np.vstack((arr1, arr2))
horizontal_stack = np.hstack((arr1, arr2))
print("numpyarray.com - 수직 스택:")
print(vertical_stack)
print("numpyarray.com - 수평 스택:")
print(horizontal_stack)
출력:

이 예제는 두 개의 1D 배열을 수직 및 수평으로 쌓는 방법을 보여줍니다.
NumPy 배열 집계 및 통계
NumPy는 배열에서 통계 계산 및 데이터 집계를 위한 다양한 함수를 제공합니다. 몇 가지 일반적인 작업을 살펴보겠습니다:
기본 통계
NumPy는 배열에 대한 기본 통계를 계산하는 함수를 제공합니다:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print("numpyarray.com - 평균:", np.mean(arr))
print("numpyarray.com - 중앙값:", np.median(arr))
print("numpyarray.com - 표준 편차:", np.std(arr))
출력:

이 예제는 배열의 평균, 중앙값 및 표준 편차를 계산하는 방법을 보여줍니다.
축을 따라 집계
다차원 배열의 경우 특정 축을 따라 집계를 수행할 수 있습니다:
import numpy as np
arr_2d = np.array([[1, 2, 3], [4, 5, 6]])
print("numpyarray.com - 행을 따라 합계:", np.sum(arr_2d, axis=1))
print("numpyarray.com - 열을 따라 최대값:", np.max(arr_2d, axis=0))
출력:

이 예제는 2D 배열의 행을 따라 합계를 계산하고 열을 따라 최대값을 계산하는 방법을 보여줍니다.
누적 작업
NumPy는 배열에 대한 누적 연산을 위한 함수를 제공합니다:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print("numpyarray.com - 누적 합:", np.cumsum(arr))
print("numpyarray.com - 누적 곱:", np.cumprod(arr))
출력:

이 예제는 배열의 누적 합계와 누적 곱을 계산하는 방법을 보여줍니다.
고급 배열 개념
NumPy 배열을 다루기 위한 몇 가지 고급 개념과 기술을 탐구해 봅시다:
구조화된 배열
구조화된 배열을 사용하면 이름이 있는 필드를 가진 복잡한 데이터 유형을 정의할 수 있습니다:
import numpy as np
dt = np.dtype([('이름', 'U10'), ('나이', 'i4'), ('체중', 'f4')])
arr = np.array([('앨리스', 25, 55.5), ('밥', 30, 70.2)], dtype=dt)
print("numpyarray.com - 구조화된 배열:")
print(arr)
print("numpyarray.com - 나이:", arr['나이'])
출력:

이 예제는 이름, 나이 및 체중에 대한 필드를 가진 구조화된 배열을 생성하고 개별 필드에 접근하는 방법을 보여줍니다.
메모리 뷰
메모리 뷰는 배열 데이터를 복사하지 않고 접근할 수 있는 방법을 제공합니다:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
mem_view = memoryview(arr)
print("numpyarray.com - 메모리 뷰:", mem_view)
print("numpyarray.com - 메모리 뷰를 통한 첫 번째 요소:", mem_view[0])
출력:

이 예제는 NumPy 배열의 메모리 뷰를 생성하고 뷰를 통해 요소에 접근하는 방법을 보여줍니다.
마스킹된 배열
마스킹된 배열은 누락되거나 유효하지 않은 데이터가 있는 배열을 다룰 수 있게 해줍니다:
import numpy as np
arr = np.array([1, 2, -999, 4, 5])
masked_arr = np.ma.masked_array(arr, mask=[False, False, True, False, False])
print("numpyarray.com - Masked array:", masked_arr)
print("numpyarray.com - Mean of masked array:", np.ma.mean(masked_arr))
출력:

이 예제는 값 -999가 유효하지 않은 것으로 처리되는 마스크 배열을 생성하고, 마스크 배열에서 통계를 계산하는 방법을 보여줍니다.
NumPy 배열을 이용한 성능 최적화
NumPy 배열은 고성능 수치 계산을 위해 설계되었습니다. 코드 최적화를 위한 몇 가지 팁은 다음과 같습니다:
벡터화
벡터화는 명시적 루프를 배열 연산으로 대체하는 과정입니다:
import numpy as np
# 느린, 명시적인 루프
def slow_sum_of_squares(n):
result = 0
for i in range(n):
result += i ** 2
return result
# 빠르고 벡터화된 버전
def fast_sum_of_squares(n):
return np.sum(np.arange(n) ** 2)
n = 1000000
print("numpyarray.com - 제곱의 합 (느림):", slow_sum_of_squares(n))
print("numpyarray.com - 제곱의 합 (빠름):", fast_sum_of_squares(n))
출력:

이 예제는 벡터화가 큰 배열에 대해 성능을 어떻게 크게 향상시킬 수 있는지를 보여줍니다.
내장 함수 사용하기
NumPy의 내장 함수는 성능을 최적화합니다:
import numpy as np
arr = np.random.rand(1000000)
# 느린, 파이썬 수준의 루프
def slow_mean(arr):
return sum(arr) / len(arr)
# 빠름, NumPy의 내장 함수를 사용하여
def fast_mean(arr):
return np.mean(arr)
print("numpyarray.com - 평균 (느림):", slow_mean(arr))
print("numpyarray.com - 평균 (빠름):", fast_mean(arr))
출력:

이 예제는 NumPy의 내장 함수를 사용하는 것이 수동으로 작업을 구현하는 것보다 훨씬 빠를 수 있음을 보여줍니다.
NumPy 배열 입력 및 출력
NumPy는 배열 데이터를 파일에 읽고 쓰기 위한 다양한 함수를 제공합니다: