이 기사에서는 우리가 매일 사용하지만 실제로는 거의 이해하지 못하는 도구인 Google의 내부 작동에 대해 탐구합니다. Google에 대한 반독점 소송에서 최근 문서가 유출되었는데, 이를 통해 Google의 알고리즘을 탐구할 수 있는 독특한 기회가 생겼습니다. 이러한 알고리즘 중 일부는 이미 알려져 있었지만, 흥미로운 점은 우리와 공유되지 않았던 내부 정보입니다.
우리는 이러한 기술이 어떻게 우리의 검색을 처리하고 우리가 보는 결과를 결정하는지 조사할 것입니다. 이 분석에서 나는 각 Google 검색 뒤의 복잡한 시스템에 대한 명확하고 상세한 시각을 제공하고자 합니다.
또한, 새로운 발견을 고려하여 Google의 아키텍처를 다이어그램으로 표현하려고 노력하겠습니다.
먼저, 2개의 문서에서 언급된 모든 알고리즘을 추출하는 데 중점을 둘 것입니다. 첫 번째는 Pandu Nayak의 증언에 관한 것 (Alphabet의 부사장)이며, 두 번째는 Douglas W. Oard 교수의 반박 증언에 관한 것으로, 여기서는 Google의 전문가인 Edward A. Fox 교수가 2022년 6월 3일자 보고서에서 제시한 의견에 대한 논쟁이 이루어졌습니다. 후자의 문서에서는 Google이 실험 데이터를 조작하여 사용자 데이터가 그들에게 그리 중요하지 않다는 것을 입증하려고 시도한 유명하고 논란이 되는 'Fox 보고서'에 대해 논의되었습니다.
공식 정보가 있는 경우 각 알고리즘을 설명하고, 그런 다음 시험에서 추출한 정보를 이미지에 넣겠습니다.

Navboost
Google에게 중요한 키 요소이자 가장 중요한 요소 중 하나입니다. Paul Haar가 이것을 자신의 이력서에 추가했기 때문에 2019 'Project Veritas' 유출에서도 이것이 드러났습니다.

Navboost는 사용자가 서로 다른 쿼리에 대한 클릭을 통해 검색 결과와 상호 작용하는 방식에 대한 데이터를 수집합니다. 이 시스템은 클릭을 정리하고, 인간이 만든 품질 평가에서 학습하는 알고리즘을 사용하여 결과의 순위를 개선합니다. 이 아이디어는 특정 쿼리에 대해 결과가 자주 선택되고(긍정적으로 평가되는 경우) 해당 결과의 순위가 높아져야 한다는 것입니다. 흥미로운 점은, 구글이 많은 년 전에 Navboost를 제거하는 실험을 진행했고 결과가 악화되었다는 것입니다.

RankBrain
2015년에 출시된 RankBrain은 구글의 AI 및 기계 학습 시스템으로, 검색 결과 처리에 필수적입니다. 기계 학습을 통해 언어 이해 능력과 검색 의도를 지속적으로 향상시키며, 모호하거나 복잡한 질의를 해석하는 데 특히 효과적입니다. 콘텐츠와 링크에 이어 구글 랭킹에서 세 번째로 중요한 요소로 소개되었습니다. Tensor Processing Unit (TPU)를 사용하여 처리 능력과 에너지 효율성을 크게 향상시킵니다.

나는 QBST와 Term Weighting이 RankBrain의 구성 요소임을 추론한다. 그래서 나는 이것들을 여기에 포함시킨다.
QBST (Query Based Salient Terms)는 쿼리와 관련 문서 내에서 가장 중요한 용어에 초점을 맞추며, 이 정보를 사용하여 결과의 순위에 영향을 미칩니다. 이는 검색 엔진이 사용자의 쿼리의 가장 중요한 측면을 빠르게 인식하고 관련 결과를 우선 순위로 지정할 수 있음을 의미합니다. 예를 들어, 이는 모호하거나 복잡한 쿼리에 특히 유용합니다.
증언 문서에서 QBST는 BERT의 한계와 관련하여 언급됩니다. 구체적으로는 «BERT는 navboost, QBST 등과 같은 대규모 기억 시스템을 포함하지 않는다.»라는 것입니다. 이는 BERT가 자연어를 이해하고 처리하는 데 뛰어나지만 QBST와 같은 대규모 기억 시스템을 처리하거나 대체하는 능력에는 제한이 있다는 것을 의미합니다.

용어 가중은 사용자가 검색 결과와 상호 작용하는 방식에 따라 쿼리 내 개별 용어의 상대적 중요성을 조정합니다. 이는 쿼리의 맥락에서 특정 용어의 관련성을 결정하는 데 도움이 됩니다. 이 가중치는 검색 엔진 데이터베이스에서 매우 일반적이거나 매우 드문 용어를 효율적으로 처리하여 결과를 균형있게 유지합니다.

딥랭크
자연어 이해에서 한 단계 더 나아가 검색 엔진이 질문의 의도와 맥락을 더 잘 이해할 수 있습니다. 이것은 BERT 덕분에 가능한데, 사실 DeepRank는 BERT의 내부 이름입니다. 대규모 문서 데이터를 사전 훈련하고 클릭 및 인간 평가로부터의 피드백으로 조정함으로써 DeepRank는 검색 결과를 더 직관적이고 사용자가 실제로 찾는 것과 관련성이 더 높도록 세밀하게 조정할 수 있습니다.

RankEmbed
RankEmbed는 아마도 랭킹을 위한 관련 기능을 임베딩하는 작업에 중점을 둘 것으로 보입니다. 문서에는 기능과 능력에 대한 구체적인 내용이 없지만, 구글의 검색 분류 과정을 개선하기 위해 설계된 딥 러닝 시스템으로 추론할 수 있습니다.
RankEmbed-BERT
RankEmbed-BERT는 RankEmbed의 알고리즘과 구조를 통합한 향상된 버전으로, BERT의 알고리즘과 구조를 통합했습니다. 이 통합은 RankEmbed의 언어 이해 능력을 크게 향상시키기 위해 수행되었습니다. 최근 데이터로 재학습되지 않으면 효과가 감소할 수 있습니다. 훈련에는 트래픽의 소량만 사용되며, 모든 사용 가능한 데이터를 사용할 필요가 없음을 나타냅니다.
RankEmbed-BERT는 RankBrain 및 DeepRank와 같은 다른 딥 러닝 모델과 함께 구글 검색 시스템의 최종 랭킹 점수에 기여하지만, 결과의 초기 검색 이후에 작동합니다(재랭킹). 클릭 및 쿼리 데이터로 훈련되며 IS(인간 평가자) 데이터를 사용하여 정교하게 조정되었으며 RankBrain과 같은 피드포워드 모델보다 훈련하는 데 더 많은 계산 비용이 듭니다.

MUM
MUM은 BERT보다 약 1,000배 강력하며 구글 검색의 주요 발전을 나타냅니다. 2021년 6월에 출시되었으며 75개 언어를 이해할 뿐만 아니라 멀티모달 기능을 갖추고 있어 다양한 형식의 정보를 해석하고 처리할 수 있습니다. 이 멀티모달 기능 덕분에 MUM은 더 포괄적이고 맥락적인 응답을 제공하여 상세 정보를 얻기 위한 여러 차례의 검색 필요성을 줄입니다. 그러나 고성능 컴퓨팅 요구로 인해 MUM의 사용은 매우 선택적입니다.

탱그램과 접착제
모든 이 시스템들은 Tangram의 프레임워크 내에서 Glue의 데이터를 사용하여 SERP를 구성하는 역할을 합니다. 이는 결과를 순위 매기는 것뿐만 아니라 이미지 캐로셀, 직접적인 답변, 그리고 기타 비텍스트 요소와 같은 요소들을 고려하여 사용자에게 유용하고 접근성 있게 구성하는 것입니다.

마지막으로, 신선도 노드와 즉시 접착제는 결과가 최신 상태를 유지하도록 보장하여 최근 정보에 더 많은 가중치를 부여합니다. 이는 특히 뉴스나 최신 이벤트에 관한 검색에서 매우 중요합니다.

재판에서는, 쿼리의 주요 의도가 공격 당일에 변경되어 인스턴트 글루가 일반 이미지를 억제하고 대신 탕그램에서 니스의 관련 뉴스와 사진을 대중화하는데 이용되었다고 언급합니다(«nice pictures» vs «Nice pictures»):

With all this, Google would combine these algorithms to:
- 쿼리 이해: 검색 창에 입력된 단어와 구절의 의도를 해석하는 것.
- 관련성 결정: 콘텐츠가 쿼리와 얼마나 일치하는지를 기반으로 결과를 순위 매김하며, 과거 상호작용 및 품질 평가에서 신호를 사용함.
- 신선도 우선순위: 중요할 때 가장 신선하고 관련성 높은 정보가 순위를 올리도록 보장함.
- 결과 개인화: 쿼리 뿐만 아니라 사용자의 위치 및 사용 중인 장치와 같은 사용자 맥락에 맞게 검색 결과를 맞춤화함. 이보다 더 개인화된 것은 거의 없음(https://twitter.com/natzir9/status/1725909290899182047)
지금까지 본 것으로 보아, Tangram, Glue, 그리고 RankEmbed-BERT가 현재까지 유출된 유일한 신제품으로 판단됩니다.
우리가 본 바와 같이, 이러한 알고리즘들은 이제 우리가 다시 한번 시험에서 정보를 추출하면서 다양한 지표에 의해 영양을 받습니다.
Google이 검색 품질을 평가하는 데 사용하는 지표
이 섹션에서는 다시 Douglas W. Oard 교수의 반박 증언에 중점을 두고, 이전 유출물인 '프로젝트 베리타스'의 정보를 포함할 것입니다. 이전 유출물인 '프로젝트 베리타스'의 정보도 포함할 것입니다.
한 슬라이드에서는 Google이 검색 결과 순위를 매길 때 알고리즘이 고려하는 요소를 개발하고 조정하며, 알고리즘의 변화가 검색 결과의 품질에 미치는 영향을 모니터링하기 위해 다음과 같은 지표를 사용한다는 것을 보여 주었습니다. 이는 사용자의 의도를 포착하려는 노력의 일환입니다.
1. IS 점수
인간 평가자들은 Google의 검색 제품의 개발과 정제에 중요한 역할을 합니다. 그들의 작업을 통해 'IS 점수' (0에서 100까지의 정보 만족도 점수)라고 알려진 측정 항목이 생성되며, 이는 평가자들의 평가에서 유도되어 Google의 품질의 주요 지표로 사용됩니다.
평가는 익명으로 진행되며, 평가자들은 Google인지 Bing을 테스트하는지를 모릅니다. 이는 Google의 성능을 주요 경쟁사와 비교하는 데 사용됩니다.
이 IS 점수는 인식된 품질을 반영하는 것뿐만 아니라 RankBrain 및 RankEmbed BERT와 같은 분류 알고리즘을 포함한 Google의 검색 시스템 내에서 다양한 모델을 훈련하는 데 사용됩니다.
문서에 따르면, 2021년 현재 IS4를 사용하고 있습니다. IS4는 사용자에 대한 유틸리티의 근사치로 간주되며 해당 대로 취급되어야 합니다. 이는 아마도 가장 중요한 순위 측정 지표로 설명되지만, 근사치이며 나중에 논의할 오차의 가능성을 강조하고 있습니다.

이 메트릭의 파생물인 IS4@5도 언급되었습니다.
IS4@5 metric는 구글이 검색 결과의 품질을 측정하는 데 사용하는 지표로, 특히 처음 다섯 개의 위치에 초점을 맞춥니다. 이 지표에는 OneBoxes(«파란 링크»로 알려진)와 같은 특수 검색 기능뿐만 아니라 포함됩니다. IS4@5 web라는 이 지표의 변형도 있으며, 이는 검색 결과에서 광고와 같은 다른 요소를 제외하고 처음 다섯 개의 웹 결과를 평가하는 데 중점을 둡니다.

IS4@5은 검색 결과의 품질과 관련성을 빠르게 평가하는 데 유용하지만, 그 범위는 제한적입니다. 광고와 같은 요소를 제외하는 등 검색 품질의 모든 측면을 다루지 않습니다. 따라서 이 지표는 검색 품질의 부분적인 관점을 제공합니다. 구글의 검색 결과의 품질을 완전하고 정확하게 평가하려면, 체중만으로가 아니라 여러 지표를 통해 일반적인 건강 상태를 평가하는 것과 유사하게 더 넓은 범위의 지표와 요소를 고려해야 합니다.
인간 평가자의 한계
평가자들은 기술적인 질문을 이해하거나 제품의 인기를 판단하거나 질문의 해석을 하는 등 여러 문제에 직면하게 됩니다. 또한, MUM과 같은 언어 모델은 언어와 세계적인 지식을 인간 평가자와 유사하게 이해할 수 있을 것으로 예상되며, 이는 미래의 관련성 평가에 대한 기회와 도전을 제시할 것입니다.
중요성에도 불구하고, 그들의 시각은 실제 사용자들의 시각과 크게 다를 수 있다. 평가자들은 질의 주제와 관련된 사용자들이 가질 수 있는 특정 지식이나 이전 경험을 갖고 있지 않을 수 있으며, 이는 결과의 관련성과 품질에 대한 평가에 영향을 미칠 수 있다.
2018년과 2021년 유출된 문서에서, 구글이 내부 프레젠테이션에서 인정한 모든 오류 목록을 정리할 수 있었습니다.
- 시간적 불일치: 쿼리, 평가 및 문서가 서로 다른 시간에 속해 있을 수 있기 때문에 불일치가 발생할 수 있으며, 이는 문서의 현재 관련성을 정확하게 반영하지 못할 수 있습니다.
- 평가 재사용: 빠르게 평가하고 비용을 통제하기 위해 평가를 재사용하는 것은 현재 콘텐츠의 신선도나 관련성을 대표하지 못하는 평가로 이어질 수 있습니다.
- 기술적 쿼리 이해: 평가자들이 기술적인 쿼리를 이해하지 못할 경우, 전문적이거나 특정한 주제의 관련성을 평가하는 데 어려움을 겪을 수 있습니다.
- 인기 평가: 경쟁적인 쿼리 해석이나 경쟁 제품의 인기를 평가자가 판단하는 것은 그들의 평가 정확도에 영향을 줄 수 있는 내재적인 어려움이 있습니다.
- 평가자 다양성: 일부 지역의 평가자들 사이의 다양성 부족과 모두 성인임이 구글의 사용자 베이스 다양성을 반영하지 못합니다. 사용자는 미성년자를 포함합니다.
- 사용자 생성 콘텐츠: 평가자들은 사용자 생성 콘텐츠에 엄격할 수 있으며, 이는 유용하고 관련성이 있음에도 불구하고 그 가치를 과소평가할 수 있습니다.
- 신선도 노드 트레이닝: 적절한 훈련 라벨의 부족으로 인해 신선도 모델을 조정하는 데 문제가 있습니다. 인간 평가자들은 종종 관련성의 신선도 측면에 충분한 주의를 기울이지 않거나 쿼리의 시간적 맥락이 부족합니다. 이는 새로움을 찾는 쿼리에 대한 최근 결과를 과소평가하게 됩니다. 기존의 IS를 기반으로 하고 Relevance 및 기타 점수 곡선을 훈련시키기 위해 사용된 Tangram Utility는 동일한 문제를 겪었습니다. 인간 라벨의 한계로 인해 Freshness Node의 점수 곡선은 처음 출시될 때 수동으로 조정되었습니다.
나는 진심으로 인간 평가자들이 '파라사이트 SEO'의 효과적인 기능에 책임이 있었다고 믿습니다. 댄니 설리번의 주목을 받게 된 것이며, 이 트윗에서 공유되었습니다.

최신 품질 지침의 변경 사항을 살펴보면 그들이 마침내 Needs Met 지표의 정의를 조정하고 평가자가 고려해야 할 새로운 예시를 포함했다는 점을 볼 수 있습니다. 결과가 권위적이더라도 사용자가 찾는 정보를 포함하지 않는다면 높은 등급으로 평가해서는 안 된다는 것을 고려해야 합니다.

Google Notes의 새로운 출시는 이와 관련이 있다고 생각합니다. Google은 어떤 콘텐츠가 품질 콘텐츠인지 100% 확신할 수 없습니다.

나는 이야기하는 이 사건들이 거의 동시에 발생한 것은 우연이 아니라고 믿고, 곧 변화를 볼 것이라고 믿습니다.
2. PQ (Page Quality)
여기에서는 페이지 품질에 대해 이야기하는 것으로 추론하고 있으므로 이것이 제 해석입니다. 그렇다면 사용된 측정 항목으로서 언급되었을 뿐 시험 문서에는 아무것도 없습니다. PQ에 대해 언급하는 유일한 공식적인 자료는 Search Quality Rater Guidelines에서 찾을 수 있으며, 시간이 지남에 따라 변화합니다. 따라서 이는 인간 평가자들에 대한 또 다른 작업이 될 것입니다.

이 정보는 알고리즘에도 전송되어 모델을 생성합니다. 여기에서 우리는 'Project Veritas'에서 이 정보가 유출된 제안을 볼 수 있습니다.

여기에는 흥미로운 점이 있습니다. 문서에 따르면 품질 평가자는 모바일에서만 페이지를 평가합니다.

3. Side-by-Side
이것은 아마도 두 개의 검색 결과 세트를 옆에 두고 평가자가 그들의 상대적인 품질을 비교할 수 있는 테스트를 가리킵니다. 이는 특정 검색 쿼리에 대해 어떤 결과 세트가 더 관련성이 있거나 유용한지를 결정하는 데 도움이 됩니다. 그렇다면, 구글이 이를 위한 다운로드 가능한 도구인 sxse를 가지고 있었다는 것을 기억합니다.

이 도구를 사용하면 사용자가 선호하는 검색 결과 세트에 투표할 수 있어서, 검색 시스템의 다양한 조정 또는 버전의 효과에 대한 직접적인 피드백을 제공합니다.
4. 라이브 실험
How Search Works에 공개된 공식 정보에 따르면, Google은 새로운 기능이 모든 사람에게 전파되기 전에 어떻게 상호 작용하는지를 테스트하기 위해 실제 트래픽으로 실험을 진행합니다. 그들은 해당 기능을 일부 사용자의 작은 비율에게 활성화하고 해당 기능이 없는 대조군의 행동과 비교합니다. 검색 결과에 대한 사용자 상호 작용에 대한 상세한 지표는 다음과 같습니다:
- 결과를 클릭함
- 수행된 검색 횟수
- 쿼리 포기
- 사람들이 결과를 클릭하는 데 걸린 시간
이 데이터는 새로운 기능과의 상호작용이 긍정적인지를 측정하고, 변경 사항이 검색 결과의 관련성과 유용성을 높이는지를 보장합니다.
하지만 재판 문건은 오직 두 가지 지표에만 주목한다:

- 위치 가중 클릭: 이 지표는 클릭의 지속 시간과 결과 페이지에서의 위치를 고려하여 사용자가 찾은 결과에 대한 만족도를 반영할 것입니다.
- 주의: 이는 페이지에 소요된 시간을 측정하는 것을 의미할 수 있으며, 사용자가 결과 및 해당 콘텐츠와 상호 작용하는 시간을 나타낼 수 있습니다.
또한, 판두 나야크의 증언 내용에 따르면, 그들은 전통적인 A/B 테스트 대신 교대로 진행하는 알고리즘 테스트를 수행한다고 설명했습니다. 이를 통해 빠르고 신뢰할 수 있는 실험을 수행하여 순위의 변동을 해석할 수 있게 되었습니다.
5. 신선도
신선함은 결과와 검색 기능의 중요한 측면입니다. 가능한 한 빨리 관련 정보를 표시하고, 정보가 오래되면 표시를 중지하는 것이 중요합니다.
랭킹 알고리즘에서 최신 문서를 검색 결과 페이지(SERP)에 표시하려면 색인 및 서빙 시스템은 매우 낮은 대기 시간으로 최신 문서를 발견, 색인 및 서빙할 수 있어야 합니다. 이상적으로는 전체 색인이 가능한 한 최신 상태여야 하지만, 낮은 대기 시간으로 모든 문서를 색인하는 데 제한적인 기술적 및 비용적 제약이 있습니다. 색인 시스템은 대기 시간, 비용 및 품질 사이의 서로 다른 트레이드오프를 제공하는 별도 경로에서 문서에 우선순위를 부여합니다.
매우 최신 콘텐츠는 그 중요성이 과소평가될 위험이 있고, 반대로, 많은 중요성 증거를 가진 콘텐츠는 쿼리 의미의 변화로 인해 덜 중요해질 수 있습니다.

Freshness Node의 역할은 오래된 점수에 보정을 추가하는 것입니다. 신선한 콘텐츠를 요청하는 쿼리에 대해 신선한 콘텐츠를 강조하고 오래된 콘텐츠를 저하시킵니다.
얼마 전에 Google Caffeine이 더 이상 존재하지 않는다는 사실이 유출되었습니다 (또는 Percolator 기반 색인 시스템으로도 알려짐). 내부적으로는 여전히 이전 이름을 사용하지만, 현재 존재하는 것은 사실 완전히 새로운 시스템입니다. 새로운 «카페인»은 사실 서로 통신하는 일련의 마이크로서비스입니다. 이는 색인 시스템의 다른 부분이 독립적이지만 연결되어 특정 기능을 수행하는 서비스로 작동한다는 것을 의미합니다. 이 구조는 더 큰 유연성, 확장성, 그리고 업데이트 및 개선을 쉽게 할 수 있는 장점을 제공할 수 있습니다.
내가 해석한 바에 따르면, 이러한 마이크로서비스의 일부는 Tangram과 Glue일 것으로 보입니다. 특히 Freshness Node와 Instant Glue입니다. 다른 유출된 문서에서 2016년 제안된 내용을 발견했는데, 이에는 'Freshness 신호'로 'Instant Navboost'를 만들거나 통합하는 것이 포함되어 있었으며, Chrome 방문도 포함되어 있었습니다.

지금까지 그들은 이미 'Freshdocs-instant'를 통합했습니다(이는 freshdocs-instant-docs pubsub이라는 목록에서 추출되었으며, 해당 미디어에서 발표된 뉴스를 발표 후 1분 이내에 가져왔습니다) 그리고 검색 피크 및 콘텐츠 생성 상관 관계:

Freshness metrics 내에서는 Correlated Ngrams 및 Correlated Salient Terms의 분석을 통해 감지된 여러 지표가 있습니다:
- 상관된 NGram: 이들은 통계적으로 유의미한 패턴으로 함께 나타나는 단어 그룹입니다. 상관성은 이벤트나 트렌드 주제 중에 갑자기 증가할 수 있으며, 이는 급증을 나타낼 수 있습니다.
- 상관된 중요 용어: 이들은 특정 주제나 이벤트와 밀접하게 관련된 두드러진 용어로, 짧은 기간 동안 문서에서 발생 빈도가 증가하여 관심이나 관련 활동의 급증을 시사합니다.
한 번 스파이크가 감지되면, 다음과 같은 신선도 지표가 사용될 수 있습니다:
- 단어 단위 (RTW): 각 문서에 대해 제목, 앵커 텍스트, 그리고 본문의 처음 400자가 사용됩니다. 이들은 트렌드 감지에 관련된 단어로 분해되어 Hivemind 색인에 추가됩니다. 본문에는 일반적으로 반복되거나 일반적인 요소(보일러플레이트)를 제외한 기사의 주요 내용이 포함됩니다.
- 에포크 이후 반시간 (TEHH): 유닉스 시간의 시작으로부터 반시간 단위로 표시된 시간 측정치입니다. 반시간 정확도로 언제 일어났는지를 확인하는 데 도움이 됩니다.
- 지식 그래프 엔터티 (RTKG): Google의 지식 그래프에 있는 객체에 대한 참조로, 이는 실제 엔터티(사람, 장소, 사물)와 그들의 상호 연결을 포함하는 데이터베이스입니다. 이는 의미적 이해와 맥락을 풍부하게 하는 데 도움이 됩니다.
- S2 셀 (S2): Google의 지식 그래프에 있는 객체에 대한 참조로, 이는 실제 엔터티(사람, 장소, 사물)와 그들의 상호 연결을 포함하는 데이터베이스입니다. 이는 의미적 이해와 맥락을 풍부하게 하는 데 도움이 됩니다.
- Freshbox 기사 점수 (RTF): 지도에서 지리적 색인에 사용되는 지구 표면의 기하학적 분할입니다. 이들은 웹 콘텐츠를 정확한 지리적 위치와 연결하는 데 도움이 됩니다.
- 문서 NSR (RTN): 이는 문서의 뉴스 관련성을 나타낼 수 있으며, 현재 이슈나 트렌드 이벤트와 관련하여 문서가 얼마나 관련성이 있고 신뢰할 수 있는지를 결정하는 지표로 보입니다. 이 지표는 저품질이나 스팸 콘텐츠를 걸러내는 데 도움이 되어 색인화되고 강조된 문서가 고품질이며 실시간 검색에 중요한 것임을 보장할 수 있습니다.
- 지리적 차원: 문서에 언급된 이벤트나 주제의 지리적 위치를 정의하는 기능입니다. 이는 좌표, 장소 이름 또는 S2 셀과 같은 식별자를 포함할 수 있습니다.
미디어 업무를 하고 계시다면, 이 정보는 중요하며 디지털 편집자를 위한 교육 자료에 항상 포함시킵니다.
클릭의 중요성
이 섹션에서는 Google 내부 이메일에서 공유된 '통합 클릭 예측'이라는 제목의 프레젠테이션, ‘Google은 마법 같다’ 프레젠테이션, Search All Hands 프레젠테이션, Danny Sullivan의 내부 이메일, 그리고 '프로젝트 베리타스' 유출 문서에 중점을 둘 것입니다.
이 과정을 통해 사용자 행동/요구를 이해하는 데 클릭의 기본적인 중요성을 볼 수 있습니다. 다시 말해, 구글은 우리의 데이터가 필요합니다. 흥미로운 점은 구글이 이야기하는 것을 금지된 것 중 하나가 클릭이었습니다.

시작하기 전에, 2016년 이전에 클릭에 관한 주요 문서들이 작성되었다는 점을 강조하는 것이 중요합니다. 그 이후 구글은 상당한 변화를 겪었지만, 그들의 접근 방식의 기초는 여전히 사용자 행동의 분석을 기반으로 하며, 이를 품질 신호로 간주합니다. CAS 모델을 설명하는 특허를 기억하시나요?

사용자가 제공하는 모든 검색과 클릭은 구글의 학습과 지속적인 개선에 기여합니다. 이 피드백 루프를 통해 구글은 검색 선호도와 행동에 대해 적응하고 '학습'할 수 있으며, 사용자의 요구를 이해한다는 환상을 유지합니다.

구글은 매일, 과거 데이터를 기반으로 미래 예측을 지속적으로 조정하고 초월하기 위해 설계된 시스템 내에서 10억 건 이상의 새로운 행동을 분석합니다. 적어도 2016년까지는 이는 당시 AI 시스템의 용량을 초과하여, 앞서 본 수동 작업과 RankLab에서의 조정이 필요했습니다.
RankLab는 신호와 순위 요소의 다양한 가중치를 테스트하고 그 후의 영향을 이해하는 실험실인 것으로 알고 있습니다. 또한 내부 도구인 «Twiddler»(제가 몇 년 전에 «Project Veritas»에서 읽은 내용 중 하나)에 대한 책임이 있을 수 있으며, 이 도구는 특정 결과의 IR 점수를 수동으로 수정하는 것을 목적으로 하거나 다른 말로, 다음을 수행할 수 있습니다:

이 짧은 휴식 후에, 나는 계속합니다.
인간 평가자의 평가는 기본적인 시각을 제공하지만, 클릭은 검색 행동의 훨씬 더 자세한 풍경을 제공합니다.


이는 복잡한 패턴을 드러내며 둘째, 셋째 차수의 영향을 학습할 수 있게 합니다.
- 두 번째 차수 효과는 신흥 패턴을 반영합니다: 만약 대다수가 간단한 목록보다 상세한 기사를 선호하고 선택한다면, 구글은 이를 감지합니다. 시간이 지남에 따라 알고리즘을 조정하여 관련 검색에서 더 상세한 기사를 우선시합니다.
- 세 번째 차수 효과는 보다 넓고 장기적인 변화입니다: 클릭 트렌드가 포괄적인 안내서를 선호한다면, 콘텐츠 제작자들은 적응합니다. 그들은 더 상세한 기사를 생산하고 목록을 줄이기 시작하여 웹 상의 콘텐츠의 성격을 변화시킵니다.
분석된 문서에서는 검색 결과의 관련성이 클릭 분석을 통해 개선된 구체적인 사례가 제시되었습니다. 구글은 클릭을 기반으로 한 사용자 선호도의 불일치를 확인했는데, 이는 15,000개의 관련 없는 문서들에 둘러싸인 상황에서 관련성이 있는 것으로 판명된 몇 가지 문서에 대한 클릭을 통해 드러났습니다. 이 발견은 대량의 데이터 속에 숨겨진 관련성을 식별하는 데 유용한 도구로서 사용자 클릭의 중요성을 강조합니다.

Google는 '과거와 함께 훈련하여 미래를 예측'하여 오버피팅을 피합니다. 지속적인 평가와 데이터 업데이트를 통해 모델은 최신이며 관련성을 유지합니다. 이 전략의 중요한 측면은 지역화 개인화로, 다양한 지역의 다른 사용자에게 관련성 있는 결과를 보장합니다.
개인화에 관해서, 구글은 최근 문서에서 이것이 제한적이며 순위를 거의 변경하지 않는다고 주장합니다. 또한 «상위 뉴스»에서는 결코 발생하지 않는다고 언급합니다. 사용되는 경우는 무엇을 검색하는지 더 잘 이해하기 위해, 이전 검색 내용의 맥락을 활용하거나 자동 완성으로 예측적인 제안을 하는 데 사용된다고 합니다. 사용자가 자주 이용하는 비디오 제공업체를 약간 높일 수 있지만, 기본적으로 모두가 거의 동일한 결과를 볼 것이라고 언급합니다. 그들에 따르면, 쿼리가 사용자 데이터보다 중요하다고 합니다.
이 클릭 중심 접근 방식은 특히 새로운 또는 드물게 등장하는 콘텐츠와 마주한 어려움에 직면한다는 것을 기억하는 것이 중요합니다. 검색 결과의 품질을 평가하는 것은 단순히 클릭 수를 세는 것을 넘어서는 복잡한 과정입니다. 제가 쓴 이 기사는 몇 년이 지났지만, 이 문제에 대해 더 깊이 파고들 수 있는 데 도움이 될 것으로 생각합니다.
Google의 아키텍처
이전 섹션을 따르면, 이것은 저희가 모든 이 요소들을 다이어그램에 어떻게 배치할 수 있을지에 대한 제가 형성한 정신적인 이미지입니다. 구글의 아키텍처의 일부 구성 요소가 특정 위치에 없거나 그와 같이 관련되지 않을 가능성이 매우 높지만, 저는 이것이 근사치로 충분하다고 믿습니다.
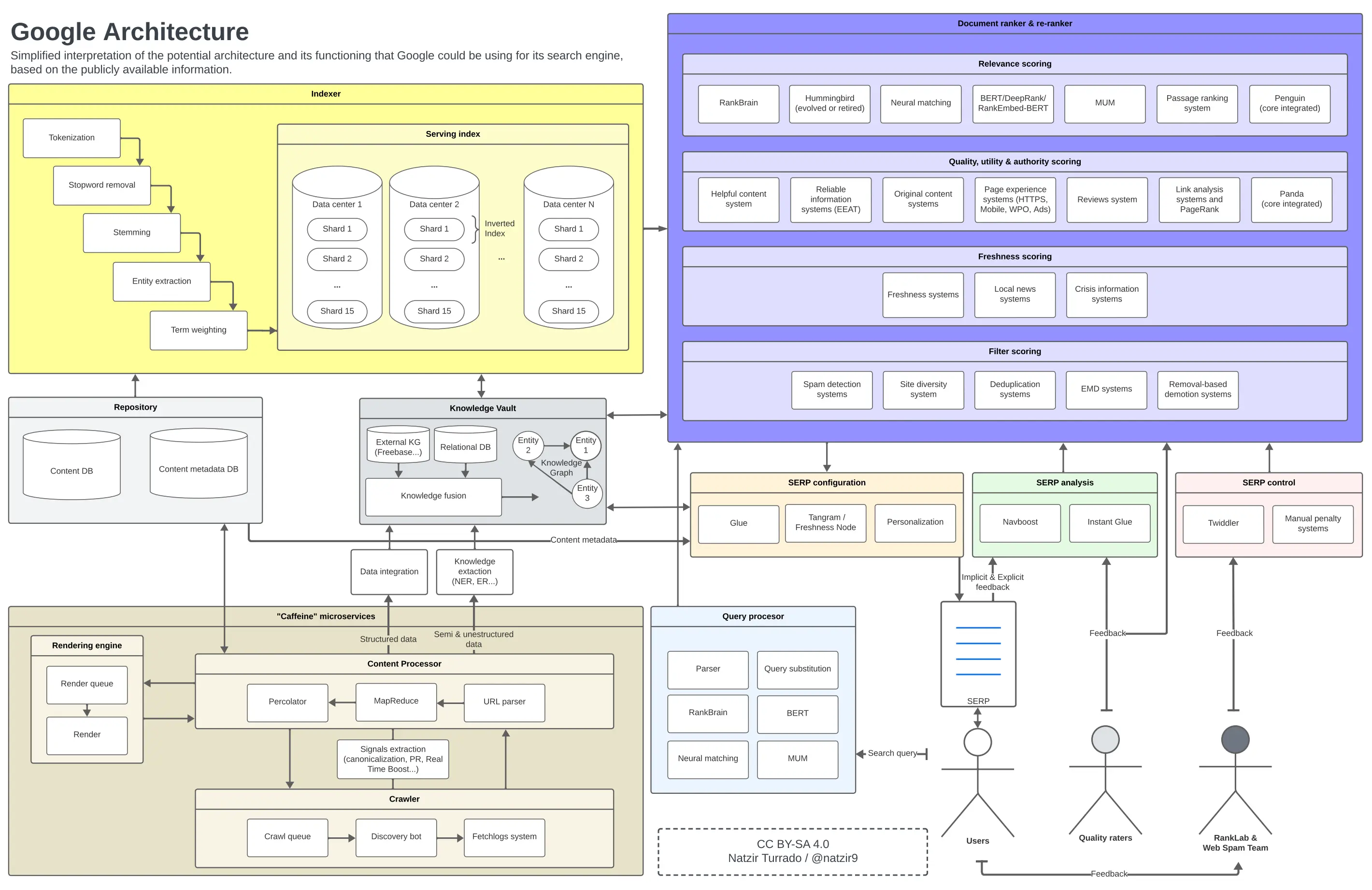
Google의 가능한 기능 및 구조. 이미지를 확대하려면 클릭하세요.
Google and Chrome: 기본 검색 엔진과 브라우저로서의 경쟁
이 마지막 섹션에서는 칼텍의 행동경제학자이자 교수인 전문가 증인 안토니오 랑겔의 증언에 집중하며, 내부 발표에서 사용된 기본 옵션의 사용자 선택에 미치는 영향에 대해 다루고 있으며, 구글의 기본 홈페이지의 전략적 가치에 관한 «On Strategic Value of Default Home Page to Google» 및 구글 부사장 짐 콜로투로스의 내부 이메일에서의 진술에 대해 언급합니다.
Jim Kolotouros가 내부 커뮤니케이션에서 밝힌 바에 따르면, Chrome은 브라우저뿐만 아니라 Google의 검색 우위 퍼즐에서 중요한 조각이다.
Google이 수집하는 데이터 중에는 검색 패턴, 검색 결과에 대한 클릭, 그리고 다양한 웹사이트와의 상호작용이 포함되는데, 이는 Google의 알고리즘을 개선하고 검색 결과의 정확도 및 타겟 광고의 효과를 향상시키는 데 중요합니다.
안토니오 랑겔에게 있어서 크롬의 시장 지배력은 인기를 뛰어넘는다. 크롬은 구글의 생태계로의 게이트웨이 역할을 하며, 사용자들이 정보와 온라인 서비스에 접근하는 방식에 영향을 미친다. 기본 검색 엔진으로서의 크롬의 구글 검색 통합은 구글에게 정보 및 디지털 광고의 흐름을 통제하는 중요한 이점을 제공한다.

구글의 인기에도 불구하고, Bing은 열등한 검색 엔진이 아닙니다. 그러나 많은 사용자들이 기본 설정 및 관련 인지적 편향의 편리함 때문에 구글을 선호합니다. 모바일 기기에서는 기본 검색 엔진의 영향이 변경하는 데 필요한 노력 때문에 더 강력합니다. 기본 검색 엔진을 변경하려면 최대 12번의 클릭이 필요합니다.

이 기본 설정은 소비자의 개인정보 결정에도 영향을 미칩니다. Google의 기본 개인정보 설정은 더 제한적인 데이터 수집을 선호하는 사람들에게 상당한 마찰을 제공합니다. 기본 옵션을 변경하려면 대안의 인식, 변경을 위한 필요한 단계 학습, 그리고 구현이 필요하며, 이는 상당한 마찰을 나타냅니다. 또한 상태 유지와 손실 회피와 같은 행동적 편향으로 사용자들은 Google의 기본 옵션을 유지하려는 경향이 있습니다. 여기에서 더 자세히 설명합니다
안토니오 랑겔의 증언은 구글 내부 분석 결과와 직접적으로 resonance를 보입니다. 이 문서는 브라우저의 홈페이지 설정이 검색 엔진의 시장 점유율과 사용자 행동에 상당한 영향을 미친다는 것을 밝혀냅니다. 구체적으로, 구글을 기본 홈페이지로 설정한 사용자들 중 상당 수가 구글에서 50% 더 많은 검색을 수행한다는 것을 보여줍니다.

이는 기본 홈페이지와 검색 엔진 선호도 간의 강한 상관 관계를 시사합니다. 또한 이 설정의 영향력은 지역에 따라 다양한데, 유럽, 중동, 아프리카, 라틴 아메리카 지역에서 뚜렷하며, 아시아-태평양 지역과 북미 지역에서는 그렇지 않습니다. 분석 결과에 따르면 구글은 홈페이지 설정의 변화에 상대적으로 취약하지 않으며, 야후와 MSN과 같은 경쟁사들보다 이 설정을 잃을 경우 상당한 손실을 입을 수 있습니다.

홈페이지 설정은 Google에게 시장 점유율을 유지하는 데 중요한 전략적 도구로 인식되며, 경쟁사에 대한 잠재적 취약성으로도 간주됩니다. 또한 대부분의 사용자가 검색 엔진을 능동적으로 선택하지 않고 홈페이지 설정에서 제공하는 기본 액세스에 기울이는 것을 강조합니다. 경제적으로, Google을 홈페이지로 설정할 경우 약 1인당 약 3달러의 증분 평생 가치가 추정됩니다.

결론
Google의 알고리즘과 내부 작동을 탐구한 후, 우리는 사용자 클릭과 인간 평가자가 검색 결과의 순위 매기기에 미치는 중요한 역할을 확인했습니다.
클릭은 사용자 선호도의 직접적인 지표로, Google이 응답의 관련성과 정확도를 지속적으로 조정하고 향상시키는 데 필수적입니다. 가끔씩 숫자가 맞지 않을 때는 반대를 원할 수도 있지만...
또한, 인간 평가자들은 인공지능 시대에도 여전히 필수적인 평가와 이해의 중요한 요소를 기여합니다. 개인적으로 이 부분에서 평가자들이 중요하다는 것은 알고 있었지만, 이 정도로 중요하다는 것에 매우 놀랍습니다.
이 두 가지 입력이 결합된 자동 피드백 및 인간 감독을 통해 Google은 검색 쿼리를 더 잘 이해할 뿐만 아니라 변화하는 트렌드와 정보 요구에 적응할 수 있게 됩니다. AI가 발전함에 따라 Google이 이러한 요소를 균형있게 유지하여 계속해서 개선하고 개인화된 검색 경험을 제공하는 방식을 보는 것은 흥미로울 것입니다. 이는 계속해서 변화하는 생태계와 개인정보 보호에 중점을 둔 환경에서의 일입니다.
한편, Chrome은 브라우저 이상의 역할을 합니다. 그것은 그들의 디지털 지배력의 중요한 구성 요소입니다. Google 검색과의 시너지와 많은 영역에서의 기본 구현은 시장 역학과 전체 디지털 환경에 영향을 미칩니다. 반독점 소송이 어떻게 끝나는지는 볼 것이지만, 그들은 10년 이상 독점적 지위 남용으로 약 100억 유로의 벌금을 내지 않았습니다.