본문은 주로 책 'Operating Systems: Three Easy Pieces'의 40장에서 '번역'되었습니다. 이 책은 운영 체제에 대해 혼란스러운 모든 학생들에게 추천되는 매우 깊이 있는 책입니다. 이 파일 시스템은 매우 작은 하드 드라이브 공간을 기반으로 하며 데이터 구조와 읽기/쓰기 프로세스를 중심으로 하여 각 기본 단계를 0에서 1로 유도합니다. 이를 통해 파일 시스템에 대한 직관을 빠르게 구축할 수 있습니다.
파일 시스템 대부분은 기본적으로 블록 스토리지 위에 구축됩니다. 그러나 현재 일부 분산 파일 시스템, 예를 들어 JuiceFS,는 객체 스토리지를 기반으로 합니다. 그러나 블록 스토리지나 객체 스토리지 모두 본질적으로 '데이터 블록'을 기반으로 주소 지정과 데이터 교환을 수행합니다.
먼저 하드 디스크에 대한 완전한 파일 시스템 데이터 구조, 즉 레이아웃에 대해 논의할 것이며, 그런 다음 여러 하위 모듈을 열고 닫고, 읽고 쓰는 프로세스를 통해 각 하위 모듈을 연결하여 파일 시스템의 주요 포인트를 완료할 것입니다.
저자: 목조조기 https://www.qtmuniao.com/2024/02/28/mini-filesystem 출처를 밝혀 주시기 바랍니다
本文来自我的大规模数据系统专栏《系统日知录》,专注存储、数据库、分布式系统、AI Infra 和计算机基础知识。欢迎订阅支持,解锁更多文章。你的支持,是我前行的最大动力。

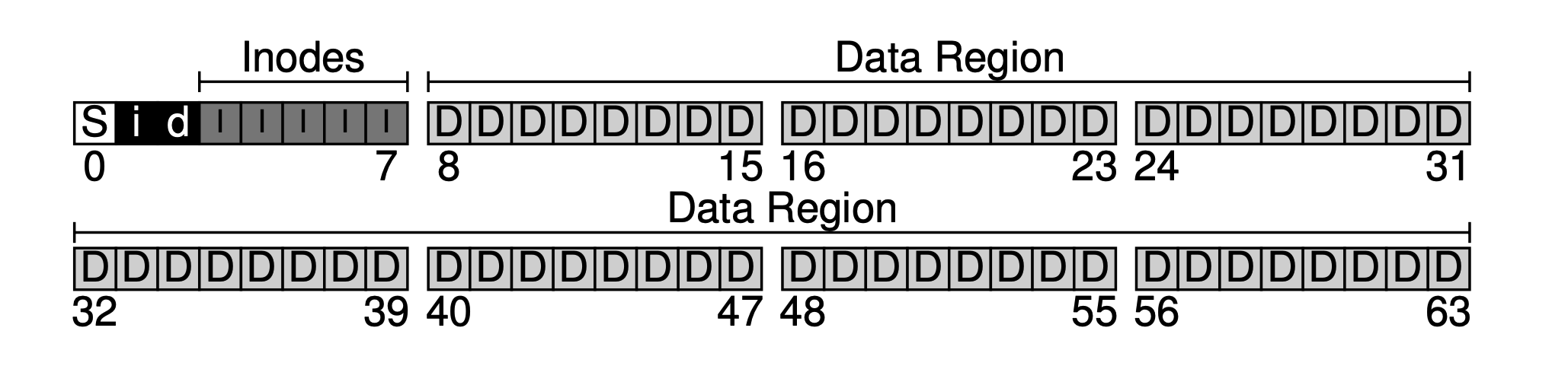
가정해보자. 블록 크기가 4KB이고, 매우 작은 하드 디스크가 있으며 블록이 64개뿐이다(따라서 총 크기는 64 imes 4KB = 256KB이다). 또한 이 하드 디스크는 파일 시스템에만 사용된다. 하드 디스크는 블록으로 주소 지정되므로 주소 공간은 0 extasciitilde63이다.
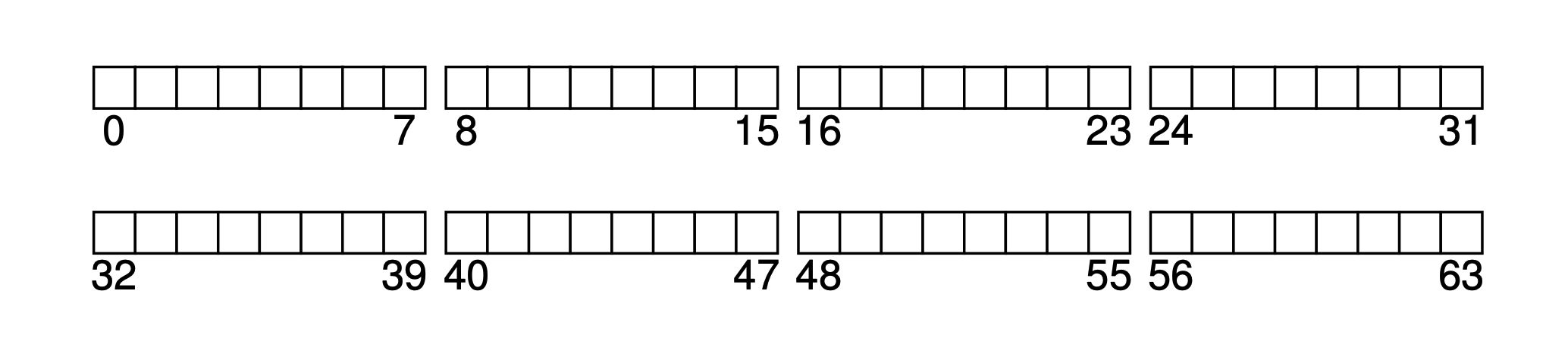
이 소형 하드 드라이브를 기반으로 우리는 이 간단한 파일 시스템을 단계별로 유도해 나갈 것입니다.
파일 시스템의 주요 목적은 분명히 사용자 데이터를 저장하는 것입니다. 이를 위해 디스크에 데이터 영역을 확보합니다. 우리는 뒤쪽 56개 블록을 데이터 영역으로 사용한다고 가정합니다. 왜 56개일까요? 뒤에서 알 수 있듯이, 사실 계산할 수 있습니다. 우리는 대략적으로 메타데이터와 실제 데이터의 비율을 계산할 수 있고, 이를 통해 두 부분의 크기를 결정할 수 있습니다.
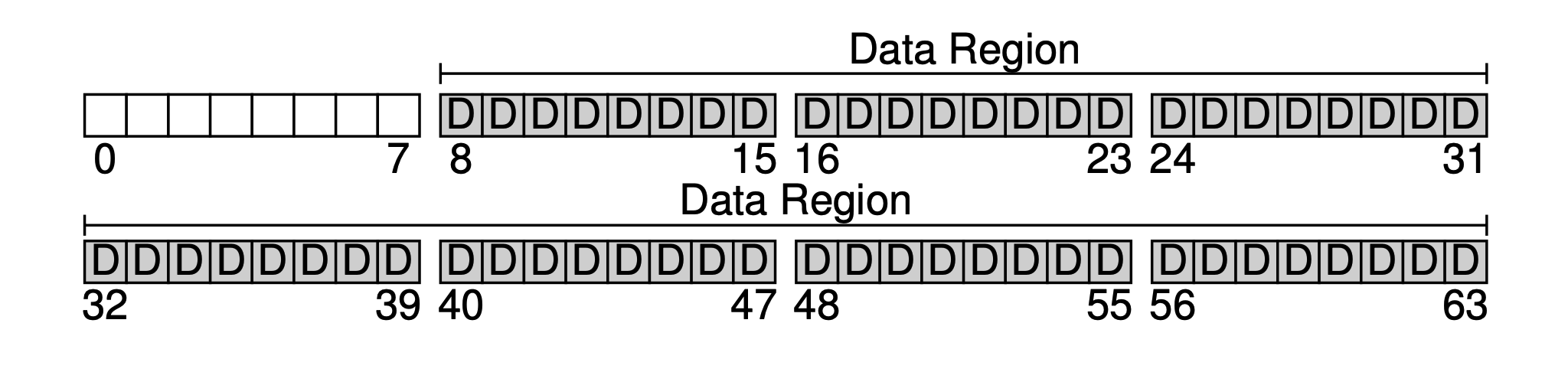
다음으로 시스템 내의 각 파일에 메타데이터를 저장해야 합니다. 예를 들어:
1. 파일 이름
2. 파일 크기
3. 파일 소유자
4. 액세스 권한
5. 생성, 수정 시간
등등. 이러한 메타데이터 블록을 보통 inode (index node)라고 합니다. 아래에서 inode에 5개의 블록을 할당합니다.
원본 텍스트가 ''와 유사한 경우 '['와 ']' 사이의 텍스트만 번역되고 다른 텍스트는 그대로 유지됩니다. # 元信息所占空间相对较小,比如 128B 或者 256B,我们这里假设每个 inode 占用 256B。则每个 4KB 块能容纳 16 个 inode,则我们的文件系统最多可以支持 5 * 16 = 80 个 inode,也即我们的迷你文件系统最多可以支持 80 个文件,但由于目录也要占 inode,所以实际可用文件数要少于 80。
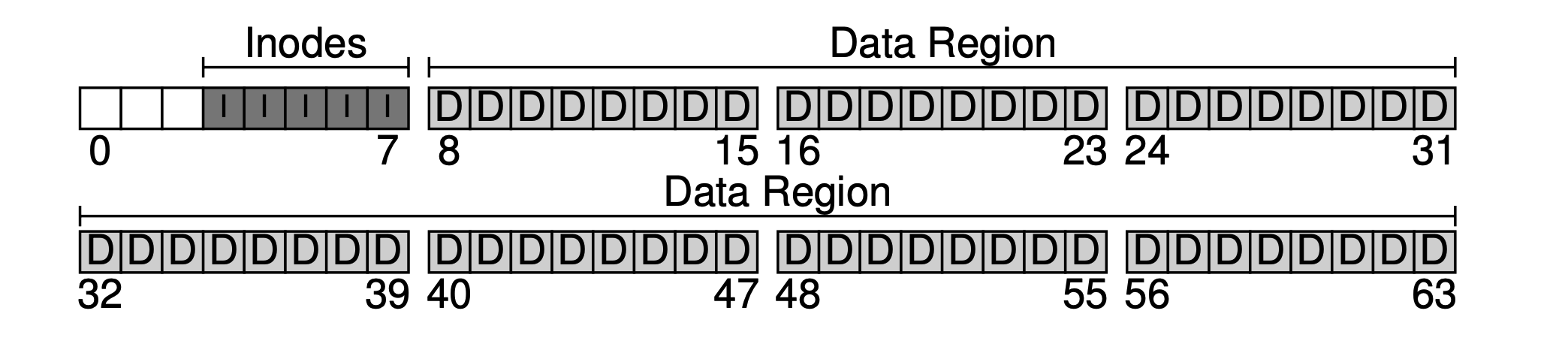
지금은 데이터 영역과 파일 메타데이터 영역이 있지만, 정상적으로 사용되는 파일 시스템에서는 어떤 데이터 블록이 사용되었는지, 어떤 것이 아직 사용되지 않았는지를 추적해야 합니다. 이러한 데이터 구조를 할당 구조(allocation structures)라고 합니다. 업계에서는 빈 공간 연결 리스트(free list)라는 일반적인 방법을 사용하여 모든 빈 블록을 연결 리스트로 구성합니다. 그러나 간단함을 위해 여기서는 비트맵(bitmap)이라는 더 간단한 데이터 구조를 사용합니다. 데이터 영역에는 하나가 있고, 데이터 비트맵(data bitmap)이라고 합니다. inode 테이블에는 하나가 있고, inode 비트맵(inode bitmap)이라고 합니다.
비트맵의 아이디어는 매우 간단합니다. 각 inode 또는 데이터 블록에 대해 하나의 데이터 비트를 사용하여 빈 여부를 표시합니다. 0은 빈 것을 나타내고 1은 데이터가 있는 것을 나타냅니다. 4KB의 비트맵은 최대 32K의 객체를 추적할 수 있습니다. 편의를 위해 inode 테이블과 데이터 풀에 각각 완전한 블록을 할당했으므로 아래 그림이 생겨났습니다.
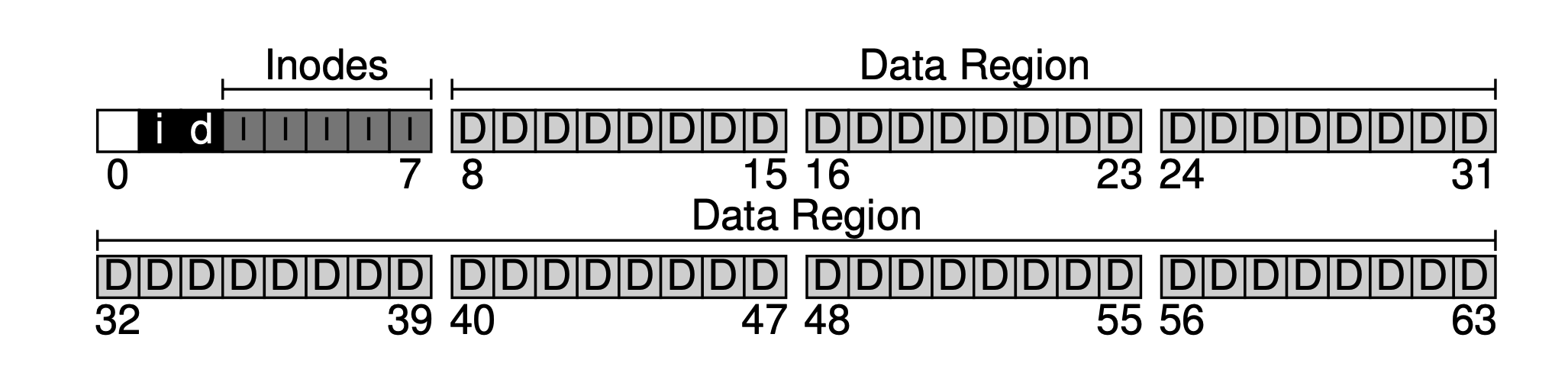
우리의 기본적인 접근 방식은 데이터 레이아웃을 뒤에서부터 진행하는 것이며, 마지막에는 하나의 블록이 남게 됩니다. 이 블록은 우리가 의도적으로 남겨둔 것으로, 파일 시스템의 슈퍼 블록(superblock)으로 사용됩니다. 슈퍼 블록은 파일 시스템의 진입점으로, 일반적으로 파일 시스템 수준의 메타 정보를 저장하며, 이 파일 시스템에는 몇 개의 inode와 데이터 블록(80과 56)이 있는지, inode 테이블의 시작 블록 오프셋(3) 등을 저장합니다.
파일 시스템이 마운트될 때 운영 체제는 먼저 슈퍼 블록을 읽고(따라서 맨 앞에 위치함) 이를 기반으로 일련의 매개변수를 초기화하고 파일 시스템 트리에 데이터 볼륨으로서 마운트합니다. 이러한 기본 정보를 갖고 있으면 해당 볼륨의 파일이 액세스될 때 위치를 찾아가며, 이후에 우리가 다룰 읽기 및 쓰기 프로세스를 이해할 수 있습니다.
하지만 읽기 및 쓰기 프로세스를 설명하기 전에, 먼저 몇 가지 핵심 데이터 구조를 확대하여 내부 레이아웃을 살펴볼 필요가 있습니다.
inode는 '인덱스 노드'의 줄임말로, 파일과 폴더의 인덱스 노드를 나타냅니다. 간단히 말해서, 우리는 배열을 사용하여 인덱스 노드를 구성합니다. 각 inode는 '번호' (inumber)에 연결되며, 이는 배열에서의 '색인' (오프셋)을 나타냅니다.
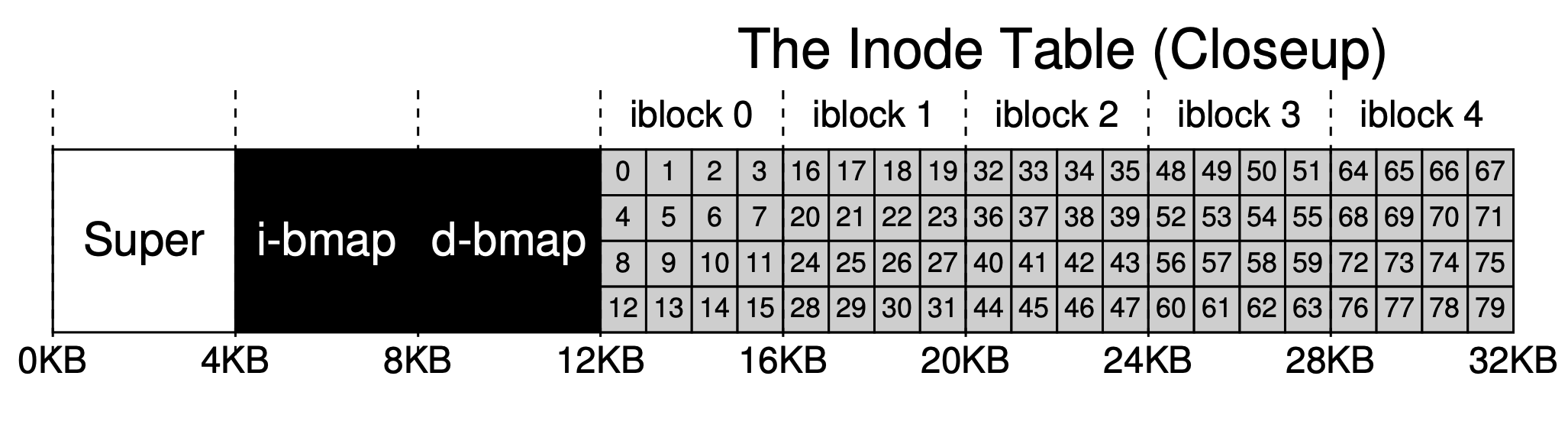
위에서 언급했듯이 각 inode는 256B를 차지합니다. 따라서 주어진 inumber에 대해 디스크에서의 오프셋을 계산할 수 있습니다(12KB + inumber * 256), 그러나 내부 및 외부 메모리 교환이 블록 단위로 이루어지므로 이를 통해 해당 디스크 블록을 계산할 수 있습니다.
inode는 주로 파일 이름, 일부 메타데이터(권한 제어, 다양한 이벤트, 일부 플래그) 및 데이터 블록 인덱스를 저장합니다. 데이터 블록 인덱스는 사실상 메타데이터이지만 중요하기 때문에 별도로 언급됩니다.
우리는 상대적으로 간단한 색인 방식을 사용합니다: 간접 포인터(indirect pointer)입니다. 즉, inode에 저장된 것은 데이터 블록을 직접 가리키는 포인터가 아니라 포인터 블록을 가리키는 것입니다(데이터 영역에도 할당되지만 모두 이중 포인터를 저장합니다). 파일이 충분히 크면 삼중 포인터도 발생할 수 있습니다(우리 이 작은 시스템에서 사용할 필요가 있는지 여부는 여러분이 추정할 수 있습니다).
그러나 우리의 조사 결과, 대부분의 파일 시스템에서는 작은 파일이 대부분을 차지하고 있습니다. 얼마나 작은지 궁금하신가요? 데이터 블록 하나에 저장할 수 있을 정도로 작습니다.

그래서 실제로 우리는 inode에서 직접 포인터와 간접 포인터를 혼합하여 표현하는 방식을 사용합니다. 우리 파일 시스템에서는 12개의 직접 포인터와 1개의 간접 포인터를 사용합니다. 따라서 파일 크기가 12개의 데이터 블록을 초과하지 않는 경우에는 직접 포인터를 직접 사용할 수 있습니다. 크기가 너무 커지면 간접 포인터를 사용하고, 데이터 영역에서 새로운 데이터 블록을 할당하여 간접 포인터에 데이터를 저장합니다.
우리의 데이터 영역은 매우 작습니다. 56개의 블록만 있으며, 4바이트 색인을 사용한다고 가정합니다. 따라서 이중 포인터는 최대 (12 + 1024)・4K를 지원할 수 있으며, 이는 4144KB 크기의 파일입니다.
또 다른 일반적인 방법은 데이터 영역(extents)이다. 각 연속된 데이터 영역을 시작 포인터와 크기로 표시하고, 그런 다음 파일의 모든 데이터 영역을 연결한다. 그러나 여러 개의 데이터 영역이 있는 경우, 마지막 데이터 영역에 액세스하거나 임의로 액세스하려면 성능이 매우 나빠질 수 있다(다음 데이터 영역의 포인터는 이전 데이터 영역에 저장되어 있기 때문). 액세스 속도를 최적화하기 위해 이 데이터 영역의 인덱스 연결 리스트를 메모리에 저장하는 것이 일반적이다. Windows의 초기 파일 시스템 FAT이 이렇게 동작한다.
우리 파일 시스템에서는 디렉토리 구조가 매우 간단합니다. 즉, 파일과 마찬가지로 각 디렉토리도 하나의 inode을 차지하지만, inode이 가리키는 데이터 블록은 파일 내용이 아니라 해당 디렉토리에 포함된 모든 파일과 폴더의 정보를 저장하며, 일반적으로 List<entry name, inode number>로 표시됩니다. 물론 실제 인코딩으로 변환하려면 파일 이름 길이 등의 정보도 저장해야 합니다(파일 이름이 가변적이기 때문에).
간단한 예를 살펴보겠습니다. 폴더 dir(아이노드 번호 5)가 있다고 가정해봅시다. 이 폴더 안에는 세 개의 파일(foor, bar, foobar)이 있고, 각각의 아이노드 번호는 12, 13, 24입니다. 이 폴더의 데이터 블록에 저장된 정보는 다음과 같습니다:

其中 reclen (record length)는 파일명이 차지하는 공간 크기이고, strlen은 실제 길이입니다. 점과 점점은 각각 현재 폴더와 상위 폴더를 가리키는 두 개의 포인터입니다. 레코드 reclen은 다소 불필요해 보일 수 있지만, 파일 삭제 문제를 고려해야 합니다(예를 들어 특정 inum(예: 0)을 사용하여 삭제를 표시할 수 있습니다). 폴더 내의 특정 파일 또는 디렉터리가 삭제되면 저장 공간에 빈 공간이 생깁니다. reclen의 존재로 삭제된 빈 공간을 이후에 추가된 파일이 재사용할 수 있습니다.
선형적으로 디렉토리의 파일을 구성하는 것이 가장 간단한 방법이라는 것을 설명해야 합니다. 실제로는 다른 방법도 있습니다. 예를 들어 XFS에서는 디렉토리에 파일이나 하위 폴더가 많을 경우 B+ 트리를 사용하여 구성합니다. 이렇게 하면 삽입할 때 동일한 이름의 파일이 있는지 빠르게 확인할 수 있습니다.
새 파일이나 디렉터리를 만들어야 할 때 파일 시스템에서 사용 가능한 공간을 얻어야 합니다. 따라서 빈 공간을 효율적으로 관리하는 것은 매우 중요한 문제입니다. 우리는 두 개의 비트맵을 사용하여 관리하는데, 장점은 간단하지만 단점은 매번 모든 빈 비트 위치를 선형으로 스캔하여 찾아야 하며 블록 단위로만 가능하고 블록 내에 여분 공간이 있으면 관리할 수 없다는 것입니다.
디스크 데이터 구조를 파악한 후에 읽기 및 쓰기 프로세스를 통해 다양한 데이터 구조를 연결합니다. 파일 시스템이 마운트되었다고 가정합니다: 즉, 슈퍼블록(superblock)이 이미 메모리에 존재합니다.
우리의 작업은 매우 간단합니다. 파일을 열고(예: /foo/bar), 읽은 후 닫습니다. 간단히 말해서, 파일 크기가 한 블록을 차지한다고 가정합니다. 즉, 4k입니다.
시스템 호출 'open("/foo/bar", O RDONLY)'을 시작할 때, 파일 시스템은 먼저 파일 bar에 해당하는 inode을 찾아 해당 파일의 메타데이터와 데이터 위치 정보를 얻어야 합니다. 그러나 우리는 현재 파일 경로만 가지고 있습니다. 어떻게 해야 할까요?
答曰:루트 디렉토리에서 아래로 순회합니다. 루트 디렉토리의 inode 번호는 슈퍼 블록에 저장되거나 하드코딩되어 있어야 합니다(예: 2, 대부분의 Unix 파일 시스템은 2부터 시작합니다). 즉, 사전에 알 수 있어야 합니다(well known).
파일 시스템은 루트 디렉터리의 inode를 하드 디스크에서 메모리로 로드하고, inode의 포인터를 통해 해당 데이터 블록을 찾아 모든 하위 디렉터리와 파일 중 'foo' 디렉터리와 해당 inode를 찾습니다. 이러한 과정을 재귀적으로 반복하여 open 시스템 호출의 마지막 단계는 'bar'의 inode를 메모리로 로드하고 권한 검사(프로세스 사용자 권한과 inode 접근 권한 제어 비교)를 수행하고 파일 디스크립터를 프로세스의 열린 파일 테이블에 할당하여 사용자에게 반환하는 것입니다.
한 번 파일이 열리면 read() 시스템 호출을 시작하여 실제 데이터를 읽을 수 있습니다. 읽을 때 먼저 파일의 inode 정보를 기반으로 첫 번째 블록을 찾아야 합니다(이전에 lseek()로 오프셋을 수정하지 않은 경우). 그런 다음 읽습니다. 동시에 inode의 일부 메타데이터를 변경할 수도 있습니다. 예를 들어 액세스 시간을 변경할 수 있습니다. 그런 다음 파일 기술자의 오프셋을 업데이트하고 계속해서 읽어야 합니다. 어느 시점에서 close()를 호출하여 파일 기술자를 닫아야 합니다.
프로세스가 파일을 닫을 때 필요한 작업은 훨씬 적습니다. 파일 디스크립터를 해제하는 것만으로 실제 디스크 IO가 발생하지 않습니다.
마지막으로, 파일 읽기 프로세스를 다시 한 번 정리해 봅시다. 루트 디렉터리의 inode 번호에서 시작하여 inode와 해당 데이터 블록을 번갈아 가며 읽어가면서 찾고자 하는 파일을 찾을 때까지 계속합니다. 그런 다음 데이터를 읽어야 하며, 해당 inode의 액세스 시간 등의 메타데이터를 업데이트하고 다시 써야 합니다. 아래 표는 이 프로세스를 간단히 요약한 것으로, 읽기 경로 전체에서 할당 구조 — 데이터 비트맵과 inode 비트맵 —에 관여하지 않음을 알 수 있습니다.
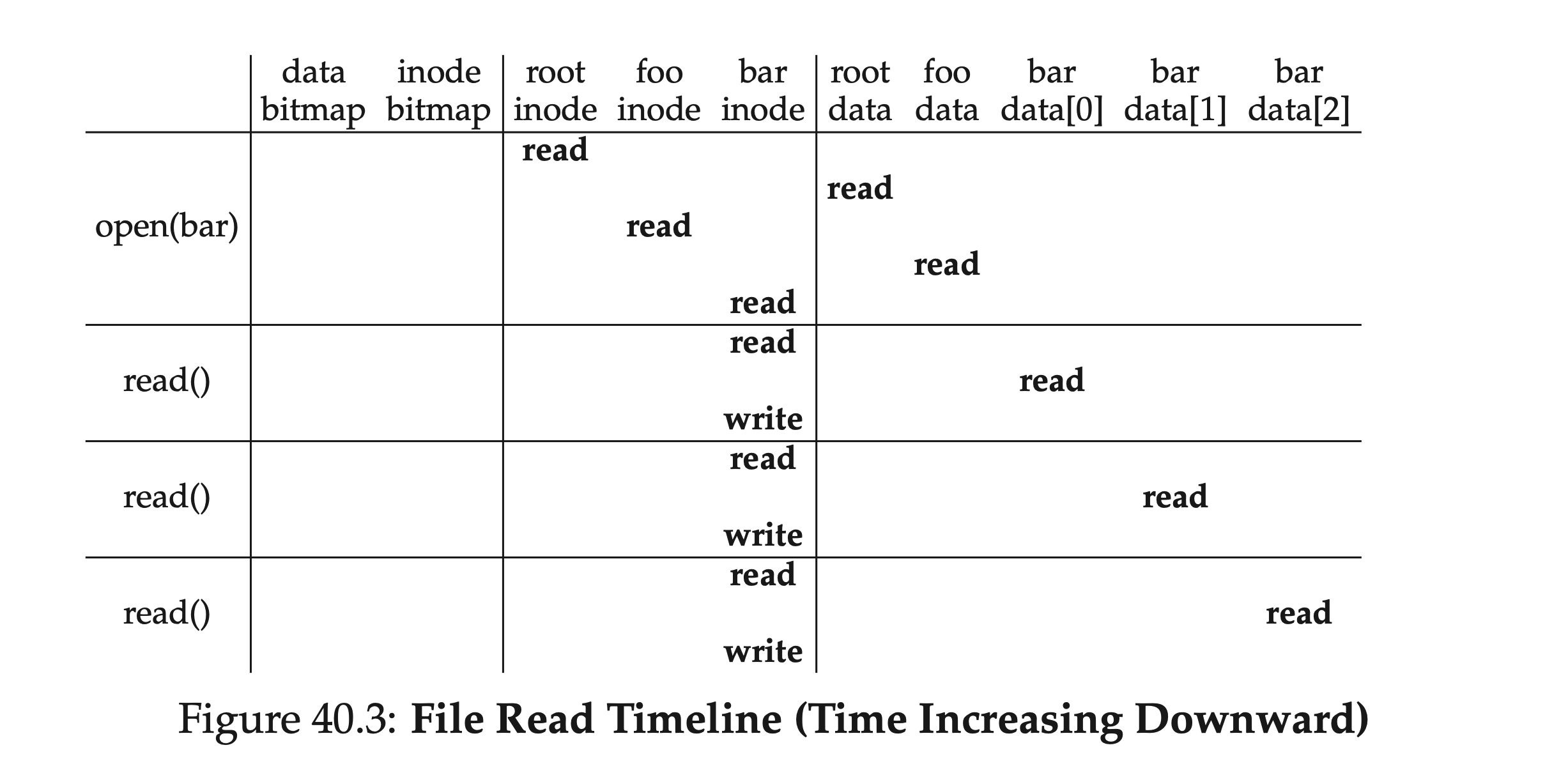
깊이 측면에서 말하면, 우리의 탐색 경로가 매우 많은 수준을 가지면, 이 과정은 선형적으로 증가할 것입니다; 폭 측면에서 말하면, 중간 탐색에 관련된 폴더가 포함하는 디렉토리 하위 항목이 매우 많다면, 즉 파일 트리가 '넓다'면, 각 디렉토리에서 탐색할 때마다 하나 이상의 데이터 블록을 읽어야 할 수도 있습니다.
파일 쓰기와 파일 읽기의 프로세스는 매우 유사하며 파일을 열고(루트 디렉터리에서 해당 파일을 찾음) 쓰기를 시작한 후에 마칩니다. 그러나 파일 읽기와 다른 점은 쓰기에는 새로운 데이터 블록을 할당해야 하며, 이는 이전에 언급한 비트맵과 관련이 있습니다. 일반적으로 한 번의 쓰기에는 적어도 다섯 번의 IO가 필요합니다:
- 데이터 비트맵을 읽어서(빈 블록을 찾고 메모리에서 사용으로 표시함)
- 데이터 비트맵을 다시 씀(다른 프로세스에서 볼 수 있도록)
- inode를 읽음(새로운 데이터 위치 포인터를 추가함)
- inode를 다시 씀
- 찾은 빈 블록에 데이터를 씀
이것은 이미 존재하는 파일에 대한 쓰기 작업에 대한 것입니다. 아직 존재하지 않는 파일을 만들고 쓰기 작업을 수행해야 하는 경우에는 더 복잡한 프로세스가 필요합니다. inode를 만들어야 하며, 이로 인해 일련의 새로운 IO가 발생합니다.
- inode 비트맵 읽기(빈 inode 찾기) 2. inode 비트맵 다시 쓰기(특정 inode이 사용됨으로 표시) 3. inode 자체 쓰기(초기화) 4. 부모 폴더에 대응하는 디렉토리 항목 데이터 블록의 읽기 및 쓰기(새로 생성된 파일 및 inode 추가) 5. 부모 폴더 inode의 읽기 및 쓰기(수정된 날짜 업데이트)
만약 상위 폴더의 데이터 블록이 부족하면 새로운 공간을 할당해야 하며, 이에 따라 데이터 비트맵과 데이터 블록을 다시 읽어야 합니다. 아래 그림은 '/foo/bar' 파일을 생성하는 과정에서 발생하는 IO를 보여줍니다:
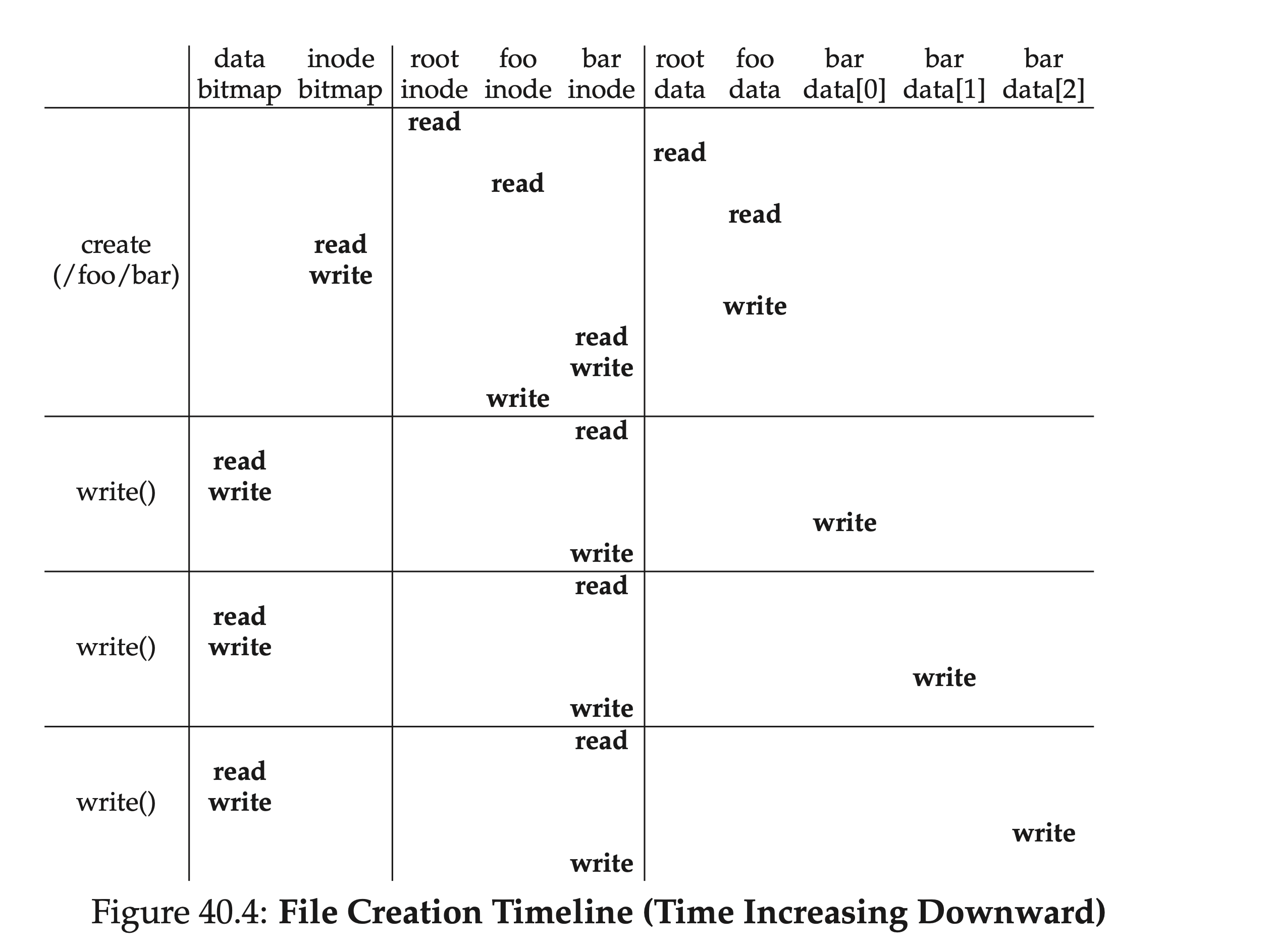
위에서의 읽기 및 쓰기 프로세스 분석에서, 심지어 이렇게 간단한 읽기 및 쓰기 작업도 많은 I/O를 필요로 한다는 것을 알 수 있습니다. 이는 실제로는 받아들일 수 없는 문제입니다. 이 문제를 해결하기 위해 대부분의 산업용 파일 시스템은 메모리를 최대한 활용하여 중요한(즉, 빈번하게 액세스되는) 데이터 블록을 메모리에 캐시하며, 동시에 빈번한 디스크 플러싱을 피하기 위해 수정 사항을 먼저 메모리 버퍼에 적용한 후 한꺼번에 디스크에 기록합니다.
이른 시기의 파일 시스템은 고정 크기 캐시를 도입했는데, 이 캐시가 가득 차면 LRU 등의 교체 알고리즘을 사용하여 페이지를 제거합니다. 이 방식의 단점은 캐시가 가득 차지 않은 경우에는 공간이 낭비되고, 가득 차면 페이지 교체가 빈번해진다는 것입니다. 이러한 스타일을 정적 분할이라고 합니다. 대부분의 현대 파일 시스템은 동적 분할 기술을 사용합니다. 예를 들어 가상 메모리 페이지와 파일 시스템 페이지를 하나의 풀에 넣어 통합 페이지 캐시로 만들어 두면 두 가지를 할당하는 것이 더 유연해집니다. 캐시를 사용하면 동일한 디렉토리에 있는 여러 파일을 읽을 때 뒤이어 나오는 읽기 작업에서 많은 IO를 절약할 수 있습니다.
전반부에서 경로를 통해 데이터 블록을 찾을 때 읽기가 관련되므로 캐시에서도 이점을 얻을 수 있습니다. 그러나 쓰기 부분에 대해서는 쓰기 버퍼링을 통해 디스크 플러시를 지연시킬 수 있습니다. 디스크 플러시를 지연시키는 것에는 여러 이점이 있습니다. 예를 들어 비트맵을 여러 번 수정해야 할 수도 있지만 한 번만 플러시하면 될 수 있습니다. 일괄 변경을 모아서 IO 대역폭 이용률을 높일 수 있습니다. 파일이 먼저 증가한 후 삭제되면 플러시를 아예 생략할 수도 있습니다.
하지만 이러한 성능 향상은 대가가 따릅니다 - 예기치 않은 시스템 다운으로 데이터 손실이 발생할 수 있습니다. 그래서 대부분의 현대 파일 시스템은 읽기-쓰기 캐시를 활성화하지만, 사용자가 캐시를 우회하고 직접 디스크에 쓰기 위해 직접 I/O를 통해 데이터를 쓸 수 있도록 합니다. 데이터 손실에 민감한 응용 프로그램은 해당 시스템 호출 'fsync()'를 사용하여 즉시 디스크를 플러시할 수 있습니다.
여기에는 번역된 텍스트가 들어갑니다. 파일 시스템의 구현을 위해 우리는 매우 간단한 파일 시스템을 완성했습니다. '작지만 모든 내장기관이 갖춰진 참새'처럼, 여기에서 우리는 파일 시스템 설계의 몇 가지 기본적인 개념을 볼 수 있습니다:
- inode를 사용하여 파일의 메타데이터를 저장하고, 데이터 블록을 사용하여 실제 파일 데이터를 저장합니다.
- 디렉토리는 특별한 종류의 파일로, 파일 내용이 아닌 폴더 하위 항목을 저장합니다.
- inode와 데이터 블록 외에도 비트맵과 같은 다른 데이터 구조가 필요합니다. 이는 빈 블록을 추적하는 데 사용됩니다.
이 기본 파일 시스템에서 출발하면 실제로 선택하고 최적화할 수 있는 많은 지점을 볼 수 있습니다. 관심이 있다면 여러분은 이 글을 기반으로 산업용 파일 시스템 설계를 살펴볼 수 있습니다.