Pandasは、高性能で使いやすいデータ構造とデータ分析ツールを提供するオープンソースのPythonライブラリです。そのコア機能の中で、Pandas DataFrameはPandasの最も重要なデータ構造の一つです。これは本質的に、異なるタイプのデータを持つ可能性のある列を持つ二次元のラベル付きデータ構造です。この記事では、包括的な例を用いてPandas DataFrameのさまざまな機能を探ります。
Pandas DataFrame 推奨記事
1. Pandas DataFrameの作成
Pandasを使用する際の最も基本的な操作の1つは、Pandas DataFrameを作成することです。リスト、辞書、さらには外部データファイルなど、さまざまなデータソースからPandas DataFrameを作成できます。
例 1: リストからPandas DataFrameを作成する
import pandas as pd
data = [['アレックス', 10], ['ボブ', 12], ['クラーク', 13]]
df = pd.DataFrame(data, columns=['名前', '年齢'])
print(df)
出力:

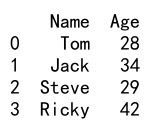
例2: 辞書からPandas DataFrameを作成する
import pandas as pd
data = {'名前': ['トム', 'ジャック', 'スティーブ', 'リッキー'],
'年齢': [28, 34, 29, 42]}
df = pd.DataFrame(data)
print(df)
出力:
- Pandas DataFrameでのデータの読み書き
Pandasは、CSV、Excel、SQLデータベースなど、さまざまなデータ形式からの読み取りおよび書き込みをサポートしています。
例 3: CSV からデータを読み込む
import pandas as pd
df = pd.read_csv('pandasdataframe.com_data.csv')
print(df)
例 4: Excel へのデータの書き込み
import pandas as pd
df = pd.DataFrame({'データ': [10, 20, 30, 20, 15, 30, 45]})
df.to_excel('pandasdataframe.com_output.xlsx', index=False)
- データの選択、追加、および削除 in Pandas DataFrame
データの操作は、Pandasを効果的に使用するための中心です。PandasのDataFrame内でデータを選択、追加、または削除することができます。
例 5: Pandas DataFrame で列によるデータの選択
import pandas as pd
data = {'名前': ['トム', 'ジェリー', 'ミッキー', 'ドナルド'],
'年齢': [25, 30, 35, 40]}
df = pd.DataFrame(data)
print(df['名前'])
出力:

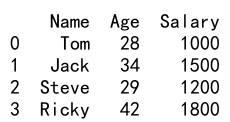
例6: Pandas DataFrameに新しい列を追加する
import pandas as pd
df = pd.DataFrame({'名前': ['トム', 'ジャック', 'スティーブ', 'リッキー'],
'年齢': [28, 34, 29, 42]})
df['給与'] = [1000, 1500, 1200, 1800]
print(df)
出力:
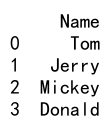
例 7: Pandas DataFrame での列の削除
import pandas as pd
data = {'名前': ['トム', 'ジェリー', 'ミッキー', 'ドナルド'],
'年齢': [25, 30, 35, 40]}
df = pd.DataFrame(data)
df.drop('年齢', axis=1, inplace=True)
print(df)
出力:
4. Pandas DataFrameにおける欠損データの処理
欠損データの処理は、データ分析のもう一つの重要な部分です。Pandasは、DataFrame内の欠損データを処理するためのいくつかのメソッドを提供しています。
例 8: Pandas DataFrameの欠損データの補填
import pandas as pd
import numpy as np
df = pd.DataFrame({'最初のスコア': [100, 90, np.nan, 95],
'二番目のスコア': [30, 45, 56, np.nan],
'三番目のスコア': [np.nan, 40, 80, 98]})
df.fillna(0, inplace=True)
print(df)
出力:

例 9: Pandas DataFrame における欠損データを持つ行の削除
import pandas as pd
import numpy as np
df = pd.DataFrame({'最初のスコア': [100, 90, np.nan, 95],
'二番目のスコア': [30, 45, 56, np.nan],
'三番目のスコア': [np.nan, 40, 80, 98]})
df.dropna(inplace=True)
print(df)
出力:
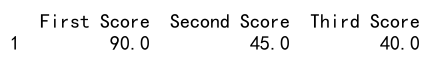
- パンダスデータフレーム操作
Pandas DataFramesは、データ分析や操作に非常に役立つさまざまな操作をサポートしています。
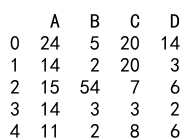
例 10: Pandas DataFrameでの算術演算の実行
import pandas as pd
df = pd.DataFrame({
'A': [14, 4, 5, 4, 1],
'B': [5, 2, 54, 3, 2],
'C': [20, 20, 7, 3, 8],
'D': [14, 3, 6, 2, 6]})
df['A'] = df['A'] + 10
print(df)
出力:
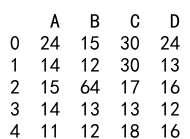
例 11: Pandas DataFrame にデータに関数を適用する
import pandas as pd
df = pd.DataFrame({
'A': [14, 4, 5, 4, 1],
'B': [5, 2, 54, 3, 2],
'C': [20, 20, 7, 3, 8],
'D': [14, 3, 6, 2, 6]})
df = df.apply(lambda x: x + 10)
print(df)
出力:
- Pandas DataFrameにおけるデータのグループ化と集約
データのグループ化と集約は、大規模なデータセットを扱うときや、カテゴリ化されたデータに対して操作を行う必要があるときに不可欠です。
例 12: Pandas DataFrameでの列によるデータのグループ化
import pandas as pd
data = {'会社': ['Google', 'Google', 'Microsoft', 'Microsoft', 'Facebook', 'Facebook'],
'人物': ['Sam', 'Charlie', 'Amy', 'Vanessa', 'Carl', 'Sarah'],
'売上': [200, 120, 340, 124, 243, 350]}
df = pd.DataFrame(data)
grouped_df = df.groupby('会社')
print(grouped_df.mean())
例 13: Pandas DataFrameで複数の関数を使用してデータを集約する
import pandas as pd
data = {'会社': ['Google', 'Google', 'Microsoft', 'Microsoft', 'Facebook', 'Facebook'],
'人物': ['Sam', 'Charlie', 'Amy', 'Vanessa', 'Carl', 'Sarah'],
'売上': [200, 120, 340, 124, 243, 350]}
df = pd.DataFrame(data)
grouped_df = df.groupby('会社').agg({'売上': ['平均', '合計']})
print(grouped_df)