Contents
検索エンジンが何であり、なぜ存在し、どのようにして収益を上げるのかを探求することから始めましょう。
検索エンジンとは何ですか?
検索エンジンはウェブコンテンツの検索可能なデータベースです。主要な部分は2つあります:
- 検索インデックス。 ウェブページに関する情報のデジタルライブラリー。 2. 検索アルゴリズム。 検索インデックスからの結果を一致させるためのコンピュータプログラム。
検索エンジンの目的は何ですか?
すべての検索エンジンは、ユーザーにとって最良で最も関連性の高い検索結果を提供することを目指しています。それが彼らが市場シェアを獲得する一因です。
検索エンジンはどのようにしてお金を稼ぐのか?
検索エンジンには2種類の検索結果があります:
- 検索インデックスからの有機的な結果。 ここに掲載されるためにはお金を支払うことはできません。 2. 広告主からの有料結果。 ここに掲載されるためにはお金を支払うことができます。
誰かが有料検索結果をクリックするたびに、広告主は検索エンジンに支払います。これがペイ・パー・クリック(PPC)広告と呼ばれるものであり、それが市場シェアの重要性です。ユーザーが多ければ多いほど、広告のクリック数と収益が増えます。

各検索エンジンには、独自の検索インデックスを構築するためのプロセスがあります。以下は、Googleが使用するプロセスの簡略化バージョンです。1
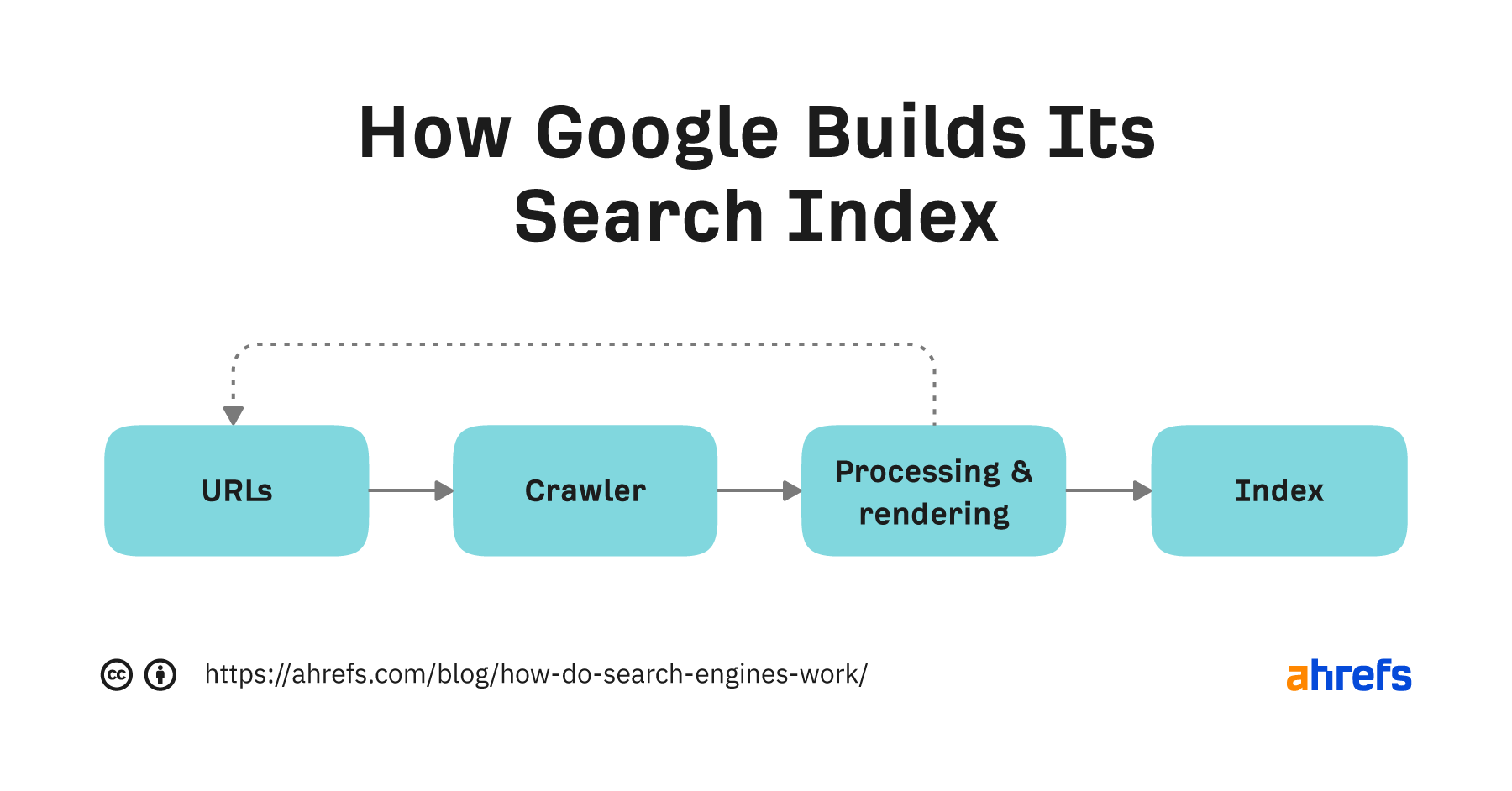
Let’s break it down.
URL
すべては既知のURLリストから始まります。Googleはこれらをさまざまな方法で発見しますが、最も一般的なのは次の3つです:
- バックリンクから。 Googleは数百億のウェブページをインデックス化しています。
- サイトマップから。 サイトマップは、サイト上で重要だと思われるページやファイルをGoogleに伝えます。
- URLの提出から。 Googleはサイト所有者に個々のURLのクロールをリクエストすることを許可しています。Google Search Consoleで。
クローリング
Crawling is where a computer bot called a spider visits and downloads known URLs. Google’s crawler is Googlebot. [4]
処理とレンダリング
処理はGoogleがクロールされたページから重要な情報を理解し抽出する作業です。これにはページをレンダリングして、ユーザーにとってどのように見えるかを理解するためにページのコードを実行する必要があります。
Googleの外の誰もがこのプロセスのすべての詳細を知っているわけではありません。しかし、それは重要ではありません。私たちが本当に知る必要があることは、リンクを抽出し、コンテンツをインデックス用に保存することが含まれているということです。
インデックス
インデックス作成は、クロールされたページから処理された情報が検索インデックスに追加される場所です。
検索インデックスは、検索エンジンを使用する際に検索するものです。そのため、GoogleやBingなどの主要な検索エンジンにインデックスされることは非常に重要です。インデックスにないと、ユーザーはあなたを見つけることができません。
知っていましたか?
Googleは検索エンジン市場の91.43%を所有しています。他の検索エンジンよりも多くのトラフィックを送ることができます。なぜなら、ほとんどの人がそれを使用しているからです。[5]
コンテンツの発見、クローリング、およびインデックス作成は、パズルの最初の部分に過ぎません。検索エンジンは、ユーザーが検索を実行したときに一致する結果をランク付けする方法も必要です。これが検索アルゴリズムの役割です。
検索アルゴリズムとは何ですか?
検索アルゴリズムは、インデックスから関連する結果を一致させてランク付けするための数式です。Googleはそのアルゴリズムに多くの要因を使用しています。
キーGoogleランキング要因
Googleのランキング要因をすべて把握している人は誰もいません。なぜならGoogleがそれらを開示していないからです。しかし、いくつかの重要な要因はわかっています。それらをいくつか見てみましょう。
バックリンク
バックリンクとは、あるウェブサイトのページから別のウェブサイトへのリンクのことです。これはGoogleの最も強力なランキング要因の1つです。私たちが10億ページ以上の調査でリンクドメインと有機トラフィックの間に強い相関関係を見たのはおそらくそのためです。
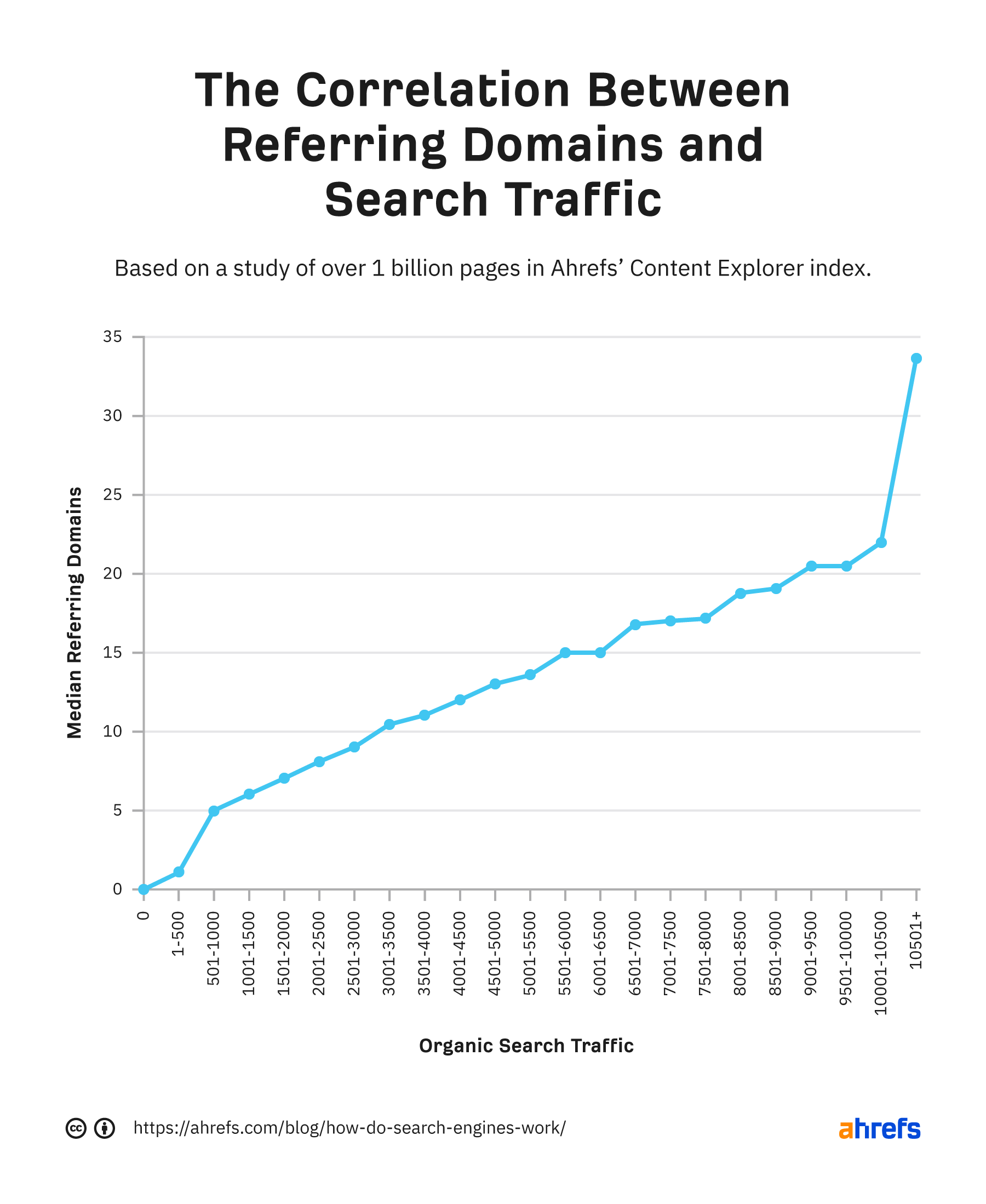
ただし、すべてが量だけではありません。品質も重要です。高品質なバックリンクがいくつかあるページは、低品質なバックリンクが多いページよりも順位が上がることがよくあります。
Did you know?
Ahrefsで無料でウェブサイトのバックリンクをチェックできます。
無料のAhrefs Webmaster Toolsアカウントにサインアップし、Site Explorerにドメインを入力し、Backlinksレポートに移動します。
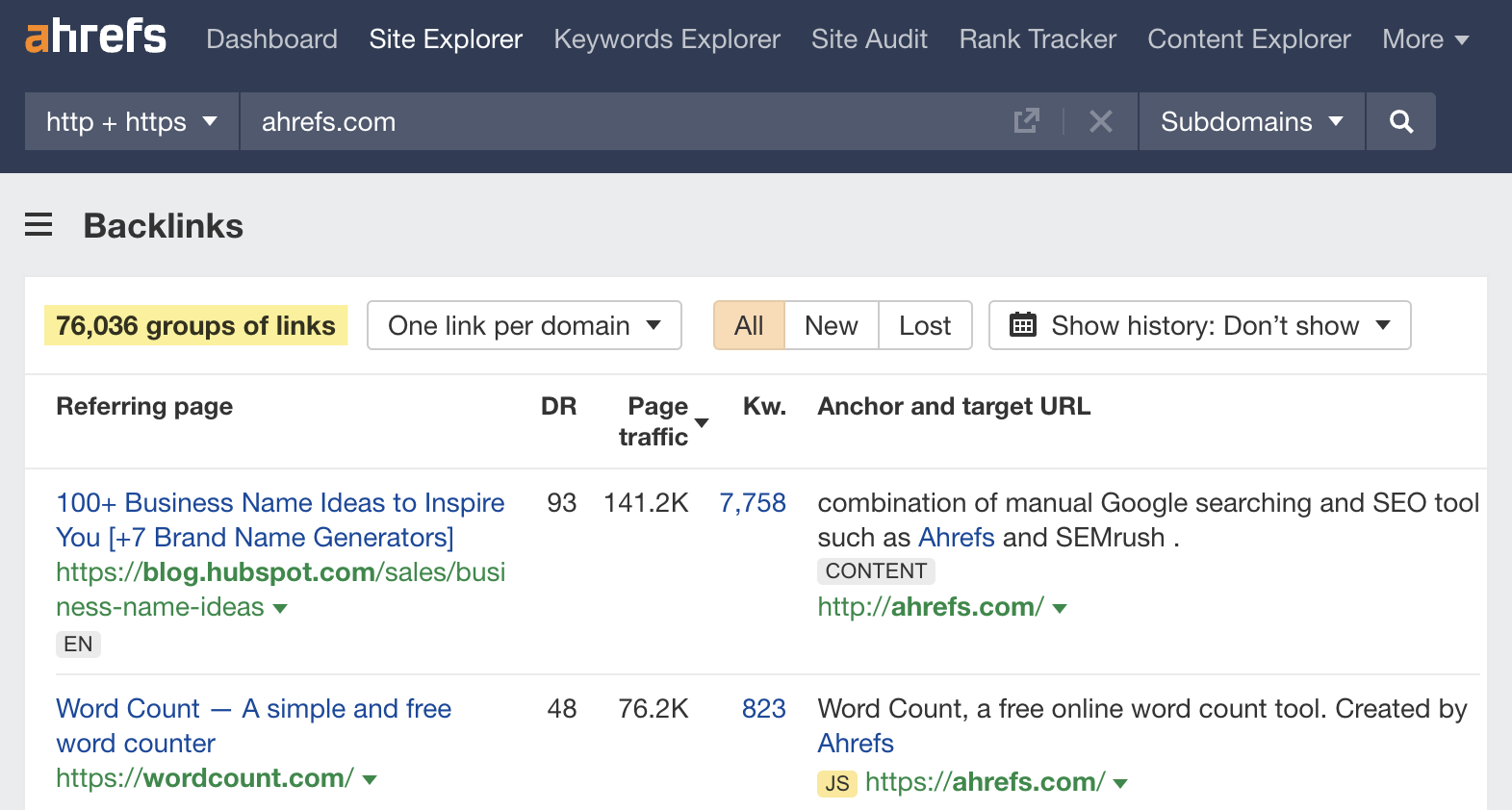
私たちのクローラーはWeb上で5番目にアクティブなので、ここではバックリンクのかなり完全なビューが表示されます。[8]
関連性
関連性とは、検索者にとって与えられた結果の有用性です。Googleにはこれを判断するための多くの方法があります。基本的なレベルでは、検索クエリと同じキーワードを含むページを探します。また、他の人がその結果を有用だと感じたかどうかを確認するために、相互作用データも見ています。[9]