この記事では、私たちが日常的に使用しているツールであるGoogleの内部機能について掘り下げます。最近の反トラスト訴訟での文書の流出を受けて、私たちはGoogleのアルゴリズムを探るユニークな機会を得ました。これらのアルゴリズムの一部はすでに知られていましたが、興味深いのはこれまで私たちと共有されていなかった内部情報です。
これらの技術がどのように私たちの検索を処理し、私たちが見る結果を決定するかを検証します。この分析では、各Google検索の背後にある複雑なシステムの明確で詳細なビューを提供することを目指しています。
さらに、新しい発見を考慮に入れながら、Googleのアーキテクチャを図で表現しようと思います。
最初に、2つの文書に言及されているすべてのアルゴリズムを抽出することに焦点を当てます。最初の文書はPandu Nayakの証言についてです(AlphabetのVP)そして2番目はProfessor Douglas W. Oardの反証証言についてです。これはGoogleの専門家であるEdward A. Fox教授が2022年6月3日付けの報告書で提供した意見に関するものです。後者の文書では、Googleが実験データを操作して、ユーザーデータが彼らにとってそれほど重要ではないことを証明しようとしたという有名で論争のある「Fox Report」について議論されました。
公式情報が利用可能な場合は、各アルゴリズムを説明し、その後に試行から抽出した情報を画像にまとめます。

Navboost
Googleの重要なキーであり、最も重要な要因の1つです。これはまた、Paul Haarが自分の履歴書に追加したため、2019年の「Project Veritas」のリークでも明らかになりました。2019 «Project Veritas» leak

Navboostは、ユーザーが異なるクエリに対するクリックを通じて検索結果とのやり取りをどのように行うかに関するデータを収集します。このシステムはクリックを集計し、人間による品質評価から学習するアルゴリズムを使用して検索結果のランキングを改善します。アイデアは、特定のクエリに対して結果が頻繁に選択され(そして肯定的に評価される)場合、その結果はおそらくより高いランキングを持つべきであるというものです。興味深いことに、Googleは多くの年前にNavboostを削除する実験を行い、その結果が悪化したことがわかりました。

ランクブレイン
2015年に開始されたRankBrainは、GoogleのAIおよび機械学習システムであり、検索結果の処理に不可欠です。機械学習を通じて、言語理解能力と検索意図の向上を継続的に行い、曖昧または複雑なクエリの解釈に特に効果的です。コンテンツとリンクに続いて、Googleのランキングで3番目に重要な要素とされています。Tensor Processing Unit (TPU)を使用して、処理能力とエネルギー効率を大幅に向上させています。

私はQBSTとTerm WeightingがRankBrainの構成要素であると推測します。ですので、ここに含めます。
QBTS(Query Based Salient Terms)は、クエリと関連文書内の最も重要な用語に焦点を当て、この情報を使用して結果のランク付けに影響を与えます。これにより、検索エンジンはユーザーのクエリの最も重要な側面を迅速に認識し、関連する結果を優先的に表示できます。たとえば、これは曖昧または複雑なクエリに特に役立ちます。
証言書には、QBSTがBERTの制限の文脈で言及されています。具体的な言及は、「BERTはnavboost、QBSTなどの大規模な記憶システムを包摂しない」というものです。つまり、BERTは自然言語の理解と処理に非常に効果的である一方、QBSTのような大規模な記憶システムを処理または置換する能力には制限があるということです。

用語の重み付けは、ユーザーが検索結果とやり取りする方法に基づいて、クエリ内の個々の用語の相対的な重要性を調整します。これにより、クエリの文脈で特定の用語がどれだけ関連性があるかを判断するのに役立ちます。この重み付けは、検索エンジンのデータベース内で非常に一般的または非常に稀な用語を効率的に処理し、結果をバランスよく取り扱います。

DeepRank
自然言語の理解において一歩進んでおり、検索エンジンがクエリの意図と文脈をより良く理解できるようになっています。これはBERTのおかげで実現されており、実際にはDeepRankはBERTの内部名です。大量のドキュメントデータで事前トレーニングを行い、クリックや人間の評価からのフィードバックで調整することで、DeepRankは検索結果をより直感的でユーザーが実際に求めているものに関連性のあるものに微調整することができます。

RankEmbed
RankEmbedはおそらくランキングのための関連する特徴を埋め込むことに焦点を当てています。文書にはその機能や能力について具体的な詳細はありませんが、Googleの検索分類プロセスを改善するために設計されたディープラーニングシステムであると推測できます。
RankEmbed-BERT
RankEmbed-BERTは、RankEmbedのアルゴリズムと構造を統合した強化版であり、BERTの統合によりRankEmbedの言語理解能力を大幅に向上させました。最新のデータで再トレーニングされないと、その効果は低下する可能性があります。トレーニングには、利用可能なデータをすべて使用する必要はないことを示す、わずかなトラフィックのみを使用しています。
RankEmbed-BERTは、RankBrainやDeepRankなどの他のディープラーニングモデルとともに、Googleの検索システムの最終的なランキングスコアに貢献しますが、結果の初期取得後に動作します(再ランキング)。クリックとクエリデータで訓練され、人間の評価者(IS)からのデータを使用して微調整されており、RankBrainなどのフィードフォワードモデルよりも訓練には計算コストが高くなります。

MUM
MUMは、おおよそBERTよりも1,000倍強力であり、Googleの検索における重要な進歩を表しています。2021年6月に発表され、75言語を理解するだけでなく、マルチモーダルでもあり、異なる形式の情報を解釈し処理することができます。このマルチモーダルな能力により、MUMはより包括的で文脈に即した回答を提供し、詳細な情報を得るための複数の検索の必要性を減らします。ただし、その使用は高い計算要求のため非常に選択的です。

タングラムとグルー
すべてのこれらのシステムは、Tangramの枠組み内で連携して動作し、Glueからのデータを使用してSERPを構築する責任があります。これは単なる結果のランキングの問題ではなく、画像カルーセル、直接回答、およびその他の非テキスト要素などの要素を考慮して、ユーザーにとって有用でアクセスしやすい方法でそれらを整理することです。

最後に、Freshness Node と Instant Glue は、結果が最新であることを保証し、特にニュースや現在の出来事に関する検索において最新情報に重点を置きます。

裁判では、攻撃に言及し、クエリの主な意図が攻撃の日に変わり、インスタントグルーが一般的な画像を抑制してタングラムに変え、代わりにニースから関連するニュースや写真を促進することになりました(「nice pictures」対「Nice pictures」):

これらすべてを考慮に入れると、Googleはこれらのアルゴリズムを組み合わせるでしょう:
- クエリの理解: ユーザーが検索バーに入力した単語やフレーズの意図を解読する。
- 関連性の判定: 過去の相互作用や品質評価からのシグナルを使用して、コンテンツがクエリにどのように一致するかに基づいて結果をランク付けする。
- 新鮮さの優先: 重要な場合には、最新で最も関連性のある情報がランキングで上昇するようにする。
- 結果の個別化: クエリだけでなく、ユーザーの場所や使用しているデバイスなど、ユーザーのコンテキストにも検索結果を適合させる。これ以上の個別化はほとんどない。
これまでに見てきたすべての情報から、私はTangram、Glue、およびRankEmbed-BERTが、現時点で唯一の新しいアイテムであると信じています。
これらのアルゴリズムは、さまざまなメトリクスによって育まれており、今回は再び試行から情報を抽出して、それらを詳しく説明します。
Googleが検索品質を評価するために使用するメトリクス
このセクションでは、再びダグラス・W・オード教授の反証証言に焦点を当て、以前のリーク情報である「Project Veritas」のものも含めます。
スライドの1つで、Googleは、検索結果のランキングに影響する要因を開発および調整するために使用するメトリクスと、アルゴリズムの変更が検索結果の品質にどのように影響するかを監視するために以下のメトリクスを使用していることが示されました。その目標は、これらのメトリクスを使用してユーザーの意図を捉えようとすることです。
1. IS スコア
人間の評価者は、Googleの検索製品の開発と改良において重要な役割を果たしています。彼らの作業により、評価者の評価から生成される「ISスコア」(0から100までの情報満足度スコア)という指標がGoogleの品質の主要な指標として使用されています。
それは匿名で評価され、評価者はGoogleかBingをテストしているかどうかを知らないため、Googleのパフォーマンスを主要な競合他社と比較するために使用されます。
これらのISスコアは、認識された品質を反映するだけでなく、RankBrainやRankEmbed BERTなどの分類アルゴリズムを含むGoogleの検索システム内のさまざまなモデルのトレーニングにも使用されています。
2021年時点で、彼らはIS4を使用しています。IS4はユーティリティの近似値と見なされ、そのように扱われるべきです。 これはおそらく最も重要なランキング指標とされていますが、近似値であり、後で議論するエラーの影響を受けやすいと強調されています。

この指標の派生であるIS4@5についても言及されています。
IS4@5メトリックは、Googleが検索結果の品質を測定するために使用され、特に最初の5つの位置に焦点を当てています。このメトリックには、OneBoxes(通称「青いリンク」)などの特別な検索機能も含まれます。このメトリックのバリアントとして、IS4@5 webというものがあり、これは広告などの他の要素を除外し、最初の5つのウェブ検索結果の評価に焦点を当てています。

IS4@5は検索結果の上位の品質と関連性を迅速に評価するために有用ですが、その範囲は限られています。検索品質のすべての側面をカバーしておらず、特に検索結果に含まれる広告などの要素を省いています。そのため、この指標は検索品質の一部の観点を提供します。Googleの検索結果の品質を完全かつ正確に評価するには、体重だけでなく様々な指標によって一般的な健康状態が評価されるように、より広範囲の指標や要因を考慮する必要があります。
人間評価者の制限
評価者は、技術的なクエリの理解や製品の人気の判断、クエリの解釈など、いくつかの問題に直面しています。さらに、MUMのような言語モデルは、言語とグローバルな知識を人間の評価者と同様に理解する可能性があり、関連性評価の将来にとって機会と課題の両方を提起しています。
重要性にもかかわらず、彼らの視点は実際のユーザーとは大きく異なる。評価者は、クエリトピックに関連する特定の知識や過去の経験がない可能性があり、これが関連性や検索結果の品質の評価に影響を与える可能性があります。
2018年と2021年の流出文書から、Googleが内部プレゼンテーションで認識しているすべてのエラーのリストをまとめることができました。
- 時間的不一致: クエリ、評価、およびドキュメントが異なる時期のものであるため、ドキュメントの現在の関連性を正確に反映しない評価が生じる可能性があります。
- 評価の再利用: 評価を再利用して迅速に評価し、コストを管理することは、コンテンツの現在の新鮮さや関連性を代表していない評価をもたらす可能性があります。
- 技術的なクエリの理解: 評価者が技術的なクエリを理解していないため、専門的またはニッチなトピックの関連性を評価する際に困難が生じる可能性があります。
- 人気の評価: 競合するクエリの解釈や競合製品の人気を評価者が判断することには固有の難しさがあり、これが評価の正確性に影響を与える可能性があります。
- 評価者の多様性: 一部の地域の評価者の多様性の不足や、全員が大人であることは、未成年を含むGoogleのユーザーベースの多様性を反映していない可能性があります。
- ユーザー生成コンテンツ: 評価者はユーザー生成コンテンツに厳しい傾向があり、有用で関連性のあるにもかかわらず、その価値を過小評価する可能性があります。
- 新鮮さノードのトレーニング: 適切なトレーニングラベルの不足により、新鮮さモデルの調整に問題があることを示しています。人間の評価者は、関連性の新鮮さに十分な注意を払わないことが多く、クエリの時間的コンテキストが不足しています。これにより、新規性を求めるクエリの最新の結果が過小評価されることがあります。既存のISに基づくRelevanceおよびその他のスコアリング曲線をトレーニングするために使用されるTangram Utilityは、同じ問題に苦しんでいました。人間のラベルの制限により、新鮮さノードのスコアリング曲線は最初のリリース時に手動で調整されました。
私は真剣に信じています。人間の評価者が「Parasite SEO」の効果的な機能に責任を持っていると。ダニー・サリバンの注意を引いたことが、このツイートで共有されています。

最新の品質ガイドラインの変更を見ると、彼らがついにNeeds Metメトリクスの定義を調整し、評価者が考慮すべき新しい例を含めた方法がわかります。たとえ結果が信頼性のあるものであっても、ユーザーが求めている情報を含んでいない場合、高く評価すべきではありません。

Google Notesの新しいローンチは、私が考えるに、この理由も指し示しています。Googleは100%の確実さで何が質の高いコンテンツであるかを知ることができないのです。

私は、ほぼ同時に発生したこれらの出来事は偶然ではないと信じており、近いうちに変化が訪れると考えています。
2. PQ (Page Quality)
ここで私は彼らがページ品質について話していると推測していますので、これが私の解釈です。もしそうなら、試行文書には使用されたメトリックとしての言及以外には何もありません。PQについて唯一公式のものは、Search Quality Rater Guidelinesからで、時間とともに変化します。したがって、これは人間の評価者にとって別のタスクになるでしょう。

この情報はアルゴリズムにも送信され、モデルを作成するために使用されます。ここでは、これが「Project Veritas」でリークされた提案を見ることができます。

ここで興味深い点は、文書によると、品質評価者はモバイル上でのページのみを評価するとされています。

3. サイドバイサイド
これはおそらく、2つの検索結果セットを並べて、評価者がそれらの相対的な品質を比較できるテストを指していると思われます。これにより、特定の検索クエリに対してより関連性の高いまたは有用な結果セットを特定するのに役立ちます。その場合、Googleは独自のダウンロード可能なツールであるsxseを持っていたと記憶しています。

ユーザーは好みの検索結果セットに投票できるため、異なる調整やバージョンの検索システムの効果について直接フィードバックを提供できます。
4. ライブ実験
How Search Worksで公開された公式情報によると、Googleは新機能が全員に展開される前に、実際のトラフィックを使用して人々が新機能とどのようにやり取りするかをテストするための実験を行っています。彼らは新機能を一部のユーザーに対して有効化し、その挙動を持たないコントロールグループと比較します。検索結果へのユーザーのやり取りに関する詳細なメトリクスには次のようなものがあります:
- 結果をクリックする回数
- 実行された検索の数
- クエリの放棄
- 結果をクリックするまでの時間
このデータは、新機能との相互作用が肯定的であるかどうかを測定し、変更が検索結果の関連性と有用性を高めることを確認するのに役立ちます。
しかし、裁判の文書では2つの指標のみが強調されています:

- 位置加重長押し: この指標はクリックの期間と結果ページ上の位置を考慮し、ユーザーが見つけた結果に対する満足度を反映します。
- 注目: これはページ上で費やされた時間を測定することを意味し、ユーザーが結果とそのコンテンツとどれだけ相互作用しているかを示すアイデアを提供する可能性があります。
さらに、パンドゥ・ナヤクの証言の記録には、彼らが従来のA/Bテストの代わりに交互に行うことで多数のアルゴリズムテストを実施していることが説明されています。これにより、彼らは迅速かつ信頼性の高い実験を行うことができ、それによってランキングの変動を解釈することが可能になっています。
5. 新鮮さ
新鮮さは、検索結果と検索機能の重要な側面です。利用可能になった直後に関連情報を表示し、情報が古くなった時点で表示を停止することが重要です。
ランキングアルゴリズムが最新のドキュメントをSERPに表示するためには、インデックス作成およびサービングシステムが非常に低いレイテンシで最新のドキュメントを発見、インデックス作成、および提供できる必要があります。理想的には、インデックス全体が可能な限り最新の状態であることが望ましいですが、低いレイテンシですべてのドキュメントをインデックス化することを阻む技術的およびコストの制約があります。インデックス作成システムは、異なるトレードオフを提供しながら、別々のパス上のドキュメントに優先順位を付けます。その際、レイテンシ、コスト、品質の間で異なるトレードオフがあります。
非常に新しいコンテンツはその関連性が過小評価されるリスクがあり、逆に、多くの関連性の証拠を持つコンテンツはクエリの意味の変化により関連性が低くなる可能性があります。

Freshness Nodeの役割は、古いスコアに修正を加えることです。新しいコンテンツを求めるクエリに対して、新しいコンテンツを促進し、古いコンテンツを低下させます。
以前、Google Caffeineが存在しなくなったことがリークされました(別名パーコレーターベースのインデックスシステム)。内部ではまだ古い名前が使われていますが、実際に存在するのは完全に新しいシステムです。新しい「カフェイン」は実際にはお互いに通信する一連のマイクロサービスです。これは、インデックスシステムの異なる部分が独立して連携したサービスとして機能し、それぞれが特定の機能を実行することを意味します。この構造は、より大きな柔軟性、拡張性、および更新や改善を行いやすさを提供できます。
これらのマイクロサービスの一部を解釈すると、TangramとGlueには、具体的にはFreshness NodeとInstant Glueが含まれると考えられます。これは、別の「Project Veritas」からの流出文書で、2016年に「Instant Navboost」を新鮮さのシグナルとして作成または組み込む提案があったことがわかったためです。また、Chromeの訪問も新鮮さのシグナルとして考慮されていました。

これまでに、彼らはすでに「Freshdocs-instant」(freshdocs-instant-docsパブサブと呼ばれるパブサブのリストから抽出され、そのメディアによって公開されたニュースを公開から1分以内に取得したもの)と検索スパイクおよびコンテンツ生成の相関関係を取り入れていました。

Freshness metrics内では、相関Nグラムと相関顕著用語の分析によって検出されるいくつかのメトリクスがあります:
- 相関NGrams:これらは統計的に有意なパターンで一緒に現れる単語のグループです。相関はイベントやトレンドトピック中に急に増加することがあり、スパイクを示すことがあります。
- 相関する顕著な用語:これらはトピックやイベントに密接に関連し、短期間で文書中での出現頻度が増加する目立つ用語です。これは関心の急増や関連する活動のスパイクを示唆しています。
スパイクが検出されたら、次の新鮮度メトリクスが使用される可能性があります:
- Unigrams (RTW): 各ドキュメントについて、タイトル、アンカーテキスト、および本文の最初の400文字が使用されます。これらはトレンド検出に関連するユニグラムに分解され、Hivemind インデックスに追加されます。本文には一般的に記事の主要なコンテンツが含まれており、繰り返しや一般的な要素(ボイラープレート)は除外されます。
- Half Hours since epoch (TEHH): これはUnix時間の開始からの半時間の数として表される時間の測定です。何かが起こった時刻を半時間の精度で確立するのに役立ちます。
- Knowledge Graph Entities (RTKG): GoogleのKnowledge Graph内のオブジェクトへの参照で、これは実在するエンティティ(人物、場所、物事)とそれらの相互関係のデータベースです。これにより、意味理解とコンテキストを持つ検索を豊かにするのに役立ちます。
- S2 Cells (S2): GoogleのKnowledge Graph内のオブジェクトへの参照で、これは実在するエンティティ(人物、場所、物事)とそれらの相互関係のデータベースです。これにより、意味理解とコンテキストを持つ検索を豊かにするのに役立ちます。
- Freshbox Article Score (RTF): これらは地図の地理的インデックス付けに使用される地球表面の幾何学的な分割です。これにより、ウェブコンテンツを正確な地理的位置と関連付けることができます。
- Document NSR (RTN): これはドキュメントのニュース関連性を示すものであり、現在のストーリーやトレンドイベントに関連するドキュメントの関連性と信頼性を決定するメトリックのようです。このメトリックは、低品質やスパムコンテンツを取り除くのにも役立ち、インデックスされたドキュメントが高品質でリアルタイムの検索にとって重要であることを保証します。
- Geographical Dimensions: ドキュメントで言及されているイベントやトピックの地理的位置を定義する特徴です。これには座標、地名、またはS2セルなどの識別子が含まれることがあります。
メディア業界で働いている場合、この情報は重要です。私は常にデジタル編集者向けのトレーニングに含めています。
クリックの重要性
このセクションでは、Googleの内部プレゼンテーションで共有された電子メール、題名は「統合クリック予測」、「Googleは魔法のようだ」プレゼンテーション、Search All Hands プレゼンテーション、Danny Sullivanからの内部メール、そして「Project Veritas」リークからの文書に焦点を当てます。
このプロセス全体を通じて、ユーザーの行動やニーズを理解する上でクリックの基本的な重要性が見えてきます。つまり、Googleは私たちのデータが必要なのです。興味深いことに、Googleが話すことを禁じられていたことの1つがクリックについてでした。

始める前に、クリックについて議論された主要な文書は2016年以前のものであることに注意することが重要です。その後、Googleは大きな変化を遂げています。それにもかかわらず、彼らのアプローチの基盤はユーザーの行動の分析であり、それを品質のシグナルと見なしています。彼らがCASモデルを説明する特許を覚えていますか?

ユーザーによるすべての検索とクリックは、Googleの学習と継続的な改善に貢献しています。このフィードバックループにより、Googleは検索の嗜好や行動について適応し、「学習」することができ、ユーザーのニーズを理解しているという錯覚を維持しています。

Googleは毎日、過去のデータに基づいて未来の予測を継続的に調整し、超えるために設計されたシステム内で10億以上の新しい行動を分析しています。少なくとも2016年まで、これは当時のAIシステムの能力を超えており、先に見た手作業やRankLabによる調整が必要でした。
RankLab,私は、異なるシグナルとランキング要因の重みをテストし、それらの後続する影響を試験する実験室であると理解しています。彼らは内部ツール「Twiddler」(私が数年前に「Project Veritas」から読んだもの)にも関与しているかもしれません。このツールは、特定の結果のIRスコアを手動で変更することを目的としており、つまり、以下のすべてを行うことができます。

この短い休憩の後、私は続けます。
人間の評価者の評価は基本的な視点を提供しますが、クリックは検索行動のより詳細な全景を提供します。


これにより複雑なパターンが明らかになり、2次および3次の影響を学ぶことができます。
- 第二次効果は新たなパターンを反映しています: 大多数が簡単なリストよりも詳細な記事を好み、選択する場合、Googleはそれを検出します。時間の経過とともに、関連する検索でより詳細な記事を優先するためにアルゴリズムを調整します。
- 第三次効果はより広範な、長期的な変化です: クリックの傾向が包括的なガイドを好む場合、コンテンツ作成者は適応します。彼らはより詳細な記事を生産し、リストを減らすことで、ウェブ上で利用可能なコンテンツの性質を変えます。
分析された文書において、検索結果の関連性がクリック分析を通じて向上した特定のケースが提示されています。Googleは、15,000件の無関連と見なされた文書に囲まれていたにもかかわらず、関連性のあることが判明した数件の文書に対するユーザーのクリックに基づくユーザーの選好に不一致があることを特定しました。この発見は、大量のデータの中に隠れた関連性を見分けるための貴重なツールとしてのユーザーのクリックの重要性を示しています。

Googleは「過去とのトレーニングを行い未来を予測する」ことで過学習を避けます。定期的な評価とデータの更新を通じて、モデルは常に最新で適切なものとなります。この戦略の重要な側面は、ローカライゼーションの個別化であり、異なる地域の異なるユーザーに適した結果を保証します。
パーソナライゼーションに関して、Googleはより最近の文書で、それが限定されており、ランキングがほとんど変わらないと主張しています。また、「トップストーリー」では決して発生しないとも述べています。使用されるタイミングは、以前の検索のコンテキストを使用して検索されている内容をより良く理解するためであり、また自動補完で予測的な提案を行うためです。彼らは、ユーザーが頻繁に使用する動画プロバイダーをわずかに優遇することがあると述べていますが、基本的には誰もがほぼ同じ結果を見ることになります。彼らによれば、クエリがユーザーデータよりも重要です。
このクリック重視のアプローチは、特に新しいコンテンツや頻繁に更新されるコンテンツに対しては課題に直面することを覚えておくことが重要です。検索結果の品質を評価することは、単にクリック数を数える以上の複雑なプロセスです。私が書いたこの記事は数年前のものですが、これをより深く掘り下げるのに役立つと思います。
Googleのアーキテクチャ
前のセクションに続いて、これは私が図表にこれらの要素を配置する方法について形成した心象です。Googleのアーキテクチャの一部が特定の場所にないか、またはそれほど関連していない可能性が非常に高いですが、これはおおよその近似値として十分だと考えています。
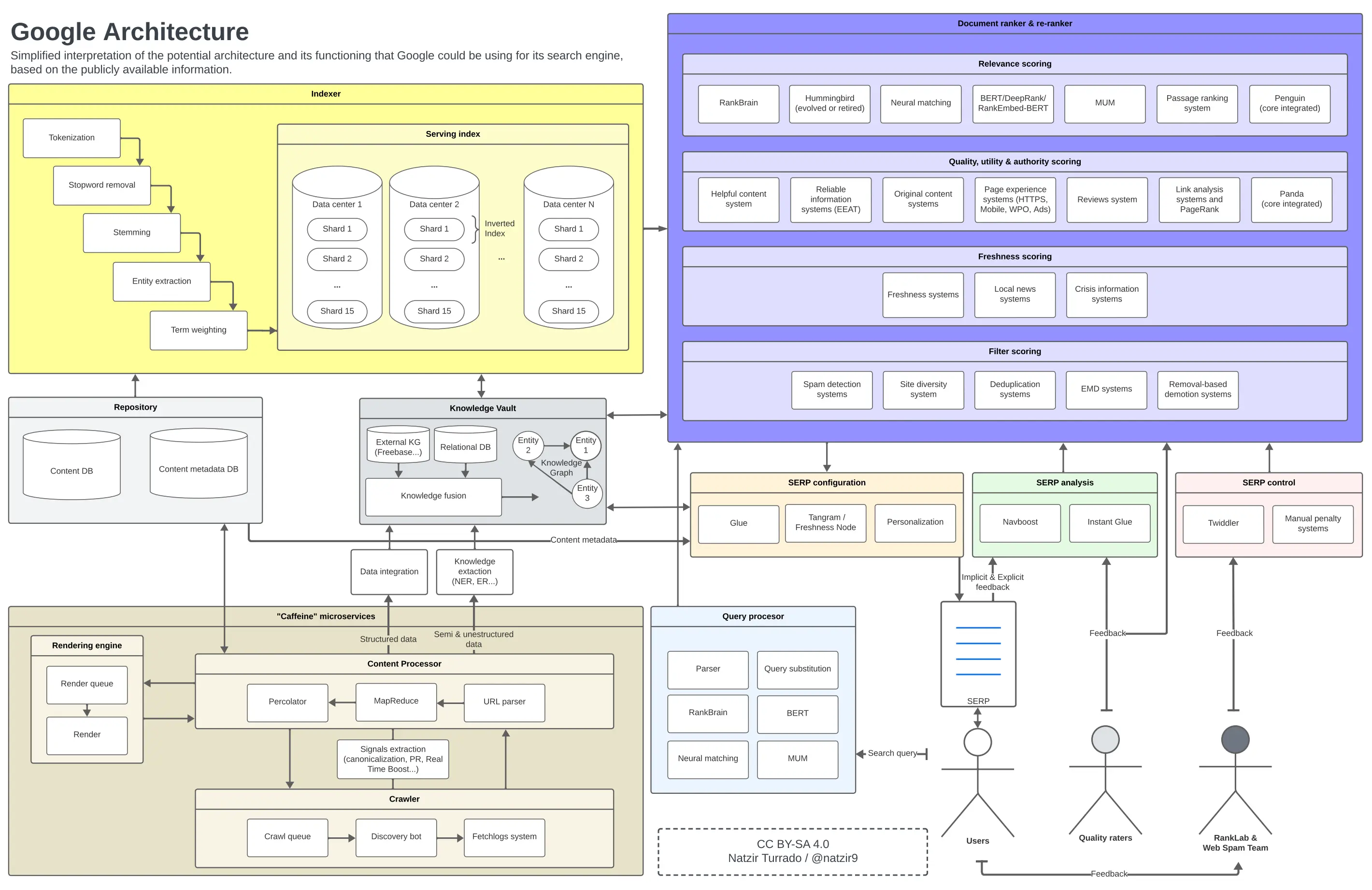
Googleの可能な機能とアーキテクチャ。画像を拡大するにはクリックしてください。
GoogleとChrome:デフォルトの検索エンジンとブラウザでの競争
この最後のセクションでは、カリフォルニア工科大学の行動経済学者であり教授である専門家アントニオ・ランジェルの証言に焦点を当て、ユーザーの選択に影響を与えるためのデフォルトオプションの使用について、Googleの内部プレゼンテーション『Googleのデフォルトホームページの戦略的価値について』で明らかになったもの、およびGoogleの副社長ジム・コロトゥロスの発言について取り上げます。
ジム・コロトゥロスが内部コミュニケーションで明らかにしたように、Chromeは単なるブラウザではなく、Googleの検索支配の重要な要素です。
Googleが収集するデータには、検索パターン、検索結果へのクリック、さまざまなウェブサイトとのやり取りなどが含まれており、これらはGoogleのアルゴリズムを改善し、検索結果の精度やターゲット広告の効果を高める上で重要です。
Antonio Rangelにとって、Chromeの市場支配は人気を超えています。それはGoogleのエコシステムへのゲートウェイとして機能し、ユーザーが情報やオンラインサービスにアクセスする方法に影響を与えています。デフォルトの検索エンジンであるGoogle検索との統合により、Chromeは情報の流れやデジタル広告のコントロールにおいてGoogleに重要な優位性をもたらしています。

Googleの人気にもかかわらず、Bingは劣っている検索エンジンではありません。ただし、多くのユーザーは、デフォルトの構成と関連する認知バイアスの利便性のためにGoogleを好む傾向があります。モバイルデバイスでは、デフォルトの検索エンジンの影響が強く、それらを変更する際の摩擦が関与するため、デフォルトの検索エンジンを変更するには最大12回のクリックが必要です。

このデフォルト設定は消費者のプライバシーにも影響を与えます。Googleのデフォルトのプライバシー設定は、より限られたデータ収集を希望する人々にとって大きな障壁となっています。デフォルトのオプションを変更するには、利用可能な代替案の認識、変更のための必要な手順の学習、および実装が必要であり、かなりの障壁となります。さらに、ステータスクオや損失回避などの行動バイアスにより、ユーザーはGoogleのデフォルトオプションを維持する方向に傾きます。こちらで詳しく説明しています
アントニオ・ランヘルの証言は、Googleの内部分析の暴露と直接 resonates しています。この文書によれば、ブラウザのホームページ設定は、検索エンジンの市場シェアやユーザーの行動に大きな影響を与えています。具体的には、Googleをデフォルトのホームページに設定しているユーザーのうち、Googleでの検索回数が50%増加しています。

これは、デフォルトのホームページと検索エンジンの選好との間に強い相関関係があることを示唆しています。さらに、この設定の影響は地域によって異なり、ヨーロッパ、中東、アフリカ、およびラテンアメリカでは顕著であり、アジア太平洋地域と北アメリカではそうではありません。分析によると、Googleはホームページの設定の変更に対して競合他社のYahooやMSNよりも脆弱であり、この設定を失うと大きな損失を被る可能性があります。

Googleのホームページ設定は、市場シェアを維持するだけでなく、競合他社にとって潜在的な脆弱性としても位置付けられる重要な戦略ツールとして認識されています。さらに、ほとんどのユーザーが積極的に検索エンジンを選択するのではなく、ホームページ設定で提供されるデフォルトのアクセスに傾向していることが強調されています。経済的には、Googleがホームページに設定された場合、ユーザーごとに約3ドルの増分のライフタイムバリューが見積もられています。

結論
Googleのアルゴリズムと内部動向を調査した結果、ユーザーのクリックと人間の評価者が検索結果のランキングに果たす重要な役割が明らかになりました。
ユーザーの好みを直接示すクリックは、Googleが回答の関連性と正確さを継続的に調整し改善するために不可欠です。ただし、数字が合わない場合は逆を求めることもあります。
さらに、人間の評価者は、人工知能の時代でも不可欠な評価と理解の重要な層を提供しています。個人的には、評価者が重要であることは知っていましたが、この程度とは驚きです。
これらの2つの入力を組み合わせることで、クリックを通じた自動フィードバックと人間の監視が可能になり、Googleは検索クエリをより良く理解するだけでなく、変化するトレンドや情報ニーズに適応することができます。AIが進化するにつれて、Googleがこれらの要素をどのようにバランスさせてプライバシーに焦点を当てた常に変化するエコシステムで検索体験を改善し、パーソナライズするかが興味深いでしょう。
一方、Chromeはブラウザ以上のものです。それは彼らのデジタル支配の重要な要素です。Google検索とのシナジー、および多くの領域でのデフォルト実装が市場のダイナミクスやデジタル環境全体に影響を与えています。独占禁止法の訴訟の結末は見守る必要がありますが、10年以上にわたり支配的地位の濫用に対する約100億ユーロの罰金を支払っていない状況です。