エンジニアのコーデックスは、実世界のソフトウェアエンジニアリングを抽出した無料の週刊出版物です。
_Reddit_のディスカッションをこちら、またはHacker Newsで読む。
2012年1月、Pinterestはわずか6人のエンジニアで月間1170万人のユニークユーザーに達しました。
2010年3月に立ち上げられ、当時1か月のユーザー数が1,000万人を超えた最速の企業でした。
Pinterestは画像が豊富なソーシャルネットワークであり、ユーザーは画像を保存したり「ピン留め」したりすることができます。
下で「ユーザー」と言っているときは、「月間アクティブユーザー」(MAU)を意味します。
- 既知で実証済みの技術を使用してください。 Pinterestが当時新しい技術に飛び込んだことが、データの破損などの問題を引き起こしました。
- シンプルに保つこと。(繰り返しのテーマ!)
- あまり創造的になりすぎないこと。 チームは、スケーリングするために同じノードを追加できるアーキテクチャに落ち着きました。
- 選択肢を制限すること。
- データベースのシャーディング > クラスタリング。 ノード間のデータ転送を減らすことができ、これは良いことでした。
- 楽しんでください! 新しいエンジニアは、最初の週にコードを貢献します。
Pinterestは2010年3月に1つの小さなMySQLデータベース、1つの小さなWebサーバー、そして1人のエンジニア(共同創業者2人と一緒に)で立ち上げられました。
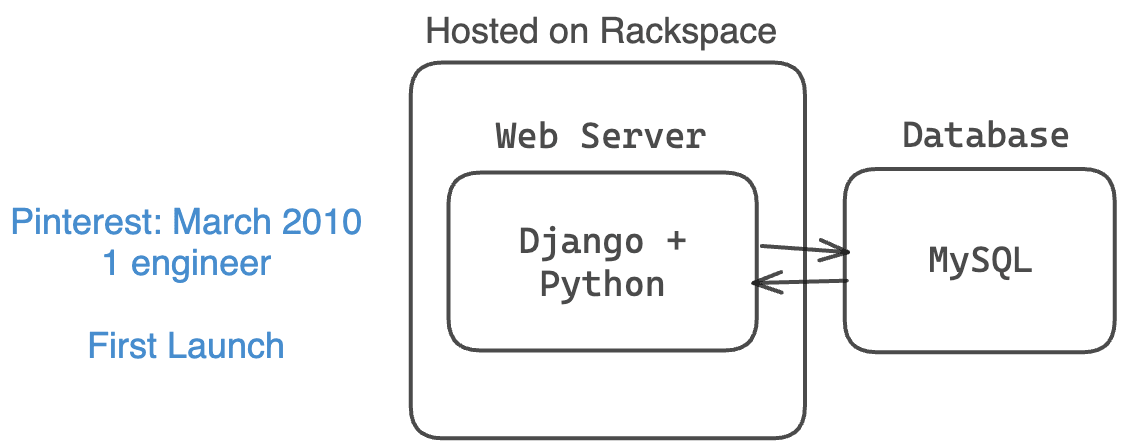
2011年1月、Pinterestのアーキテクチャは9ヶ月後に進化し、より多くのユーザーを処理できるようになりました。まだ招待制で、エンジニアは2人でした。
彼らは:
- 基本的なウェブサーバースタック(Amazon EC2、S3、およびCloudFront)
- バックエンドにはDjango(Python)を使用
- 冗長性のために4つのウェブサーバー
- 逆プロキシおよび負荷分散器としてNGINXを使用
- この時点で1つのMySQLデータベース + 1つの読み取り専用セカンダリ
- カウンター用にMongoDBを使用
- 非同期タスクのためのタスクキュー1つとタスクプロセッサー2つ

2011年1月から2011年10月まで、Pinterestは非常に急速に成長し、ユーザー数を1か月半ごとに倍増させました。
彼らのiPhoneアプリのローンチは、この成長を後押しする要因の1つでした。
When things grow fast, technology breaks more often than you expect.
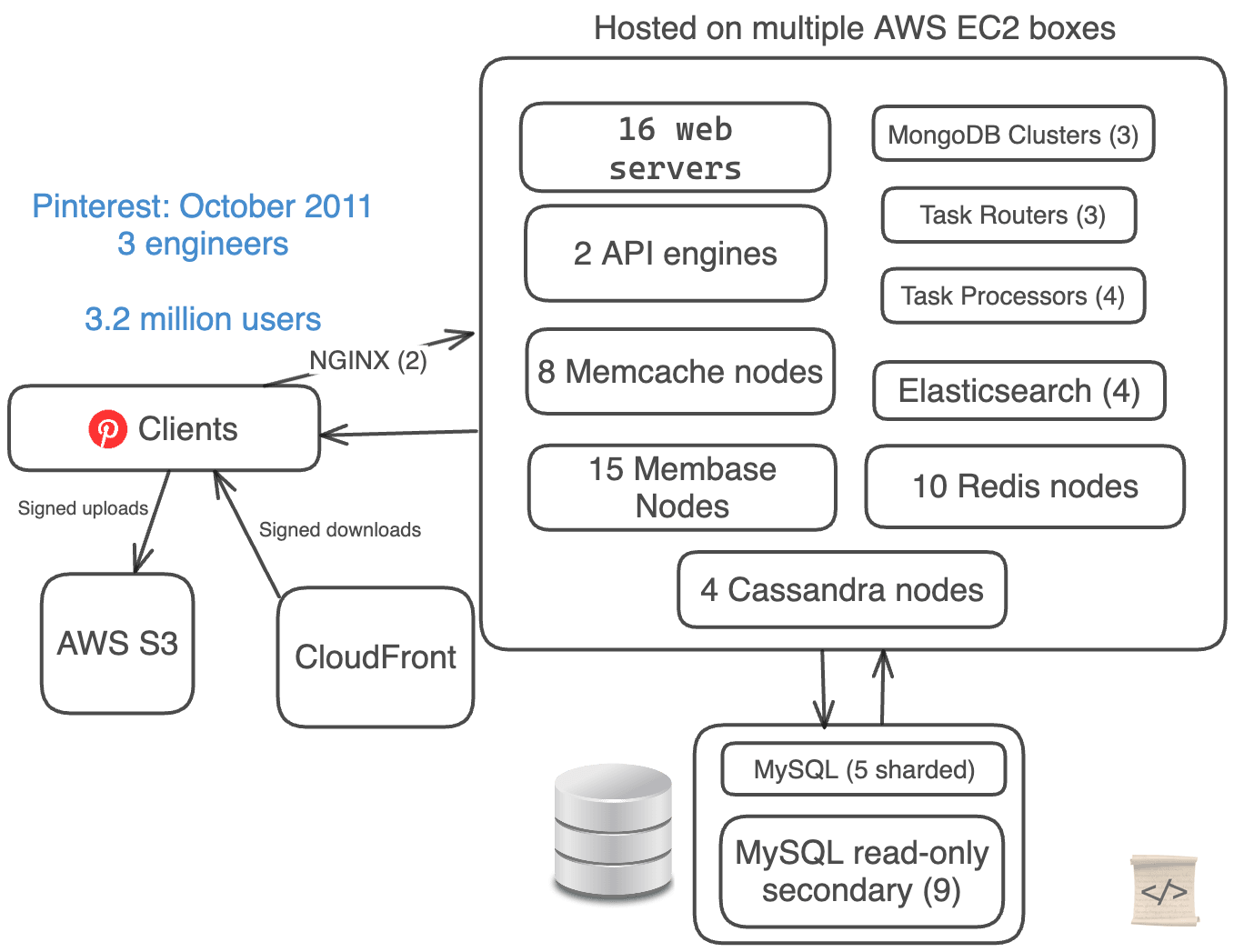
Pinterestは間違いを犯しました: 彼らは極端にアーキテクチャを複雑化しました。
彼らはエンジニアを3人しか雇っていませんでしたが、データには5つの異なるデータベース技術がありました。
彼らは両方ともMySQLデータベースを手動でシャーディングし、CassandraとMembase(現在のCouchbase)を使用してデータをクラスタリングしていました。
- Webサーバースタック(EC2 + S3 + CloudFront)
- 16台のWebサーバー
- 2つのAPIエンジン
- 2つのNGINXプロキシ
- 5つの手動シャーディングされたMySQL DB + 9つの読み取り専用セカンダリ
- 4つのCassandraノード
- 15台のMembaseノード(3つの別々のクラスタ)
- 8台のMemcacheノード
- 10台のRedisノード
- 3つのタスクルーター + 4つのタスクプロセッサ
- 4つのElastic Searchノード
- 3つのMongoクラスタ
データベースクラスタリングは、複数のデータベースサーバーを接続して、1つのシステムとして連携させるプロセスです。
理論上、クラスタリングはデータストアを自動的にスケーリングし、高可用性を提供し、無料のロードバランシングを行い、単一障害点を持ちません。
残念ながら、実際には、クラスタリングは非常に複雑で、アップグレードメカニズムが難しく、大きな単一障害点がありました。
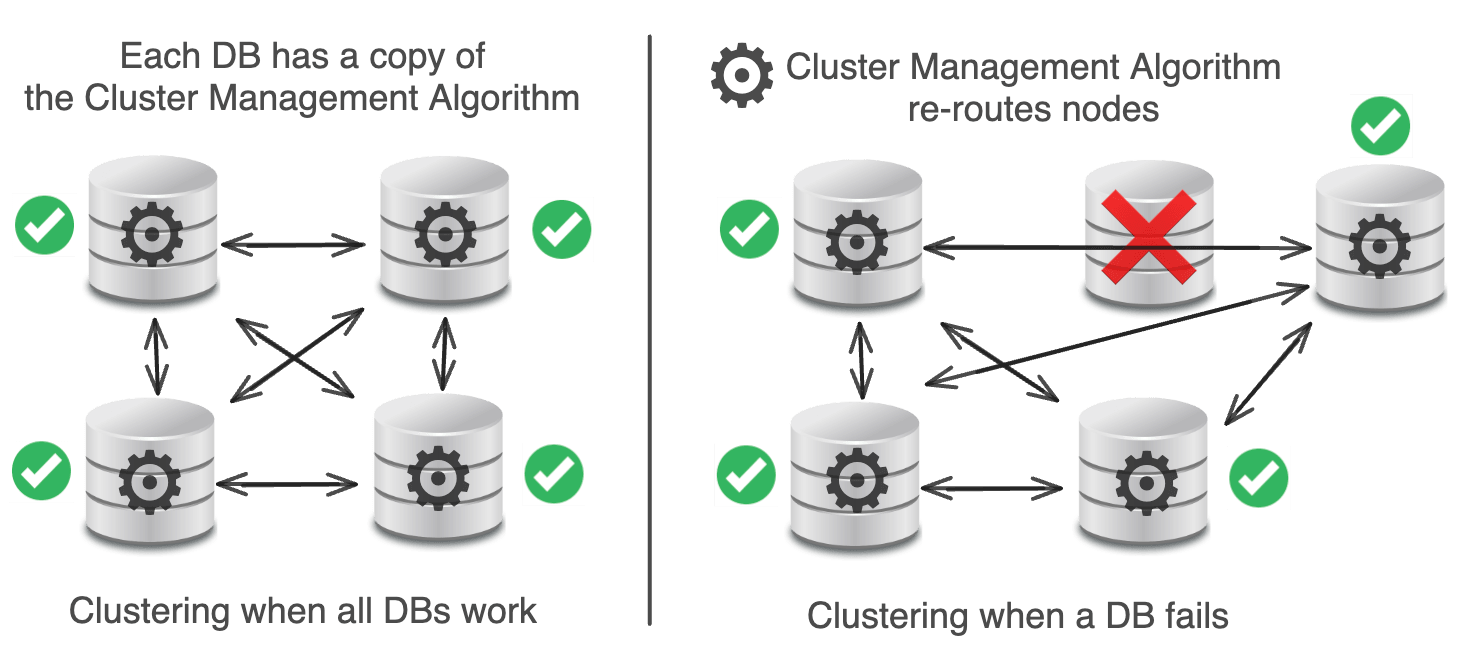
各DBには、DBからDBへとルーティングするクラスタ管理アルゴリズムがあります。
DBに問題が発生した場合、新しいDBが追加されて置き換えられます。
理論上、クラスタ管理アルゴリズムはこれをうまく処理するはずです。
実際には、Pinterestのクラスタ管理アルゴリズムにバグがあり、すべてのノードのデータが破損し、データの再バランスが壊れ、修復不能な問題がいくつか生じました。

Pinterestの解決策?システムからすべてのクラスタリング技術(Cassandra、Membase)を削除します。MySQL + Memcachedにすべてを集中します(より実績のあるもの)。
MySQLとMemcachedは実績のあるテクノロジーです。Facebookはこれら2つを使用して、世界最大のMemcachedシステムを作成しました。これにより、彼らは簡単に数十億のリクエストを1秒間に処理しました。
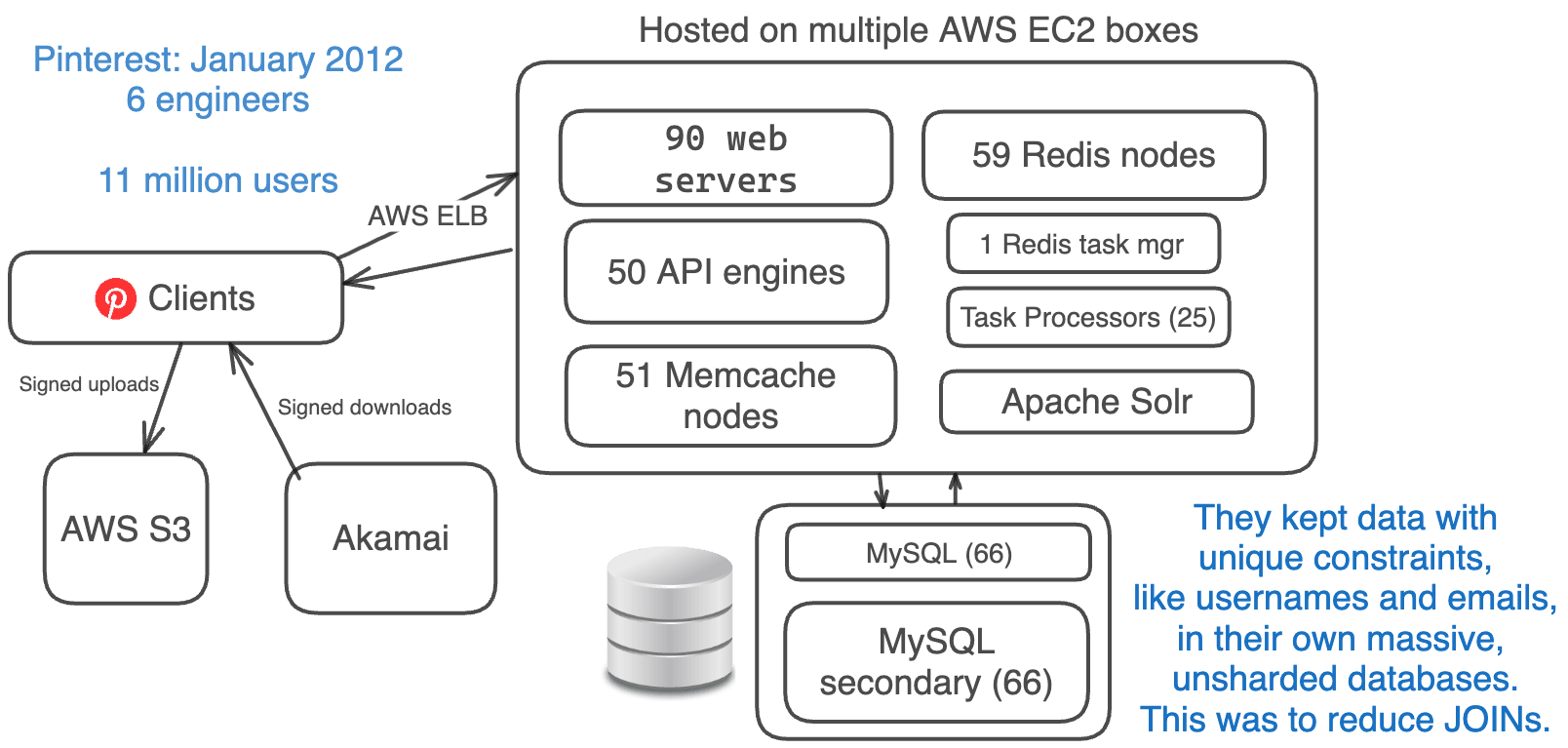
2012年1月、Pinterestは約1100万人の月間アクティブユーザーを扱っており、1日のユーザー数は1200万人から2100万人の間でした。
At this point, Pinterest had taken the time to simplify their architecture.
彼らは、クラスタリングやCassandraなどの未検証のアイデアを取り除き、代わりにMySQL、Memcache、およびシャーディングなどの検証済みのアイデアを採用しました。
彼らの簡略化されたスタック:
- Amazon EC2 + S3 + Akamai (replaced CloudFront)
- AWS ELB (Elastic Load Balancing)
- 90 Web Engines + 50 API Engines (using Flask)
- 66 MySQL DBs + 66 secondaries
- 59 Redis Instances
- 51 Memcache Instances
- 1 Redis Task Manager + 25 Task Processors
- Sharded Apache Solr (replaced Elasticsearch)
- Removed Cassanda, Membase, Elasticsearch, MongoDB, NGINX
データベースシャーディングは、単一のデータセットを複数のデータベースに分割する方法です。
利点: 高可用性、負荷分散、データ配置のためのシンプルなアルゴリズム、容量を追加するためにデータベースを簡単に分割できる、データを簡単に見つけることができる
Pinterestが最初にデータベースをシャーディングしたとき、機能の凍結がありました。数ヶ月の間に、彼らはデータベースを段階的かつ手動でシャーディングしました:
チームはデータベースレイヤーからテーブルの結合と複雑なクエリを削除しました。多くのキャッシュを追加しました。
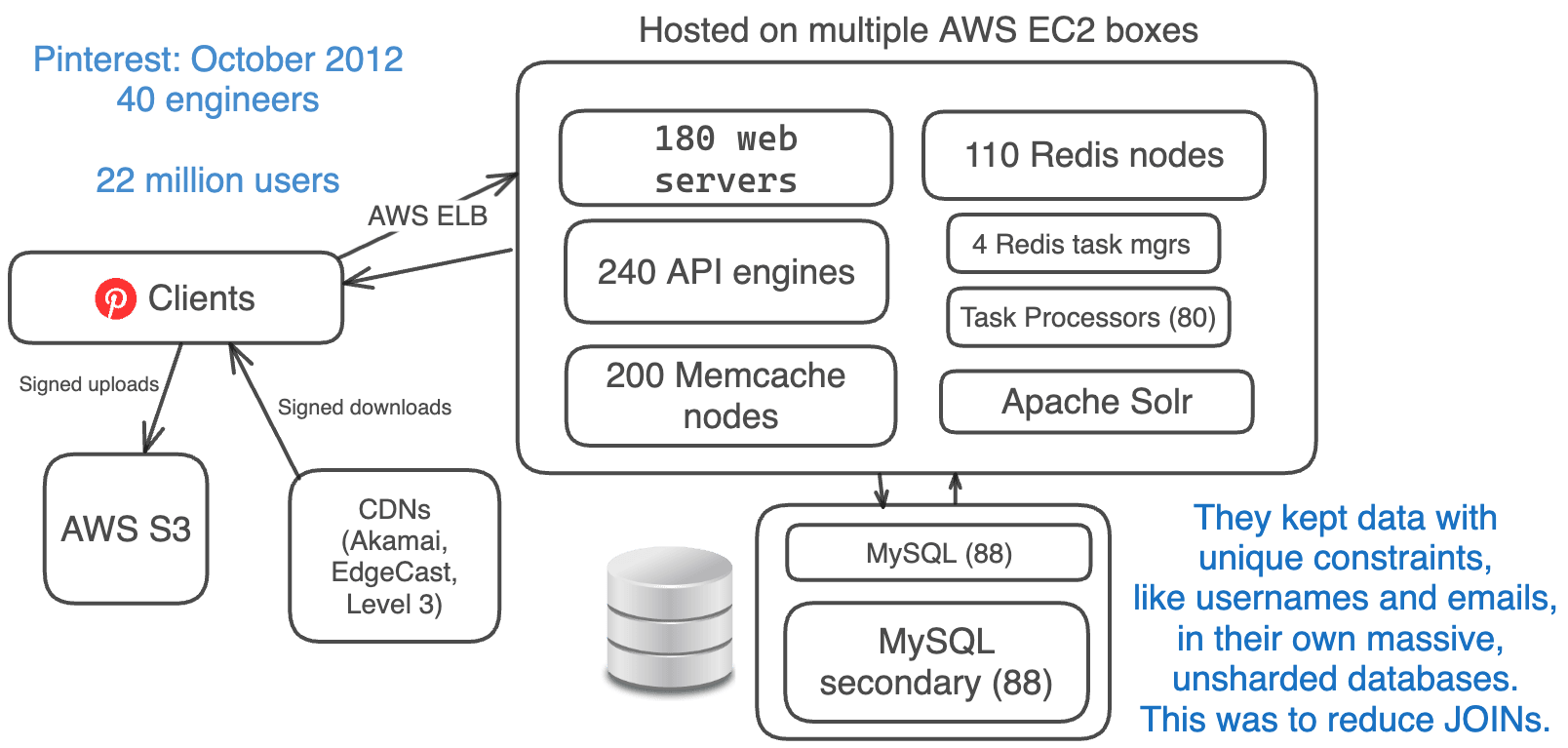
データベース間で一意制約を維持するのは追加の手間がかかるため、ユーザ名やメールアドレスなどのデータは巨大でシャーディングされていないデータベースに保持されていました。
すべてのテーブルはすべてのシャードに存在していました。
彼らは何十億もの「ピン」を持っていたため、データベースのインデックスがメモリ不足になりました。
彼らはデータベースの中で最大のテーブルを取り出して、独自のデータベースに移動させるだろう。
そのデータベースが容量不足になると、彼らはシャーディングを行いました。
2012年10月、Pinterestの月間利用者数は約2200万人でしたが、エンジニアリングチームは40人のエンジニアに4倍に増加していました。
アーキテクチャは同じでした。彼らはただ同じシステムをさらに追加しました。
- Amazon EC2 + S3 + CDNs (EdgeCast, Akamai, Level 3)
- 180 web servers + 240 API engines (using Flask)
- 88 MySQL DBs + 88 secondaries each
- 110 Redis instances
- 200 Memcache instances
- 4 Redis Task Managers + 80 Task Processors
- Sharded Apache Solr
They started moving from hard disk drives to SSDs.
重要な教訓:限られた、実証された選択肢が良かった。
EC2とS3に固執することで、設定の選択肢が限られ、頭痛が少なく、シンプルさが増しました。
ただし、新しいインスタンスは数秒で準備できる可能性がありました。 これは、数分で10個のMemcacheインスタンスを追加できることを意味していました。
SWE Quizは、データベース、認証、キャッシュなどをカバーする450以上のソフトウェアエンジニアリングとシステム設計の質問のコンピレーションです。
これらは、Google、Meta、Appleなどのエンジニアによって作成されました。
ソフトウェアの知識におけるギャップを特定し修正し、面接中の「ソフトウェアの雑学」の質問に合格してください。
Instagramのように、Pinterestはシャーディングされたデータベースを持っていたため、固有のID構造を持っていました。
Their 64-bit ID looked like:
Shard ID: シャード(16ビット)
Type: ピンなどのオブジェクトタイプ(10ビット)
Local ID: テーブル内の位置(38ビット)
これらのIDのルックアップ構造は、単純なPythonの辞書でした。
彼らはオブジェクトテーブルとマッピングテーブルを持っていました。
オブジェクトテーブルは、ピン、ボード、コメント、ユーザーなどに使用されました。 それらは、ローカルIDがMySQLのblobにマッピングされていました。JSONのような形式でした。
オブジェクト間のリレーショナルデータ用のマッピングテーブルは、ユーザーとボードのマッピングやピンへのいいねのようなものでした。 フルIDがフルIDとタイムスタンプにマッピングされていました。
すべてのクエリは効率化のためにPK(主キー)またはインデックスの検索でした。すべてのJOINをカットしました。
この記事は2012年にPinterestチームによって行われたScaling Pinterestというトークに基づいています。