自然言語処理の重要なパラダイムは、一般ドメインデータに対する大規模な事前トレーニングと、特定のタスクやドメインへの適応で構成されています。より大きなモデルを事前トレーニングするにつれて、すべてのモデルパラメータを再トレーニングする完全なファインチューニングは、実行可能性が低くなります。GPT-3 175Bを例にとると、175Bパラメータを持つファインチューニングされたモデルの独立したインスタンスを展開することは、非常に高価です。私たちは、事前トレーニングされたモデルの重みを固定し、Transformerアーキテクチャの各層にトレーニング可能なランク分解行列を注入するLow-Rank Adaptation、またはLoRAを提案します。これにより、下流タスクのためのトレーニング可能なパラメータの数が大幅に削減されます。AdamでファインチューニングされたGPT-3 175Bと比較して、LoRAはトレーニング可能なパラメータの数を1万倍、GPUメモリの要件を3倍削減できます。LoRAは、トレーニング可能なパラメータが少なく、トレーニングスループットが高く、アダプターとは異なり追加の推論遅延がないにもかかわらず、RoBERTa、DeBERTa、GPT-2、およびGPT-3のモデル品質においてファインチューニングと同等またはそれ以上の性能を発揮します。また、言語モデルの適応におけるランク欠損に関する実証的な調査を提供し、LoRAの有効性に光を当てます。私たちは、LoRAをPyTorchモデルと統合するためのパッケージをリリースし、RoBERTa、DeBERTa、およびGPT-2の実装とモデルチェックポイントを提供します。詳細は https://github.com/microsoft/LoRA をご覧ください。
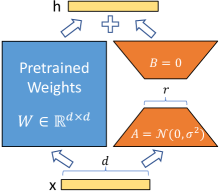
図1: 我々の再パラメータ化。A𝐴AとB𝐵Bのみを訓練します。
自然言語処理における多くのアプリケーションは、複数 の下流アプリケーションに適応するために、1 つの大規模な事前学習済み言語モデルを適応させることに依存しています。このような適応は通常、事前学習済みモデルのすべてのパラメータを更新する ファインチューニング を通じて行われます。ファインチューニングの主な欠点は、新しいモデルが元のモデルと同じ数のパラメータを含むことです。数ヶ月ごとにより大きなモデルが訓練されるため、これはGPT-2 (Radford et al., b) や RoBERTa large (Liu et al., 2019) にとっては単なる「不便」から、1750億の訓練可能なパラメータを持つGPT-3 (Brown et al., 2020) にとっては重要な展開の課題に変わります。
多くの人々は、いくつかのパラメータのみを適応させたり、新しいタスクのために外部モジュールを学習させたりすることで、これを緩和しようとしました。この方法では、各タスクの事前学習モデルに加えて、タスク固有のパラメータを少数保存および読み込むだけで済み、展開時の運用効率が大幅に向上します。しかし、既存の技術は、モデルの深さを拡張することによって推論遅延を引き起こすことが多いです (Houlsby et al., 2019; Rebuffi et al., 2017) またはモデルの使用可能なシーケンス長を短縮します (Li & Liang, 2021; Lester et al., 2021; Hambardzumyan et al., 2020; Liu et al., 2021) (Section 3)。さらに重要なことに、これらの方法はしばしばファインチューニングのベースラインに匹敵することができず、効率とモデル品質の間にトレードオフをもたらします。
私たちは、Li et al. (2018a); Aghajanyan et al. (2020) からインスピレーションを得ています。これらは、学習された過剰パラメータ化モデルが実際には低い内在次元に存在することを示しています。モデル適応中の重みの変化も低い「内在ランク」を持つと仮定し、これが私たちの提案する低ランク適応(LoRA)アプローチにつながります。LoRAは、適応中の密な層の変化のランク分解行列を最適化することによって、事前に学習された重みを固定したまま、神経ネットワークのいくつかの密な層を間接的に訓練することを可能にします。これは、図1に示されています。GPT-3 175Bを例にとると、非常に低いランク(すなわち、図1のrは1または2である可能性があります)が、フルランク(すなわち、d)が12,288のように高い場合でも十分であり、LoRAはストレージと計算の両方において効率的です。
LoRAは幾つかの重要な利点を持っています。
- •
事前学習済みモデルは共有され、異なるタスクのために多くの小さなLoRAモジュールを構築するために使用できます。共有モデルを固定し、Figure 1の行列A𝐴AとB𝐵Bを置き換えることで効率的にタスクを切り替えることができ、ストレージ要件とタスク切り替えのオーバーヘッドを大幅に削減します。
- •
LoRAは、適応型オプティマイザを使用する際に、勾配を計算したり、ほとんどのパラメータのオプティマイザの状態を維持する必要がないため、トレーニングをより効率的にし、ハードウェアの参入障壁を最大3倍低下させます。代わりに、注入されたはるかに小さな低ランク行列のみを最適化します。
- •
私たちのシンプルな線形デザインは、展開時にトレーニング可能な行列を凍結された重みと統合することを可能にし、構造上、完全にファインチューニングされたモデルと比較して推論の遅延を導入しません。
- •
LoRAは多くの従来の手法に対して直交しており、プレフィックスチューニングなどの多くの手法と組み合わせることができます。例を[Appendix E](#A5)に示します。
私たちは、Transformerアーキテクチャに頻繁に言及し、その次元に対して従来の用語を使用します。Transformer層の入力および出力次元サイズをd ext{model}と呼びます。自己注意モジュール内のクエリ/キー/値/出力投影行列を指すために、W ext{q}, W ext{k}, W ext{v}, およびW ext{o}を使用します。WまたはW ext{0}は、事前訓練された重み行列を指し、ΔWは適応中の累積勾配更新を示します。LoRAモジュールのランクをrで表します。私たちは、(Vaswani et al., 2017; Brown et al., 2020)によって設定された慣習に従い、モデル最適化のためにAdam (Loshchilov & Hutter, 2019; Kingma & Ba, 2017)を使用し、Transformer MLPフィードフォワード次元をd ext{ffn}=4\times d ext{model}とします。
私たちの提案はトレーニングの目的に依存しませんが、言語モデルを動機付けとなるユースケースとして焦点を当てています。以下は、言語モデルの問題に関する簡単な説明と、特にタスク特有のプロンプトに基づく条件付き確率の最大化についてです。
与えられた事前学習済みの自己回帰言語モデルPΦ(y|x)subscript𝑃Φconditional𝑦𝑥P {\Phi}(y|x)は、ΦΦ\Phiによってパラメータ化されています。例えば、PΦ(y|x)subscript𝑃Φconditional𝑦𝑥P {\Phi}(y|x)は、Transformerアーキテクチャに基づくGPT(Radford et al., b; Brown et al., 2020)のような一般的なマルチタスク学習者である可能性があります。この事前学習済みモデルを、要約、機械読解(MRC)、自然言語からSQL(NL2SQL)などの下流の条件付きテキスト生成タスクに適応させることを考えます。各下流タスクは、文脈-ターゲットペアのトレーニングデータセットによって表されます:𝒵 ={(xi,yi)}i=1,..,N\mathcal{Z}={(x{i},y{i})}{i=1,..,N}、ここで、xはsubscript𝑥𝑖x{i}およびyはsubscript𝑦𝑖y_{i}はトークンのシーケンスです。例えば、NL2SQLでは、xはsubscript𝑥𝑖x_{i}は自然言語のクエリであり、yはsubscript𝑦𝑖y_{i}はそれに対応するSQLコマンドです。要約の場合、xはsubscript𝑥𝑖x_{i}は記事の内容であり、yはsubscript𝑦𝑖y_{i}はその要約です。
完全なファインチューニング中、モデルは事前学習された重みΦ0subscriptΦ0\Phi _{0}に初期化され、条件付き言語モデリングの目的を最大化するために勾配に従って繰り返し更新されてΦ0+ΔΦsubscriptΦ0ΔΦ\Phi _{0}+\Delta\Phiに至る。
maxΦ∑(x,y)∈𝒵∑t=1|y|log(PΦ(yt|x,y<t))subscriptΦsubscript𝑥𝑦𝒵superscriptsubscript𝑡1𝑦logsubscript𝑃Φconditionalsubscript𝑦𝑡𝑥subscript𝑦absent𝑡\displaystyle\max {\Phi}\sum{(x,y)\in\mathcal{Z}}\sum_{t=1}^{|y|}\text{log}\left(P_{\Phi}(y_{t}|x,y_{<t})\right)
(1)
フルファインチューニングの主な欠点の一つは、_各_ダウンストリームタスクに対して、_異なる_パラメータセットΔΦΔΦ\Delta\Phiを学習することであり、その次元|ΔΦ|ΔΦ|\Delta\Phi|は|Φ0|subscriptΦ0|\Phi _{0}|に等しいことです。したがって、事前学習済みモデルが大きい場合(例えば、|Φ0|≈175 BillionsubscriptΦ0175 Billion|\Phi _{0}|\approx 175\text{~{}Billion}のようなGPT-3)、ファインチューニングされたモデルの多くの独立したインスタンスを保存および展開することは、困難であるか、全く実現可能でない場合があります。
本論文では、よりパラメータ効率の良いアプローチを採用し、タスク特有のパラメータ増分 ΔΦ=ΔΦ(Θ) が、はるかに小さいサイズのパラメータセット Θ でさらにエンコードされます。|Θ|≪|Φ0| です。したがって、ΔΦ を見つけるタスクは Θ に対する最適化になります。
maxΘ∑(x,y)∈𝒵∑t=1|y|log(pΦ0+ΔΦ(Θ)(yt|x,y<t))subscriptΘsubscript𝑥𝑦𝒵superscriptsubscript𝑡1𝑦subscript𝑝subscriptΦ0ΔΦΘconditionalsubscript𝑦𝑡𝑥subscript𝑦absent𝑡\displaystyle\max_{\Theta}\sum\ ext{(x,y)\in\mathcal{Z}}\sum\ ext{t=1}^{|y|}\log\left({p\ ext{\Phi_{0}+\Delta\Phi(\Theta)}(y_{t}|x,y_{<t}})\right
'(2)'
次のセクションでは、計算効率とメモリ効率の両方を考慮した低ランク表現を使用してΔΦΔΦ\Delta\Phiをエンコードすることを提案します。事前学習済みモデルがGPT-3 175Bの場合、学習可能なパラメータの数|Θ|Θ|\Theta|は|Φ0|subscriptΦ0|\Phi _{0}|の0.01%にまで小さくなる可能性があります。
私たちが取り組もうとしている問題は決して新しいものではありません。転移学習の開始以来、数十の研究がモデル適応をよりパラメータおよび計算効率的にしようとしています。いくつかの著名な研究の調査については、セクション6を参照してください。言語モデルを例にすると、効率的な適応に関しては、アダプターレイヤーを追加する戦略(Houlsby et al., 2019; Rebuffi et al., 2017; Pfeiffer et al., 2021; Rücklé et al., 2020)または入力層の活性化のいくつかの形式を最適化する戦略(Li & Liang, 2021; Lester et al., 2021; Hambardzumyan et al., 2020; Liu et al., 2021)の2つの顕著な戦略があります。しかし、両方の戦略には限界があり、特に大規模でレイテンシに敏感なプロダクションシナリオではそうです。
アダプターのバリエーションは多く存在します。私たちは、Houlsby et al. によるオリジナルデザイン(2019)に焦点を当てています。これは、各Transformerブロックに2つのアダプターレイヤーを持ち、Lin et al. によるより最近のデザイン(2020)は、ブロックごとに1つのみですが、追加のLayerNorm(Ba et al., 2016)があります。レイヤーをプルーニングしたり、マルチタスク設定を利用することで全体のレイテンシを削減することは可能ですが、アダプターレイヤーの追加計算を回避する直接的な方法はありません。アダプターレイヤーは少ないパラメータ(時には元のモデルの<<1%)を持つように設計されているため、これは問題ではないように思えます。これは小さなボトルネック次元を持つことで、追加できるFLOPsを制限します。しかし、大規模なニューラルネットワークはハードウェアの並列性に依存してレイテンシを低く保つ必要があり、アダプターレイヤーは逐次処理されなければなりません。これは、バッチサイズが通常1と非常に小さいオンライン推論設定で違いを生じさせます。モデル並列性のない一般的なシナリオ、例えば単一のGPUでGPT-2(Radford et al., b)の推論を実行する場合、非常に小さなボトルネック次元を使用しても、アダプターを使用することでレイテンシが顕著に増加するのが見られます(Table 1)。
バッチサイズ
32
16
1
シーケンスの長さ
512
256
128
|Θ|Θ|\Theta|
0.5M
11M
11M
ファインチューニング/LoRA
1449.4±プラスマイナス\pm0.8
338.0±プラスマイナス\pm0.6
19.8±プラスマイナス\pm2.7
AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}}
1482.0±プラスマイナス\pm1.0 (+2.2%)
354.8±プラスマイナス\pm0.5 (+5.0%)
23.9±プラスマイナス\pm2.1 (+20.7%)
AdapterHsuperscriptAdapterH\text{Adapter}^{\text{H}}
1492.2±プラスマイナス\pm1.0 (+3.0%)
366.3±プラスマイナス\pm0.5 (+8.4%)
25.8±プラスマイナス\pm2.2 (+30.3%)
表1: GPT-2 mediumにおける単一のフォワードパスの推論レイテンシ(ミリ秒単位)、100回の試行の平均値。NVIDIA Quadro RTX8000を使用しています。「|Θ|Θ|\Theta|」はアダプタ層の学習可能なパラメータの数を示します。AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}}とAdapterHsuperscriptAdapterH\text{Adapter}^{\text{H}}は、セクション5.1で説明するアダプタチューニングの2つのバリアントです。アダプタ層によって導入される推論レイテンシは、オンラインの短いシーケンス長のシナリオでは重要なものとなる可能性があります。完全な研究は付録Bを参照してください。
この問題は、Shoeybi et al. (2020); Lepikhin et al. (2020)で行われたようにモデルをシャーディングする必要があるときに悪化します。追加の深さは、アダプターパラメータを冗長に何度も保存しない限り、AllReduceやBroadcastなどのより多くの同期GPU操作を必要とします。
反対の方向性は、プレフィックスチューニング (Li & Liang, 2021)によって例示されるように、異なる課題に直面しています。プレフィックスチューニングは最適化が難しく、その性能は学習可能なパラメータにおいて非単調に変化することが観察され、元の論文での類似の観察を確認しています。より根本的には、適応のためにシーケンス長の一部を確保することは、下流タスクを処理するために利用可能なシーケンス長を必然的に減少させるため、プロンプトのチューニングが他の方法と比較して性能が劣ると私たちは疑っています。タスク性能に関する研究は Section 5に延期します。
LoRAのシンプルな設計とその実用的な利点について説明します。ここで概説する原則は、深層学習モデルの任意の密な層に適用されますが、私たちの実験では動機となるユースケースとしてTransformer言語モデルの特定の重みにのみ焦点を当てています。
ニューラルネットワークは、多くの密な層を含み、これらは行列の乗算を行います。これらの層の重み行列は通常、フルランクを持っています。特定のタスクに適応する際、Aghajanyan et al. (2020) は、事前学習された言語モデルが低い「内在次元」を持ち、より小さな部分空間へのランダム投影にもかかわらず効率的に学習できることを示しています。これに触発されて、私たちは適応中に重みの更新も低い「内在ランク」を持つと仮定します。事前学習された重み行列 W0∈ℝd×k に対して、後者を低ランク分解 W0+ΔW=W0+BA で表現することによって、その更新を制約します。ここで、B∈ℝd×r,A∈ℝr×k であり、ランク r≪min(d,k) です。トレーニング中、W0 は固定され、勾配更新を受け取らず、A と B は学習可能なパラメータを含みます。W0 と ΔW=BA は同じ入力と掛け合わされ、それぞれの出力ベクトルは座標ごとに合計されます。h=W0x に対して、私たちの修正されたフォワードパスは次のようになります:
h=W_{0}x+\Delta Wx=W_{0}x+BAx
'(3)'
私たちは、図1で再パラメータ化を示します。A𝐴Aにはランダムなガウス初期化を使用し、B𝐵Bにはゼロを使用するため、ΔW=BAΔ𝑊𝐵𝐴\Delta W=BAはトレーニングの初めにゼロです。その後、ΔWxΔ𝑊𝑥\Delta Wxをαr𝛼𝑟\frac{\alpha}{r}でスケーリングします。ここで、α𝛼\alphaはr𝑟rの定数です。Adamで最適化する際、初期化を適切にスケーリングすれば、α𝛼\alphaを調整することは学習率を調整することとほぼ同じです。その結果、私たちは単にα𝛼\alphaを最初に試すr𝑟rに設定し、調整しません。このスケーリングは、r𝑟rを変化させるときにハイパーパラメータを再調整する必要を減らすのに役立ちます(Yang & Hu, 2021)。
フルファインチューニングの一般化。より一般的なファインチューニングの形は、事前学習されたパラメータのサブセットのトレーニングを可能にします。LoRAは一歩進んで、適応中に重み行列の累積勾配更新がフルランクである必要がないことを示します。これは、LoRAをすべての重み行列に適用し、すべてのバイアスをトレーニングする際に、LoRAランクr𝑟rを事前学習された重み行列のランクに設定することで、フルファインチューニングの表現力を大まかに回復することを意味します。言い換えれば、トレーニング可能なパラメータの数を増やすにつれて、LoRAのトレーニングは元のモデルのトレーニングに大まかに収束し、アダプターベースの手法はMLPに収束し、プレフィックスベースの手法は長い入力シーケンスを受け取れないモデルに収束します。
追加の推論レイテンシなし。生産環境に展開されたとき、W=W0+BA𝑊subscript𝑊0𝐵𝐴W=W_{0}+BAを明示的に計算して保存し、通常通り推論を行うことができます。W0subscript𝑊0W_{0}とBA𝐵𝐴BAの両方はℝd×ksuperscriptℝ𝑑𝑘\mathbb{R}^{d\times k}にあります。別の下流タスクに切り替える必要がある場合、BA𝐵𝐴BAを引き算してW0subscript𝑊0W_{0}を回復し、その後異なるB′A′superscript𝐵′superscript𝐴′B^{\prime}A^{\prime}を加えることができます。これは非常に少ないメモリオーバーヘッドで迅速に行える操作です。重要なことに、これにより、構造上、ファインチューニングされたモデルと比較して推論中に追加のレイテンシを導入しないことが保証されます。
原則として、LoRAをニューラルネットワークの任意の重み行列のサブセットに適用して、学習可能なパラメータの数を減らすことができます。Transformerアーキテクチャでは、自己注意モジュールに4つの重み行列があります (Wq,Wk,Wv,Wosubscript𝑊𝑞subscript𝑊𝑘subscript𝑊𝑣subscript𝑊𝑜W_{q},W_{k},W_{v},W_{o}) とMLPモジュールに2つあります。Wqsubscript𝑊𝑞W_{q} (またはWksubscript𝑊𝑘W_{k}, Wvsubscript𝑊𝑣W_{v}) を次元dmodel×dmodelsubscript𝑑𝑚𝑜𝑑𝑒𝑙subscript𝑑𝑚𝑜𝑑𝑒𝑙d_{model}\times d_{model}の単一の行列として扱いますが、出力次元は通常、注意ヘッドに分割されます。我々は、単純さとパラメータ効率のために、下流タスクのために注意重みのみを適応させ、MLPモジュールは凍結します(したがって、下流タスクでは訓練されません)。Transformerにおける異なるタイプの注意重み行列の適応に関する影響をセクション 7.1でさらに研究します。MLP層、LayerNorm層、およびバイアスの適応に関する実証的調査は今後の作業に残します。
実用的な利点と制限。最も重要な利点は、メモリとストレージの使用量の削減から来ています。Adamで訓練された大規模なTransformerの場合、凍結されたパラメータのオプティマイザ状態を保存する必要がないため、VRAM使用量を最大で2/3232/3まで削減します。GPT-3 175Bでは、訓練中のVRAM消費を1.2TBから350GBに削減します。r=4で、クエリと値の投影行列のみを適応させる場合、チェックポイントサイズは約10,000×(350GBから35MBに)削減されます。これにより、はるかに少ないGPUで訓練でき、I/Oボトルネックを回避できます。もう一つの利点は、すべてのパラメータを入れ替えるのではなく、LoRAの重みだけを入れ替えることで、デプロイ中にはるかに低コストでタスク間を切り替えられることです。これにより、事前訓練された重みをVRAMに保存しているマシンで、即座に入れ替え可能な多くのカスタマイズモデルを作成できます。また、GPT-3 175Bでの訓練中に、フルファインチューニングと比較して25%のスピードアップを観察しています。これは、ほとんどのパラメータの勾配を計算する必要がないためです。
LoRAには限界もあります。例えば、追加の推論レイテンシを排除するためにA𝐴AとB𝐵BをW𝑊Wに吸収することを選択した場合、異なるA𝐴AとB𝐵Bを持つ異なるタスクへの入力を単一のフォワードパスでバッチ処理することは簡単ではありません。ただし、重みをマージせず、レイテンシが重要でないシナリオのバッチ内のサンプルに使用するLoRAモジュールを動的に選択することは可能です。
LoRAの下流タスク性能をRoBERTa (Liu et al., 2019), DeBERTa (He et al., 2021), およびGPT-2 (Radford et al., b)で評価し、その後GPT-3 175B (Brown et al., 2020)にスケールアップします。私たちの実験は、自然言語理解(NLU)から生成(NLG)までの幅広いタスクをカバーしています。具体的には、RoBERTaとDeBERTaのためにGLUE (Wang et al., 2019)ベンチマークで評価します。GPT-2に関しては、Li & Liang (2021)の設定に従い、直接比較を行い、WikiSQL (Zhong et al., 2017)(NLからSQLクエリ)およびSAMSum (Gliwa et al., 2019)(会話要約)を追加して、GPT-3の大規模実験を行います。使用するデータセットの詳細については、Appendix Cを参照してください。すべての実験にはNVIDIA Tesla V100を使用します。
他のベースラインと広く比較するために、以前の研究で使用された設定を再現し、可能な限り報告された数値を再利用します。しかし、これは一部のベースラインが特定の実験にのみ現れる可能性があることを意味します。
ファインチューニング(FT)は、適応のための一般的なアプローチです。ファインチューニング中、モデルは事前学習された重みとバイアスで初期化され、すべてのモデルパラメータが勾配更新を受けます。単純なバリアントは、他の層をフリーズしながら一部の層のみを更新することです。私たちは、GPT-2に関する以前の研究(Li & Liang, 2021)で報告されたそのようなベースラインの1つを含めており、最後の2層のみを適応させます(FTTop2superscriptFTTop2\textbf{FT}^{\textbf{Top2}})。
バイアスのみまたはBitFitは、他のすべてを固定しながらバイアスベクトルのみを訓練するベースラインです。現代において、このベースラインはBitFit(Zaken et al., 2021)によっても研究されています。
Prefix-embedding tuning (PreEmbed) は、入力トークンの間に特別なトークンを挿入します。これらの特別なトークンは学習可能な単語埋め込みを持ち、一般的にはモデルの語彙には含まれていません。これらのトークンをどこに配置するかは、パフォーマンスに影響を与える可能性があります。私たちは「プレフィクシング」に焦点を当てており、これはそのようなトークンをプロンプトの前に追加し、「インフィクシング」はプロンプトの後に追加します。両方については Li & Liang (2021) で議論されています。私たちは lpsubscript𝑙𝑝l_{p}(それぞれ lisubscript𝑙𝑖l_{i})をプレフィックス(それぞれインフィックス)トークンの数を示すために使用します。学習可能なパラメータの数は |Θ|=d_{model}×(l_{p}+l_{i}) です。
Prefix-layer tuning (PreLayer) は、prefix-embedding tuning の拡張です。特別なトークンのために単語埋め込み(または同等に、埋め込み層の後の活性化)を学習する代わりに、すべての Transformer 層の後の活性化を学習します。前の層から計算された活性化は、単に学習可能なものに置き換えられます。結果として得られる学習可能なパラメータの数は |Θ|=L×d_{model}×(l_{p}+l_{i}) であり、ここで L は Transformer 層の数です。
アダプターチューニングは、Houlsby et al. (2019)で提案されたように、自己注意モジュール(およびMLPモジュール)とその後の残差接続の間にアダプターレイヤーを挿入します。アダプターレイヤーには、バイアスを持つ2つの全結合層があり、その間に非線形性があります。この元の設計をAdapterHsuperscriptAdapterH\textbf{Adapter}^{\textbf{H}}と呼びます。最近、Lin et al. (2020)は、MLPモジュールの後とLayerNormの後にのみアダプターレイヤーを適用するより効率的な設計を提案しました。これをAdapterLsuperscriptAdapterL\textbf{Adapter}^{\textbf{L}}と呼びます。これは、Pfeiffer et al. (2021)で提案された別の設計に非常に似ており、これをAdapterPsuperscriptAdapterP\textbf{Adapter}^{\textbf{P}}と呼びます。また、効率を高めるためにいくつかのアダプターレイヤーを削除するAdapterDrop(Rücklé et al., 2020)という別のベースラインも含めています(AdapterDsuperscriptAdapterD\textbf{Adapter}^{\textbf{D}})。可能な限り以前の研究からの数値を引用し、比較するベースラインの数を最大化します。これらは、最初の列にアスタリスク(*)がある行にあります。すべての場合において、|Θ|=L^Adpt×(2×dmodel×r+r+dmodel)+2×L^LN×dmodel|\Theta|=\hat{L} _{Adpt}\times(2\times d _{model}\times r+r+d _{model})+2\times\hat{L} {LN}\times d e{model} であり、L^Adptsubscript^𝐿𝐴𝑑𝑝𝑡\hat{L} _{Adpt}はアダプターレイヤーの数、L^LNsubscript^𝐿𝐿𝑁\hat{L} _{LN}は学習可能なLayerNormの数です(例:AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}})。
LoRAは、既存の重み行列に並行して、ランク分解行列の学習可能なペアを追加します。前述の通り、Section 4.2では、簡潔さのためにほとんどの実験でWqsubscript𝑊𝑞W_{q}とWvsubscript𝑊𝑣W_{v}にのみLoRAを適用します。学習可能なパラメータの数は、ランクr𝑟rと元の重みの形状によって決まります: |Θ|=2×L^LoRA×dmodel×rΘ2subscript^𝐿𝐿𝑜𝑅𝐴subscript𝑑𝑚𝑜𝑑𝑒𝑙𝑟|\Theta|=2\times\hat{L}_{LoRA}\times d_{model}\times r、ここでL^LoRAsubscript^𝐿𝐿𝑜𝑅𝐴\hat{L}_{LoRA}は、LoRAを適用する重み行列の数です。
モデルと方法
# 学習可能
パラメータ
MNLI
SST-2
MRPC
コーラ
QNLI
QQP
RTE
STS-B
平均
RoBbasesubscriptRoBbase\text{RoB} _{\text{base}} (FT)*
125.0M
87.6
94.8
90.2
63.6
92.8
91.9
78.7
91.2
86.4
RoBbasesubscriptRoBbase\text{RoB} _{\text{base}} (BitFit)*
0.1M
84.7
93.7
92.7
62.0
91.8
84.0
81.5
90.8
85.2
RoBbasesubscriptRoBbase\text{RoB} _{\text{base}} (AdptDsuperscriptAdptD\text{Adpt}^{\text{D}})*
0.3M
87.1±±±0
94.2±±0.1
88.5±±1.1
60.8±±0.4
93.1±プラスマイナス\pm.1
90.2±プラスマイナス\pm.0
71.5±±2.7
89.7±プラスマイナス\pm.3
84.4
RoBbasesubscriptRoBbase\text{RoB} _{\text{base}} (AdptDsuperscriptAdptD\text{Adpt}^{\text{D}})*
0.9M
87.3±プラスマイナス\pm.1
94.7±±0.3
88.4±プラスマイナス\pm.1
62.6±プラスマイナス\pm.9
93.0±プラスマイナス\pm.2
90.6±プラスマイナス\pm.0
75.9±±2.2
90.3±プラスマイナス\pm.1
85.4
RoBbasesubscriptRoBbase\text{RoB} _{\text{base}} (LoRA)
0.3M
87.5±プラスマイナス\pm.3
95.1±プラスマイナス\pm.2
89.7±プラスマイナス\pm.7
63.4±プラスマイナス\pm1.2
93.3±プラスマイナス\pm.3
90.8±プラスマイナス\pm.1
86.6±±0.7
91.5±プラスマイナス\pm.2
87.2
RoBlargesubscriptRoBlarge\text{RoB} _{\text{large}} (FT)*
355.0M
90.2
96.4
90.9
68.0
94.7
92.2
86.6
92.4
88.9
RoBlargesubscriptRoBlarge\text{RoB} _{\text{large}} (LoRA)
0.8M
90.6±±\pm.2
96.2±±0.5
90.9±プラスマイナス\pm1.2
68.2±±1.9
94.9±プラスマイナス\pm.3
91.6±±0.1
87.4±プラスマイナス\pm2.5
92.6±±0.2
89.0
RoBlargesubscriptRoBlarge\text{RoB} _{\text{large}} (AdptPsuperscriptAdptP\text{Adpt}^{\text{P}})††\dagger
3.0M
90.2±プラスマイナス\pm.3
96.1±プラスマイナス\pm.3
90.2±±0.7
68.3±±1.0
94.8±±0.2
91.9±プラスマイナス\pm.1
83.8±プラスマイナス\pm2.9
92.1±±0.7
88.4
RoBlargesubscriptRoBlarge\text{RoB} _{\text{large}} (AdptPsuperscriptAdptP\text{Adpt}^{\text{P}})††\dagger
0.8M
90.5±プラスマイナス\pm.3
96.6±±0.2
89.7±プラスマイナス\pm1.2
67.8±プラスマイナス\pm2.5
94.8±±0.3
91.7±±±0.2
80.1±±2.9
91.9±プラスマイナス\pm.4
87.9
RoBlargesubscriptRoBlarge\text{RoB} _{\text{large}} (AdptHsuperscriptAdptH\text{Adpt}^{\text{H}})††\dagger
6.0M
89.9±±\pm.5
96.2±±0.3
88.7±プラスマイナス\pm2.9
66.5±プラスマイナス\pm4.4
94.7±±\pm.2
92.1±プラスマイナス\pm.1
83.4±±1.1
91.0±±1.7
87.8
RoBlargesubscriptRoBlarge\text{RoB} _{\text{large}} (AdptHsuperscriptAdptH\text{Adpt}^{\text{H}})††\dagger
0.8M
90.3±プラスマイナス\pm.3
96.3±±0.5
87.7±±1.7
66.3±±2.0
94.7±±\pm.2
91.5±プラスマイナス\pm.1
72.9±±2.9
91.5±プラスマイナス\pm.5
86.4
RoBlargesubscriptRoBlarge\text{RoB} _{\text{large}} (LoRA)††\dagger
0.8M
90.6±±\pm.2
96.2±±0.5
90.2±±1.0
68.2±±1.9
94.8±±0.3
91.6±±0.2
85.2±±1.1
92.3±プラスマイナス\pm.5
88.6
DeBXXLsubscriptDeBXXL\text{DeB} _{\text{XXL}} (FT)*
1500.0M
91.8
97.2
92.0
72.0
96.0
92.7
93.9
92.9
91.1
DeBXXLsubscriptDeBXXL\text{DeB} _{\text{XXL}} (LoRA)
4.7M
91.9±プラスマイナス\pm.2
96.9±プラスマイナス\pm.2
92.6±±0.6
72.4±± ext{pm}1.1
96.0±プラスマイナス\pm.1
92.9±プラスマイナス\pm.1
94.9±プラスマイナス\pm.4
93.0±プラスマイナス\pm.2
91.3
表2: RoBERTabasesubscriptRoBERTabase\text{RoBERTa} _{\text{base}}, RoBERTalargesubscriptRoBERTalarge\text{RoBERTa} _{\text{large}}, および DeBERTaXXLsubscriptDeBERTaXXL\text{DeBERTa} _{\text{XXL}} の異なる適応方法による GLUE ベンチマークでの結果。MNLI の全体的な(マッチおよびミスマッチ)精度、CoLA のマシュー相関、STS-B のピアソン相関、その他のタスクの精度を報告します。すべての指標で高い方が良いです。* は以前の研究で発表された数値を示します。††\dagger は、Houlsby et al. (2019) に類似した設定で構成された実行を示します。
RoBERTa (Liu et al., 2019) は、BERT (Devlin et al., 2019a) で元々提案された事前学習レシピを最適化し、トレーニング可能なパラメータをあまり追加することなく、後者のタスクパフォーマンスを向上させました。最近の数年間、RoBERTa は GLUE ベンチマーク (Wang et al., 2019) のような NLP リーダーボードで、はるかに大きなモデルに追い越されていますが、実務者の間ではそのサイズにおいて競争力があり人気のある事前学習モデルのままです。私たちは、HuggingFace Transformers ライブラリ (Wolf et al., 2020) から事前学習済みの RoBERTa ベース (125M) と RoBERTa ラージ (355M) を取り、GLUE ベンチマークのタスクに対するさまざまな効率的適応アプローチのパフォーマンスを評価します。また、Houlsby et al. (2019) と Pfeiffer et al. (2021) の設定に従って再現します。公平な比較を確保するために、アダプタとの比較時に LoRA を評価する方法に2つの重要な変更を加えます。まず、すべてのタスクに対して同じバッチサイズを使用し、アダプタのベースラインに合わせるためにシーケンス長を128に設定します。次に、MRPC、RTE、および STS-B の事前学習モデルにモデルを初期化し、ファインチューニングベースラインのように MNLI にすでに適応されたモデルではありません。このより制限された設定に従った実行は、Houlsby et al. (2019) によって ††\dagger とラベル付けされます。結果は Table 2 (Top Three Sections) に示されています。使用されたハイパーパラメータの詳細については Section D.1 を参照してください。
DeBERTa (He et al., 2021)は、BERTのより新しいバリアントであり、はるかに大規模でトレーニングされており、GLUE (Wang et al., 2019)やSuperGLUE (Wang et al., 2020)などのベンチマークで非常に競争力のあるパフォーマンスを発揮します。LoRAがGLUEで完全にファインチューニングされたDeBERTa XXL (1.5B)のパフォーマンスに匹敵するかどうかを評価します。結果は Table 2 (下部セクション)に示されています。使用されたハイパーパラメータの詳細については、Section D.2を参照してください。
LoRAがNLUにおいてフルファインチューニングの競争力のある代替手段であることを示した後、LoRAがGPT-2の中型および大型のNLGモデルでも優れているかどうかを確認したいと考えています(Radford et al., b)。直接比較のために、私たちはLi & Liang(2021)にできるだけ近い設定を維持します。スペースの制約により、このセクションではE2E NLG Challengeの結果のみを示します(Table 3)。WebNLG(Gardent et al., 2017)およびDART(Nan et al., 2020)に関する結果はSection F.1を参照してください。使用したハイパーパラメータのリストはSection D.3に含まれています。
モデルと方法
# 学習可能
E2E NLG チャレンジ
パラメータ
BLEU
NIST
MET
ROUGE-L
CIDEr
GPT-2 M (FT)*
354.92M
68.2
8.62
46.2
71.0
2.47
GPT-2 M (AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}})*
0.37M
66.3
8.41
45.0
69.8
2.40
GPT-2 M (AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}})*
11.09M
68.9
8.71
46.1
71.3
2.47
GPT-2 M (AdapterHsuperscriptAdapterH\text{Adapter}^{\text{H}})
11.09M
67.3±プラスマイナス\pm.6
8.50±プラスマイナス\pm.07
46.0±プラスマイナス\pm.2
70.7±プラスマイナス\pm.2
2.44±プラスマイナス\pm.01
GPT-2 M (FTTop2superscriptFTTop2\text{FT}^{\text{Top2}})*
25.19M
68.1
8.59
46.0
70.8
2.41
GPT-2 M (PreLayer) *
0.35M
69.7
8.81
46.1
71.4
2.49
GPT-2 M (LoRA)
0.35M
70.4±±0.1
8.85±プラスマイナス\pm.02
46.8±±±0.2
71.8±±0.1
2.53±プラスマイナス\pm.02
GPT-2 L (FT)*
774.03M
68.5
8.78
46.0
69.9
2.45
GPT-2 L (AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}})
0.88M
69.1±プラスマイナス\pm.1
8.68±プラスマイナス\pm.03
46.3±プラスマイナス\pm.0
71.4±プラスマイナス\pm.2
2.49±プラスマイナス\pm.0
GPT-2 L (AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}})
23.00M
68.9±±0.3
8.70±プラスマイナス\pm.04
46.1±プラスマイナス\pm.1
71.3±±0.2
2.45±プラスマイナス\pm.02
GPT-2 L (PreLayer) *
0.77M
70.3
8.85
46.2
71.7
2.47
GPT-2 L (LoRA)
0.77M
70.4±±0.1
8.89±プラスマイナス\pm.02
46.8±±±0.2
72.0±プラスマイナス\pm.2
2.47±プラスマイナス\pm.02
表3: E2E NLGチャレンジにおける異なる適応方法を用いたGPT-2ミディアム(M)およびラージ(L)。すべての指標において、高い方が良い。LoRAは、比較可能またはより少ない学習可能なパラメータでいくつかのベースラインを上回る。実施した実験の信頼区間が示されている。*は以前の研究で発表された数値を示す。
モデルと方法
# 学習可能
ウィキSQL
MNLI-m
SAMSum
パラメータ
Acc. (%)
Acc. (%)
R1/R2/RL
GPT-3 (FT)
175,255.8M
73.8
89.5
52.0/28.0/44.5
GPT-3 (BitFit)
14.2M
71.3
91.0
51.3/27.4/43.5
GPT-3 (PreEmbed)
3.2M
63.1
88.6
48.3/24.2/40.5
GPT-3 (PreLayer)
20.2M
70.1
89.5
50.8/27.3/43.5
GPT-3 (アダプタH^{\text{H}})
7.1M
71.9
89.8
53.0/28.9/44.8
GPT-3 (アダプタH^{\text{H}})
40.1M
73.2
91.5
53.2/29.0/45.1
GPT-3 (LoRA)
4.7M
73.4
91.7
53.8/29.8/45.9
GPT-3 (LoRA)
37.7M
74.0
91.6
53.4/29.2/45.1
表4: GPT-3 175Bにおける異なる適応方法の性能。我々はWikiSQLにおける論理形式検証精度、MultiNLI-matchedにおける検証精度、及びSAMSumにおけるRouge-1/2/Lを報告する。LoRAは、完全なファインチューニングを含む従来のアプローチよりも優れている。WikiSQLの結果は±0.5%\pm 0.5%の周りで変動し、MNLI-mは±0.1%\pm 0.1%、SAMSumは±0.2\pm 0.2/±0.2\pm 0.2/±0.1\pm 0.1の3つの指標に対して変動する。
LoRAの最終的なストレステストとして、1750億パラメータを持つGPT-3にスケールアップします。高いトレーニングコストのため、すべてのエントリに対して提供するのではなく、ランダムシードに対する特定のタスクの典型的な標準偏差のみを報告します。使用されたハイパーパラメータの詳細については、Section D.4を参照してください。
次のように示されているように Table 4、LoRAはすべての3つのデータセットでファインチューニングのベースラインに匹敵するか、それを上回ります。すべての手法がトレーニング可能なパラメータが増えることで単調に利益を得るわけではないことに注意してください。これは Figure 2 に示されています。256以上の特殊トークンをプレフィックス埋め込みチューニングに使用したり、32以上の特殊トークンをプレフィックスレイヤーチューニングに使用した場合、パフォーマンスが大幅に低下することを観察します。これは、Li & Liang (2021) における類似の観察を裏付けています。この現象についての徹底的な調査は本研究の範囲外ですが、特殊トークンが増えることで入力分布が事前学習データ分布からさらに離れると疑っています。別途、Section F.3 で低データレジームにおける異なる適応アプローチのパフォーマンスを調査します。
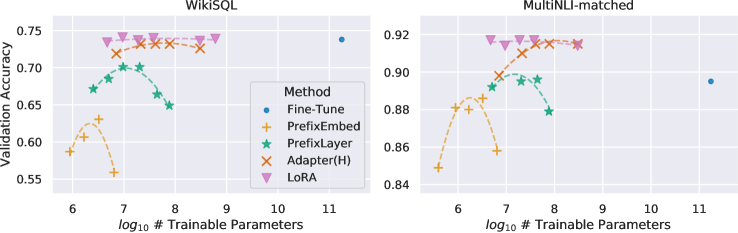
図2: GPT-3 175Bの検証精度とWikiSQLおよびMNLI-matchedのいくつかの適応方法の学習可能なパラメータの数。LoRAはより良いスケーラビリティとタスクパフォーマンスを示します。プロットされたデータポイントの詳細についてはセクションF.2を参照してください。
Transformer言語モデル。 Transformer (Vaswani et al., 2017)は、自己注意を多用したシーケンス・ツー・シーケンスアーキテクチャです。Radford et al. (a)は、Transformerデコーダのスタックを使用して自己回帰言語モデリングに適用しました。それ以来、Transformerベースの言語モデルはNLPを支配し、多くのタスクで最先端の成果を達成しています。BERT (Devlin et al., 2019b)とGPT-2 (Radford et al., b)とともに新しいパラダイムが登場しました。これらはどちらも大量のテキストで訓練された大規模なTransformer言語モデルであり、一般ドメインデータでの事前訓練の後にタスク特化データで微調整することで、タスク特化データで直接訓練する場合と比較して、著しい性能向上が得られます。より大きなTransformerを訓練することは一般的により良い性能をもたらし、依然として活発な研究の方向性です。GPT-3 (Brown et al., 2020)は、175Bパラメータでこれまでに訓練された最大の単一Transformer言語モデルです。
プロンプトエンジニアリングとファインチューニング。 GPT-3 175Bは、わずか数例の追加トレーニング例でその動作を適応させることができますが、その結果は入力プロンプトに大きく依存します (Brown et al., 2020)。これは、モデルのパフォーマンスを最大化するためにプロンプトを構成しフォーマットする経験的な技術を必要とし、これをプロンプトエンジニアリングまたはプロンプトハッキングと呼びます。ファインチューニングは、一般的なドメインで事前トレーニングされたモデルを特定のタスクに再トレーニングします Devlin et al. (2019b); Radford et al. (a)。そのバリアントには、パラメータのサブセットのみを学習することが含まれます Devlin et al. (2019b); Collobert & Weston (2008)、しかし実務者はしばしばすべてのパラメータを再トレーニングして下流のパフォーマンスを最大化します。しかし、GPT-3 175Bの巨大さは、生成される大きなチェックポイントと、事前トレーニングと同じメモリフットプリントを持つため、通常の方法でファインチューニングを行うことを困難にします。
パラメータ効率的適応。多くの研究者がニューラルネットワークの既存の層の間にアダプタ層を挿入することを提案しています (Houlsby et al., 2019; Rebuffi et al., 2017; Lin et al., 2020)。私たちの方法は、重みの更新に低ランク制約を課すために、類似のボトルネック構造を使用します。主な機能的な違いは、私たちの学習した重みが推論中に主な重みと統合できるため、レイテンシを導入しないことです。これはアダプタ層には当てはまりません (Section 3)。アダプタの現代的な拡張はコンパクターです (Mahabadi et al., 2021)。これは本質的に、いくつかの事前に定められた重み共有スキームを使用してアダプタ層をクロンカー積でパラメータ化します。同様に、LoRAを他のテンソル積ベースの手法と組み合わせることで、そのパラメータ効率を向上させる可能性があり、これは将来の研究に委ねます。最近では、多くの研究者がファインチューニングの代わりに入力単語埋め込みを最適化することを提案しており、これはプロンプトエンジニアリングの連続的かつ微分可能な一般化に似ています (Li & Liang, 2021; Lester et al., 2021; Hambardzumyan et al., 2020; Liu et al., 2021)。私たちは実験セクションでLi & Liang (2021)との比較を含めています。しかし、この研究の流れは、位置埋め込みが学習されるときにタスクトークンのための利用可能なシーケンス長を占有するプロンプト内でより多くの特別なトークンを使用することによってのみスケールアップできます。
深層学習における低ランク構造。低ランク構造は機械学習において非常に一般的です。多くの機械学習の問題には、特定の内在的な低ランク構造があります (Li et al., 2016; Cai et al., 2010; Li et al., 2018b; Grasedyck et al., 2013)。さらに、多くの深層学習タスク、特に過剰にパラメータ化されたニューラルネットワークを持つタスクにおいて、学習されたニューラルネットワークはトレーニング後に低ランク特性を享受することが知られています (Oymak et al., 2019)。いくつかの先行研究では、元のニューラルネットワークをトレーニングする際に明示的に低ランク制約を課すことさえあります (Sainath et al., 2013; Povey et al., 2018; Zhang et al., 2014; Jaderberg et al., 2014; Zhao et al., 2016; Khodak et al., 2021; Denil et al., 2014); しかし、私たちの知る限り、これらの研究のいずれも、_下流タスクへの適応_のために凍結モデルに対する低ランク更新を考慮していません。理論文献では、ニューラルネットワークが、対応する(有限幅の)ニューラル接触カーネル (Allen-Zhu et al., 2019; Li & Liang, 2018) を含む他の古典的な学習方法を上回ることが知られています。基礎となる概念クラスが特定の低ランク構造を持つ場合 (Ghorbani et al., 2020; Allen-Zhu & Li, 2019; 2020a)。Allen-Zhu & Li (2020b) の別の理論的結果は、低ランク適応が敵対的トレーニングに有用である可能性があることを示唆しています。要するに、私たちは提案する低ランク適応更新が文献によって十分に動機付けられていると考えています。
LoRAの経験的な利点を考慮し、下流タスクから学習された低ランク適応の特性をさらに説明したいと考えています。低ランク構造は、ハードウェアの参入障壁を下げるだけでなく、複数の実験を並行して実行できるようにし、更新重みが事前学習された重みとどのように相関しているかの解釈可能性を向上させます。私たちはGPT-3 175Bに焦点を当てて研究を行い、タスクのパフォーマンスに悪影響を与えることなく、訓練可能なパラメータの最大10,000倍の削減を達成しました。
私たちは、以下の質問に答えるために一連の実証研究を行います: 1) パラメータ予算制約がある場合、_事前学習されたTransformerのどの重み行列のサブセット_を適応させるべきか、下流のパフォーマンスを最大化するために? 2) 「最適な」適応行列ΔWΔ𝑊\Delta Wは_本当にランク欠損_しているのか?もしそうなら、実際に使用するのに良いランクは何か? 3) ΔWΔ𝑊\Delta WとW𝑊Wの関係は何か?ΔWΔ𝑊\Delta WはW𝑊Wと高い相関がありますか?ΔWΔ𝑊\Delta WはW𝑊Wと比較してどれくらい大きいのか?
私たちは、質問(2)および(3)への私たちの回答が、下流タスクにおける事前学習済み言語モデルの使用に関する基本的な原則を明らかにするものであると信じています。これはNLPにおいて重要なトピックです。
限られたパラメータ予算のもとで、下流タスクで最良のパフォーマンスを得るためにLoRAで適応すべき重みの種類はどれでしょうか? セクション 4.2で述べたように、自己注意モジュールの重み行列のみを考慮します。GPT-3 175Bに対して18Mのパラメータ予算(FP16で保存すると約35MB)を設定し、1種類の注意重みを適応する場合はr=8𝑟8r=8、2種類を適応する場合はr=4𝑟4r=4となり、すべての96層に対して適用されます。結果は 表 5に示されています。
#の学習可能なパラメータ = 18M
重量タイプ
Wqsubscript𝑊𝑞W_{q}
Wksubscript𝑊𝑘W_{k}
Wvsubscript𝑊𝑣W_{v}
Wosubscript𝑊𝑜W_{o}
Wq,Wksubscript𝑊𝑞subscript𝑊𝑘W_{q},W_{k}
Wq,Wvsubscript𝑊𝑞subscript𝑊𝑣W_{q},W_{v}
Wq,Wk,Wv,Wosubscript𝑊𝑞subscript𝑊𝑘subscript𝑊𝑣subscript𝑊𝑜W_{q},W_{k},W_{v},W_{o}
ランク r𝑟r
8
8
8
8
4
4
2
WikiSQL (±0.5プラスマイナス0.5\pm 0.5%)
70.4
70.0
73.0
73.2
71.4
73.7
73.7
MultiNLI (±0.1プラスマイナス0.1\pm 0.1%)
91.0
90.8
91.0
91.3
91.3
91.3
91.7
表5: 同じ数の学習可能なパラメータを考慮した場合、GPT-3の異なるタイプの注意重みへのLoRAの適用後のWikiSQLおよびMultiNLIにおける検証精度。Wqsubscript𝑊𝑞W_{q}とWvsubscript𝑊𝑣W_{v}の両方を適応させることが全体的に最良のパフォーマンスを発揮します。特定のデータセットに対してランダムシード間の標準偏差が一貫していることがわかり、これを最初の列に報告します。
すべてのパラメータをΔWqΔsubscript𝑊𝑞\Delta W _{q}またはΔWkΔsubscript𝑊𝑘\Delta W _{k}に入れると、パフォーマンスが大幅に低下することに注意してください。一方、両方のWqsubscript𝑊𝑞W _{q}とWvsubscript𝑊𝑣W _{v}を適応させることが最良の結果をもたらします。これは、ランクが4でもΔWΔ𝑊\Delta Wに十分な情報をキャプチャできることを示唆しており、より大きなランクの単一の重みタイプを適応させるよりも、より多くの重み行列を適応させる方が望ましいことを示しています。
モデルの性能に対するランク r𝑟r の影響に注目します。{Wq,Wv}subscript𝑊𝑞subscript𝑊𝑣{W\ ext{q},W\ ext{v}}、{Wq,Wk,Wv,Wc}subscript𝑊𝑞subscript𝑊𝑘subscript𝑊𝑣subscript𝑊𝑐{W\ ext{q},W\ ext{k},W\ ext{v},W\ ext{c}}、および比較のために Wqsubscript𝑊𝑞W\ ext{q} を適応させます。
重量タイプ
r=1𝑟1r=1
r=2𝑟2r=2
r=4𝑟4r=4
r=8𝑟8r=8
r=64𝑟64r=64
WikiSQL(±0.5プラスマイナス0.5\pm 0.5%)
Wqsubscript𝑊𝑞W_{q}
68.8
69.6
70.5
70.4
70.0
Wq,Wvsubscript𝑊𝑞subscript𝑊𝑣W_{q},W_{v}
73.4
73.3
73.7
73.8
73.5
Wq,Wk,Wv,Wosubscript𝑊𝑞subscript𝑊𝑘subscript𝑊𝑣subscript𝑊𝑜W_{q},W_{k},W_{v},W_{o}
74.1
73.7
74.0
74.0
73.9
MultiNLI (±0.1プラスマイナス0.1\pm 0.1%)
Wqsubscript𝑊𝑞W_{q}
90.7
90.9
91.1
90.7
90.7
Wq,Wvsubscript𝑊𝑞subscript𝑊𝑣W_{q},W_{v}
91.3
91.4
91.3
91.6
91.4
Wq,Wk,Wv,Wosubscript𝑊𝑞subscript𝑊𝑘subscript𝑊𝑣subscript𝑊𝑜W_{q},W_{k},W_{v},W_{o}
91.2
91.7
91.7
91.5
91.4
表6: WikiSQLおよびMultiNLIにおける異なるランクr𝑟rでの検証精度。驚くべきことに、ランクが1と小さくても、これらのデータセットでWqsubscript𝑊𝑞W_{q}とWvsubscript𝑊𝑣W_{v}の適応に十分であり、Wqsubscript𝑊𝑞W_{q}単独のトレーニングにはより大きなr𝑟rが必要です。私たちは、セクションH.2でGPT-2に対して同様の実験を行います。
'表6は、驚くべきことに、LoRAが非常に小さなr𝑟rで競争力を持っていることを示しています(特に{Wq,Wv}subscript𝑊𝑞subscript𝑊𝑣{W {q},W{v}}に対して、単にWqsubscript𝑊𝑞W _{q}よりも)。これは、更新行列ΔWΔ𝑊\Delta Wが非常に小さな「固有ランク」を持つ可能性があることを示唆しています。この発見をさらに支持するために、異なるr𝑟rの選択と異なるランダムシードによって学習された部分空間の重複を確認します。r𝑟rを増加させても、より意味のある部分空間をカバーしないことを主張します。これは、低ランク適応行列が十分であることを示唆しています。'
異なる r𝑟r の間のサブスペース類似性。\n\nAr=8subscript𝐴𝑟8A_{r=8} と Ar=64subscript𝐴𝑟64A_{r=64} は、ランク r=8𝑟8r=8 および 646464 の学習された適応行列であり、_同じ事前学習モデル_を使用して、特異値分解を行い、右特異ユニタリ行列 UAr=8subscript𝑈subscript𝐴𝑟8U_{A_{r=8}} と UAr=64subscript𝑈subscript𝐴𝑟64U_{A_{r=64}} を得ます。\n\n私たちは次の質問に答えたいと思います:UAr=8subscript𝑈subscript𝐴𝑟8U_{A_{r=8}} の上位 i𝑖i 特異ベクトルが張るサブスペースのうち、どれだけの部分が UAr=64subscript𝑈subscript𝐴𝑟64U_{A_{r=64}} の上位 j𝑗j 特異ベクトルの張るサブスペースに含まれているのか(1≤i≤81𝑖81\leq i\leq 8 および 1≤j≤641𝑗641\leq j\leq 64)?この量を、グラスマン距離に基づく正規化されたサブスペース類似性で測定します(より正式な議論については Appendix G を参照)。
ϕ(Ar ext{=}8,Ar ext{=}64,i,j) ext{=‖}UAr ext{=}8i⊤UAr ext{=}64j ext{‖}F^{2} ext{min}(i,j) ext{∈}[0,1] ext{italic-}ϕ ext{subscript}A_{r=8} ext{subscript}A_{r=64}ij ext{superscript} ext{subscript} ext{norm} ext{superscript} ext{subscript}U ext{subscript}A_{r=8} ext{limit-from}i ext{top} ext{superscript} ext{subscript}U ext{subscript}A_{r=64}jF^{2}ij01\phi(A_{r=8},A_{r=64},i,j)=\frac{||U_{A_{r=8}}^{i\top}U_{A_{r=64}}^{j}||_{F}^{2}}{\min(i,j)}\in[0,1]
'(4)'
where UAr=8は、上位-i𝑖i特異ベクトルに対応するUAr=8の列を表します。
ϕ(⋅)italic-ϕ⋅\phi(\cdot) の範囲は [0,1]01[0,1] であり、111 は部分空間の完全な重なりを、00 は完全な分離を表します。 ϕitalic-ϕ\phi が i𝑖i と j𝑗j を変化させるとどのように変わるかについては、Figure 3 を参照してください。スペースの制約のため、96 層のうち 48 層のみを見ますが、他の層でも結論は成り立ちます。これは Section H.1 に示されています。
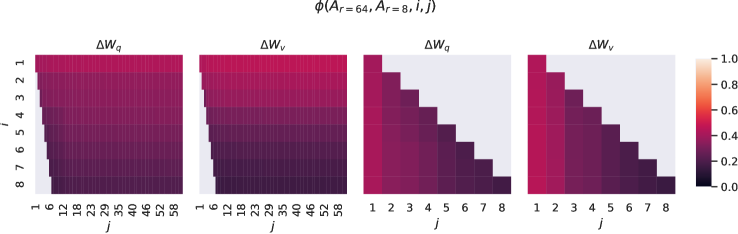
図3: Ar_{r=8}の列ベクトルとAr_{r=64}の間の部分空間類似性、Δ W_{q}およびΔ W_{v}の両方について。3番目と4番目の図は、最初の2つの図の左下の三角形をズームインしています。r=8の上方向はr=64に含まれ、その逆もまた然り。
私たちは図3から_重要な観察_を行います。
方向は、Ar=8subscript𝐴𝑟8A_{r=8} と Ar=64subscript𝐴𝑟64A_{r=64} の間で、最上位の特異ベクトルが大きく重なり合っている一方で、他のものはそうではありません。具体的には、ΔWvΔsubscript𝑊𝑣\Delta W_{v}(および ΔWqΔsubscript𝑊𝑞\Delta W_{q})の Ar=8subscript𝐴𝑟8A_{r=8} と ΔWvΔsubscript𝑊𝑣\Delta W_{v}(および ΔWqΔsubscript𝑊𝑞\Delta W_{q})の Ar=64subscript𝐴𝑟64A_{r=64} は、次元 1 の部分空間を共有し、正規化された類似度が >0.5absent0.5>0.5 であることを示しており、これが r=1𝑟1r=1 が GPT-3 の下流タスクで非常に良好に機能する理由を説明しています。
両方の Ar=8subscript𝐴𝑟8A_{r=8} と Ar=64subscript𝐴𝑟64A_{r=64} が同じ事前学習モデルを使用して学習されているため、Figure 3 は Ar=8subscript𝐴𝑟8A_{r=8} と Ar=64subscript𝐴𝑟64A_{r=64} の最上位の特異ベクトル方向が最も有用であり、他の方向はトレーニング中に蓄積された主にランダムノイズを含む可能性があることを示しています。したがって、適応行列は実際に非常に低いランクを持つことができます。

図4: 左と中央: 2つのランダムシードからのAr=64の列ベクトル間の正規化された部分空間類似度、48層におけるΔWqとΔWvの両方について。右: 2つのランダムガウス行列の列ベクトル間の同じヒートマップ。その他の層についてはSection H.1を参照してください。
異なるランダムシード間のサブスペース類似性。 r=64の2つのランダムシード実行間の正規化されたサブスペース類似性をプロットすることで、これをさらに確認します。これはFigure 4に示されています。ΔWqΔsubscript𝑊𝑞\Delta W a_{q}は、ΔWvΔsubscript𝑊𝑣\Delta W a_{v}よりも「内在的ランク」が高いようです。これは、ΔWqΔsubscript𝑊𝑞\Delta W a_{q}に対して、両方の実行でより一般的な特異値方向が学習されるためであり、これはTable 6での我々の経験的観察と一致しています。比較として、互いに共通の特異値方向を持たない2つのランダムガウス行列もプロットします。
ΔWΔ𝑊\Delta WとW𝑊Wの関係をさらに調査します。特に、ΔWΔ𝑊\Delta WはW𝑊Wと高い相関がありますか?(または数学的に言えば、ΔWΔ𝑊\Delta WはW𝑊Wの主成分方向に主に含まれていますか?)また、ΔWΔ𝑊\Delta WはW𝑊Wの対応する方向と比較して「どれくらい大きい」のでしょうか?これは、事前学習された言語モデルを適応させるための基盤となるメカニズムに光を当てることができます。
これらの質問に答えるために、W𝑊WをΔWΔ𝑊\Delta Wのr𝑟r次元部分空間に射影し、U⊤WV⊤superscript𝑈top𝑊superscript𝑉topU^{\top}WV^{\top}を計算します。ここで、U𝑈U/V𝑉VはΔWΔ𝑊\Delta Wの左/右特異ベクトル行列です。次に、Frobeniusノルムの比較を行います。‖U⊤WV⊤‖Fsubscriptnormsuperscript𝑈top𝑊superscript𝑉top𝐹|U^{\top}WV^{\top}| _{F}と‖W‖Fsubscriptnorm𝑊𝐹|W| _{F}です。比較のために、W𝑊Wの上位r𝑟r特異ベクトルまたはランダム行列でU,V𝑈𝑉U,Vを置き換えることによって、‖U⊤WV⊤‖Fsubscriptnormsuperscript𝑈top𝑊superscript𝑉top𝐹|U^{\top}WV^{\top}| _{F}も計算します。
r=4𝑟4r=4
r=64𝑟64r=64
ΔWqΔsubscript𝑊𝑞\Delta W extsubscript{q}
Wqsubscript𝑊𝑞W_{q}
ランダム
ΔWqΔsubscript𝑊𝑞\Delta W extsubscript{q}
Wqsubscript𝑊𝑞W_{q}
ランダム
‖U^{\top}W_{q}V^{\top}‖_{F}=subscriptnormsuperscript𝑈topsubscript𝑊𝑞superscript𝑉top𝐹absent
0.32
21.67
0.02
1.90
37.71
0.33
‖Wq‖F=61.95subscriptnormsubscript𝑊𝑞𝐹61.95||W_{q}||_{F}=61.95
‖ΔWq‖F=6.91subscriptnormΔsubscript𝑊𝑞𝐹6.91||\Delta W_{q}||_{F}=6.91
‖ΔWq‖F=3.57subscriptnormΔsubscript𝑊𝑞𝐹3.57||\Delta W_{q}||_{F}=3.57
表7: U^{\top}W_{q}V^{\top} のフロベニウスノルム、ここで U と V は (1) Δ W_{q}, (2) W_{q}, または (3) ランダム行列のいずれかの左/右上 r 次の特異ベクトル方向です。重み行列は GPT-3 の第48層から取得されます。
私たちはTable 7から_いくつかの結論_を引き出します。まず、ΔWΔ𝑊\Delta Wは、ランダム行列と比較してW𝑊Wとの相関が強いことを示しており、これはΔWΔ𝑊\Delta WがW𝑊Wに既に存在するいくつかの特徴を増幅していることを示しています。次に、W𝑊Wの上位特異方向を繰り返すのではなく、ΔWΔ𝑊\Delta Wは_W𝑊Wで強調されていない方向のみを増幅します_。第三に、増幅係数はかなり大きいです:21.5≈6.91/0.3221.56.910.3221.5\approx 6.91/0.32、r ext{=}4𝑟4r=4の場合です。r ext{=}64𝑟64r=64がより小さい増幅係数を持つ理由については、Section H.4を参照してください。また、Wqsubscript𝑊𝑞W ext{_{q}}からのより多くの上位特異方向を含めるにつれて相関がどのように変化するかについての視覚化をSection H.3で提供します。これは、低ランク適応行列が、一般的な事前学習モデルで学習されたが強調されていない特定の下流タスクに対して_重要な特徴を増幅する可能性がある_ことを示唆しています。
巨大な言語モデルのファインチューニングは、必要なハードウェアや異なるタスクのための独立したインスタンスをホスティングするためのストレージ/スイッチングコストの点で非常に高価です。私たちはLoRAを提案します。これは、高いモデル品質を維持しながら、推論の遅延を引き起こさず、入力シーケンスの長さを短縮しない効率的な適応戦略です。重要なことに、これはモデルパラメータの大部分を共有することによって、サービスとして展開されたときに迅速なタスクスイッチングを可能にします。私たちはTransformer言語モデルに焦点を当てましたが、提案された原則は密な層を持つ任意のニューラルネットワークに一般的に適用可能です。
将来の研究には多くの方向性があります。1) LoRAは他の効率的な適応方法と組み合わせることができ、直交的な改善を提供する可能性があります。2) ファインチューニングやLoRAの背後にあるメカニズムは明確ではありません – 事前学習中に学習された特徴がどのようにして下流のタスクでうまく機能するように変換されるのか?私たちは、LoRAがフルファインチューニングよりもこの問いに答えやすくすると思います。3) 私たちは主にヒューリスティックに依存してLoRAを適用する重み行列を選択しています。より原理的な方法はありますか?4) 最後に、ΔWのランク欠損は、Wもランク欠損である可能性があることを示唆しており、これも将来の研究のインスピレーションの源となる可能性があります。
Few-shot learning、またはプロンプトエンジニアリングは、トレーニングサンプルがわずかしかない場合に非常に有利です。しかし、実際には、パフォーマンスに敏感なアプリケーションのために、数千以上のトレーニング例をキュレーションする余裕があることがよくあります。 Table 8に示されているように、ファインチューニングは、少数ショット学習と比較して、大規模および小規模のデータセットでモデルのパフォーマンスを劇的に改善します。私たちは、GPT-3論文 (Brown et al., 2020)からRTEにおけるGPT-3の少数ショット結果を取ります。MNLI-matchedについては、クラスごとに2つのデモンストレーションと、合計6つの文脈内例を使用します。
方法
MNLI-m (検証精度/%)
RTE (評価. アクセス/%)
GPT-3 フューシャット
40.6
69.0
GPT-3 微調整
89.5
85.4
表8: ファインチューニングはGPT-3での少数ショット学習を大幅に上回る (Brown et al., 2020).
アダプターレイヤーは、事前学習済みモデルに順次追加される外部モジュールですが、我々の提案であるLoRAは、並行して追加される外部モジュールと見なすことができます。その結果、アダプターレイヤーはベースモデルに加えて計算される必要があり、必然的に追加のレイテンシを導入します。Rücklé et al. (2020)で指摘されているように、アダプターレイヤーによって導入されるレイテンシは、モデルのバッチサイズやシーケンスの長さが十分に大きく、ハードウェアの並列性を完全に活用できる場合に軽減される可能性があります。我々は、GPT-2 mediumに関する類似のレイテンシ研究を通じて彼らの観察を確認し、バッチサイズが小さいオンライン推論など、追加のレイテンシが重要になるシナリオが存在することを指摘します。
NVIDIA Quadro RTX8000での単一のフォワードパスのレイテンシを100回の試行の平均を取ることで測定します。入力バッチサイズ、シーケンス長、およびアダプターボトルネック次元r𝑟rを変化させます。2つのアダプターデザインをテストします:Houlsby et al.による元のデザイン(2019)、これをAdapterHsuperscriptAdapterH\text{Adapter}^{\text{H}}と呼び、Lin et al.による最近のより効率的なバリアント(2020)、これをAdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}}と呼びます。デザインの詳細については、Section 5.1を参照してください。アダプターベースラインがない場合と比較したパーセンテージでのスローダウンをFigure 5にプロットします。
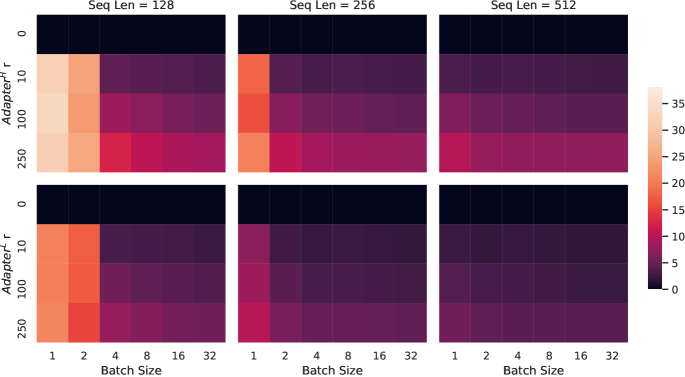
図5: アダプターなし(r=0)ベースラインと比較した推論レイテンシのパーセンテージの遅延。上段はAdapterH\text{Adapter}^{\text{H}}の結果を示し、下段はAdapterL\text{Adapter}^{\text{L}}の結果を示します。バッチサイズとシーケンス長を大きくすることでレイテンシを軽減できますが、オンラインの短いシーケンス長のシナリオでは遅延が30%を超えることがあります。可視性を向上させるためにカラーマップを調整します。
GLUEベンチマークは、幅広い自然言語理解タスクのコレクションです。これには、MNLI(推論、Williams et al. (2018))、SST-2(感情分析、Socher et al. (2013))、MRPC(パラフレーズ検出、Dolan & Brockett (2005))、CoLA(言語的受容性、Warstadt et al. (2018))、QNLI(推論、Rajpurkar et al. (2018))、QQP(質問応答)、RTE(推論)、およびSTS-B(テキスト類似性、Cer et al. (2017))が含まれます。広範なカバレッジにより、GLUEベンチマークはRoBERTaやDeBERTaなどのNLUモデルを評価するための標準的な指標となっています。個々のデータセットは、異なる許可されたライセンスの下でリリースされています。
WikiSQLはZhong et al. (2017)で紹介され、56,3555635556,355/8,42184218,421のトレーニング/検証例を含みます。このタスクは、自然言語の質問とテーブルスキーマからSQLクエリを生成することです。コンテキストをx={table schema,query}𝑥table schemaqueryx={\text{table schema},\text{query}}としてエンコードし、ターゲットをy={SQL}𝑦SQLy={\text{SQL}}としてエンコードします。このデータセットはBSD 3-Clause Licenseの下でリリースされています。
SAMSumはGliwa et al. (2019)で紹介され、14,7321473214,732/819819819のトレーニング/テスト例を含みます。それは二人の間の段階的なチャット会話と、言語学者によって書かれた対応する抽象的な要約から成ります。文脈は「\n」で連結された発話の後に「\n\n」を付けてエンコードし、ターゲットはy={summary}𝑦summaryy={\text{summary}}とします。このデータセットは非商用ライセンスの下でリリースされています:クリエイティブ・コモンズ BY-NC-ND 4.0.
E2E NLG Challengeは、Novikova et al. (2017)で初めて導入され、エンドツーエンドのデータ駆動型自然言語生成システムのトレーニング用データセットとして使用され、データからテキストへの評価に一般的に使用されます。E2Eデータセットは、レストランドメインからの約42,000のトレーニング、4,600の検証、および4,600のテスト例で構成されています。入力として使用される各ソーステーブルは、複数の参照を持つことができます。各サンプル入力 (x,y)𝑥𝑦(x,y) は、スロット-バリューペアのシーケンスと、それに対応する自然言語の参照テキストで構成されています。このデータセットは、Creative Commons BY-NC-SA 4.0の下でリリースされています。
DARTは、Nan et al.によって説明されたオープンドメインのデータからテキストへのデータセットです(2020)。DARTの入力は、ENTITY — RELATION — ENTITYのトリプルのシーケンスとして構成されています。合計82Kの例があり、DARTはE2Eと比較して、はるかに大きく、より複雑なデータからテキストへのタスクです。このデータセットはMITライセンスの下でリリースされています。
WebNLGは、データからテキストへの評価に一般的に使用される別のデータセットです (Gardent et al., 2017)。合計22Kの例があり、WebNLGは14の異なるカテゴリで構成されており、そのうち9つはトレーニング中に見られます。14のカテゴリのうち5つはトレーニング中に見られませんが、テストセットには含まれているため、評価は通常「見た」カテゴリ (S)、「見ていない」カテゴリ (U) および「すべて」 (A) に分けられます。各入力例は、SUBJECT — PROPERTY — OBJECTのトリプルのシーケンスで表されます。このデータセットは、Creative Commons BY-NC-SA 4.0の下で公開されています。
私たちは、線形学習率減衰スケジュールを使用してAdamWでトレーニングします。LoRAのために、学習率、トレーニングエポック数、およびバッチサイズをスイープします。Liu et al. (2019)に従い、MRPC、RTE、およびSTS-Bに適応する際に、通常の初期化の代わりに、LoRAモジュールを私たちの最良のMNLIチェックポイントに初期化します; 事前トレーニングされたモデルはすべてのタスクで固定されたままです。私たちは5つのランダムシードの中央値を報告します; 各実行の結果は最良のエポックから取得されます。Houlsby et al. (2019)およびPfeiffer et al. (2021)のセットアップと公正に比較するために、モデルのシーケンス長を128に制限し、すべてのタスクに対して固定バッチサイズを使用しました。重要なことに、MRPC、RTE、およびSTS-Bに適応する際には、MNLIにすでに適応されたモデルの代わりに、事前トレーニングされたRoBERTa大モデルから始めます。この制限されたセットアップでの実行は††\daggerでマークされています。私たちの実行で使用されたハイパーパラメータはTable 9に示されています。
方法
データセット
MNLI
SST-2
MRPC
コーラ
QNLI
QQP
RTE
STS-B
オプティマイザー
アダムW
ウォームアップ比
0.06
LR スケジュール
線形
RoBERTa base LoRA
バッチサイズ
16
16
16
32
32
16
32
16
エポック
30
60
30
80
25
25
80
40
学習率
5E-04
5E-04
4E-04
4E-04
4E-04
5E-04
5E-04
4E-04
LoRA 設定。
rq=rv=8subscript𝑟𝑞subscript𝑟𝑣8r_{q}=r_{v}=8
LoRA α𝛼\alpha
8
最大シーケンス長
512
RoBERTa large LoRA
バッチサイズ
4
4
4
4
4
4
8
8
エポック
10
10
20
20
10
20
20
30
学習率
3E-04
4E-04
3E-04
2E-04
2E-04
3E-04
4E-04
2E-04
LoRA 設定。
rq=rv=8subscript𝑟𝑞subscript𝑟𝑣8r_{q}=r_{v}=8
LoRA α𝛼\alpha
16
最大シーケンス長
128
128
512
128
512
512
512
512
RoBERTa large LoRA††\dagger
バッチサイズ
4
エポック
10
10
20
20
10
20
20
10
学習率
3E-04
4E-04
3E-04
2E-04
2E-04
3E-04
4E-04
2E-04
LoRA 設定。
rq=rv=8subscript𝑟𝑞subscript𝑟𝑣8r_{q}=r_{v}=8
LoRA α𝛼\alpha
16
最大シーケンス長
128
RoBERTa large AdptPsuperscriptAdptP\text{Adpt}^{\text{P}} (3M)††\dagger
バッチサイズ
32
エポック
10
20
20
20
10
20
20
20
学習率
3E-05
3E-05
3E-04
3E-04
3E-04
3E-04
3E-04
3E-04
ボトルネック r𝑟r
64
最大シーケンス長
128
RoBERTa large AdptPsuperscriptAdptP\text{Adpt}^{\text{P}} (0.8M)††\dagger
バッチサイズ
32
エポック
5
20
20
20
10
20
20
20
学習率
3E-04
3E-04
3E-04
3E-04
3E-04
3E-04
3E-04
3E-04
ボトルネック r𝑟r
16
最大シーケンス長
128
RoBERTa large AdptHsuperscriptAdptH\text{Adpt}^{\text{H}} (6M)††\dagger
バッチサイズ
32
エポック
10
5
10
10
5
20
20
10
学習率
3E-05
3E-04
3E-04
3E-04
3E-04
3E-04
3E-04
3E-04
ボトルネック r𝑟r
64
最大シーケンス長
128
RoBERTa large AdptHsuperscriptAdptH\text{Adpt}^{\text{H}} (0.8M)††\dagger
バッチサイズ
32
エポック
10
5
10
10
5
20
20
10
学習率
3E-04
3E-04
3E-04
3E-04
3E-04
3E-04
3E-04
3E-04
ボトルネック r𝑟r
8
最大シーケンス長
128
表9: GLUEベンチマークにおけるRoBERTaのために使用したハイパーパラメータ。
再び、線形学習率減衰スケジュールを用いてAdamWで訓練します。He et al. (2021) に従い、学習率、ドロップアウト確率、ウォームアップステップ、およびバッチサイズを調整します。比較を公平に保つために、(He et al., 2021) が使用したのと同じモデルシーケンス長を使用します。He et al. (2021) に従い、MRPC、RTE、およびSTS-Bに適応する際に、LoRAモジュールを最良のMNLIチェックポイントに初期化します。通常の初期化ではなく、すべてのタスクに対して事前訓練されたモデルは固定されたままです。5つのランダムシードの中央値を報告します。各実行の結果は最良のエポックから取得されます。私たちの実行で使用したハイパーパラメータはTable 10に示されています。
方法
データセット
MNLI
SST-2
MRPC
コーラ
QNLI
QQP
RTE
'STS-B'
オプティマイザー
アダムW
ウォームアップ比
0.1
LR スケジュール
線形
DeBERTa XXL LoRA
バッチサイズ
8
8
32
4
6
8
4
4
エポック
5
16
30
10
8
11
11
10
学習率
1E-04
6E-05
2E-04
1E-04
1E-04
1E-04
2E-04
2E-04
重み減衰
0
0.01
0.01
0
0.01
0.01
0.01
0.1
CLS ドロップアウト
0.15
0
0
0.1
0.1
0.2
0.2
0.2
LoRA 設定。
rq=rv=8subscript𝑟𝑞subscript𝑟𝑣8r_{q}=r_{v}=8
LoRA α𝛼\alpha
8
最大シーケンス長
256
128
128
64
512
320
320
128
表10: GLUEベンチマークに含まれるタスクに対するDeBERTa XXLのハイパーパラメータ。
私たちは、すべてのGPT-2モデルをAdamW (Loshchilov & Hutter, 2017)を使用して、5エポックの線形学習率スケジュールで訓練します。バッチサイズ、学習率、およびビームサーチのビームサイズは、Li & Liang (2021)で説明されているものを使用します。それに応じて、LoRAのために上記のハイパーパラメータも調整します。3つのランダムシードの平均を報告します; 各実行の結果は最良のエポックから取得されます。GPT-2におけるLoRAのために使用されるハイパーパラメータは、Table 11にリストされています。他のベースラインに使用されるものについては、Li & Liang (2021)を参照してください。
データセット
E2E
WebNLG
DART
トレーニング
オプティマイザー
アダムW
重み減衰
0.01
0.01
0.0
ドロップアウト確率
0.1
0.1
0.0
バッチサイズ
8
# エポック
5
ウォームアップステップ
500
学習率スケジュール
線形
ラベル スムーズ
0.1
0.1
0.0
学習率
0.0002
適応
rq=rv=4subscript𝑟𝑞subscript𝑟𝑣4r_{q}=r_{v}=4
LoRA α𝛼\alpha
32
推論
ビームサイズ
10
長さペナルティ
0.9
0.8
0.8
n-gramサイズを繰り返さない
4
表11: E2E、WebNLG、DARTにおけるGPT-2 LoRAのハイパーパラメータ。
すべてのGPT-3実験では、AdamW (Loshchilov & Hutter, 2017)を使用して、128サンプルのバッチサイズで2エポックのトレーニングを行います。WikiSQL (Zhong et al., 2017)には384のシーケンス長、MNLI (Williams et al., 2018)には768、SAMSum (Gliwa et al., 2019)には2048を使用します。すべてのメソッド-データセットの組み合わせに対して学習率を調整します。ハイパーパラメータの詳細については、Section D.4を参照してください。プレフィックス埋め込みの調整では、最適なlpsubscript𝑙𝑝l_{p}とlisubscript𝑙𝑖l_{i}はそれぞれ256と8であり、合計で3.2M3.2𝑀3.2Mの学習可能なパラメータがあります。プレフィックスレイヤーの調整にはlp ext{=}8subscript𝑙𝑝8l_{p}=8およびli ext{=}8subscript𝑙𝑖8l_{i}=8を使用し、20.2M20.2𝑀20.2Mの学習可能なパラメータで全体的に最良のパフォーマンスを得ます。LoRAのための2つのパラメータ予算を提示します:4.7M (rq ext{=}rv ext{=}1subscript𝑟𝑞subscript𝑟𝑣1r_{q}=r_{v}=1またはrv ext{=}2subscript𝑟𝑣2r_{v}=2)および37.7M (rq ext{=}rv ext{=}8subscript𝑟𝑞subscript𝑟𝑣8r_{q}=r_{v}=8またはrq ext{=}rk ext{=}rv ext{=}ro ext{=}2subscript𝑟𝑞subscript𝑟𝑘subscript𝑟𝑣subscript𝑟𝑜2r_{q}=r_{k}=r_{v}=r_{o}=2)。各実行からの最良の検証パフォーマンスを報告します。私たちのGPT-3実験で使用されたトレーニングハイパーパラメータは、Table 12にリストされています。
ハイパーパラメータ
微調整
プレエンベッド
プレレイヤー
ビットフィット
AdapterHsuperscriptAdapterH\text{Adapter}^{\text{H}}
LoRA
オプティマイザー
アダムW
バッチサイズ
128
# エポック
2
ウォームアップトークン
250,000
LR スケジュール
線形
学習率
5.00E-06
5.00E-04
1.00E-04
1.6E-03
1.00E-04
2.00E-04
表12: 異なるGPT-3適応方法に使用されるトレーニングハイパーパラメータ。学習率を調整した後、すべてのデータセットに同じハイパーパラメータを使用します。
LoRAは既存のプレフィックスベースのアプローチと自然に組み合わせることができます。このセクションでは、WikiSQLとMNLIにおけるLoRAとプレフィックスチューニングのバリアントの2つの組み合わせを評価します。
LoRA+PrefixEmbed (LoRA+PE) は、LoRA とプレフィックス埋め込みチューニングを組み合わせたもので、lp+lisubscript𝑙𝑝subscript𝑙𝑖l_{p}+l_{i} 特殊トークンを挿入し、その埋め込みを学習可能なパラメータとして扱います。プレフィックス埋め込みチューニングの詳細については、Section 5.1 を参照してください。
LoRA+PrefixLayer (LoRA+PL) は、LoRA とプレフィックスレイヤーチューニングを組み合わせたものです。私たちはまた、lp+lisubscript𝑙𝑝subscript𝑙𝑖l_{p}+l_{i} 特殊トークンを挿入します。しかし、これらのトークンの隠れ表現が自然に進化するのを許すのではなく、各 Transformer ブロックの後に入力に依存しないベクトルで置き換えます。したがって、埋め込みとその後の Transformer ブロックの活性化の両方が訓練可能なパラメータとして扱われます。プレフィックスレイヤーチューニングの詳細については、Section 5.1 を参照してください。
In 表15, 我々はWikiSQLとMultiNLIにおけるLoRA+PEとLoRA+PLの評価結果を示します。まず第一に、LoRA+PEはWikiSQLにおいてLoRAおよびプレフィックス埋め込みチューニングの両方を大きく上回っており、これはLoRAがプレフィックス埋め込みチューニングに対してある程度直交していることを示しています。MultiNLIでは、LoRA+PEの組み合わせはLoRAよりも良いパフォーマンスを発揮しません。これは、LoRA単体ですでに人間のベースラインに匹敵するパフォーマンスを達成しているためかもしれません。第二に、LoRA+PLはより多くの学習可能なパラメータを持っているにもかかわらず、LoRAよりもわずかにパフォーマンスが劣ることに気付きました。これは、プレフィックスレイヤーチューニングが学習率の選択に非常に敏感であり、そのためLoRA+PLにおけるLoRAの重みの最適化がより困難になることに起因しています。
私たちはまた、DART (Nan et al., 2020)およびWebNLG (Gardent et al., 2017)において、Li & Liang (2021)の設定に従って実験を繰り返します。結果はTable 13に示されています。E2E NLG Challengeに関する私たちの結果と同様に、Section 5で報告されているように、LoRAは同じ数の学習可能なパラメータを考慮した場合、プレフィックスベースのアプローチよりも優れているか、少なくとも同等の性能を発揮します。
方法
# 学習可能
DART
パラメータ
BLEU↑↑\uparrow
MET↑↑\uparrow
TER↓↓\downarrow
GPT-2 ミディアム
微調整
354M
46.2
0.39
0.46
AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}}
0.37M
42.4
0.36
0.48
AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}}
11M
45.2
0.38
0.46
FTTop2の上付き文字FTTop2\text{FT}^{\text{Top2}}
24M
41.0
0.34
0.56
PrefLayer
0.35M
46.4
0.38
0.46
LoRA
0.35M
47.1±プラスマイナス\pm.2
0.39
0.46
GPT-2 Large
微調整
774M
47.0
0.39
0.46
AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}}
0.88M
45.7±プラスマイナス\pm.1
0.38
0.46
AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}}
23M
47.1±プラスマイナス\pm.1
0.39
0.45
PrefLayer
0.77M
46.7
0.38
0.45
LoRA
0.77M
47.5±プラスマイナス\pm.1
0.39
0.45
表13: DARTにおける異なる適応方法を用いたGPT-2。METとTERの分散は、すべての適応アプローチに対して0.010.010.01未満です。
方法
WebNLG
BLEU↑↑\uparrow
MET↑↑\uparrow
TER↓↓\downarrow
U
S
A
U
S
A
U
S
A
GPT-2 ミディアム
ファインチューニング (354M)
27.7
64.2
46.5
.30
.45
.38
.76
.33
.53
AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}} (0.37M)
45.1
54.5
50.2
.36
.39
.38
.46
.40
.43
AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}} (11M)
48.3
60.4
54.9
.38
.43
.41
.45
.35
.39
FTTop2上付き文字FTTop2\text{FT}^{\text{Top2}} (24M)
18.9
53.6
36.0
.23
.38
.31
.99
.49
.72
接頭辞 (0.35M)
45.6
62.9
55.1
.38
.44
.41
.49
.35
.40
LoRA (0.35M)
46.7±プラスマイナス\pm.4
62.1±プラスマイナス\pm.2
55.3±プラスマイナス\pm.2
.38
.44
.41
.46
.33
.39
GPT-2 Large
ファインチューニング (774M)
43.1
65.3
55.5
.38
.46
.42
.53
.33
.42
AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}} (0.88M)
49.8±プラスマイナス\pm.0
61.1±プラスマイナス\pm.0
56.0±プラスマイナス\pm.0
.38
.43
.41
.44
.35
.39
AdapterLsuperscriptAdapterL\text{Adapter}^{\text{L}} (23M)
49.2±プラスマイナス\pm.1
64.7±プラスマイナス\pm.2
57.7±プラスマイナス\pm.1
.39
.46
.43
.46
.33
.39
接頭辞 (0.77M)
47.7
63.4
56.3
.39
.45
.42
.48
.34
.40
LoRA (0.77M)
48.4±プラスマイナス\pm.3
64.0±プラスマイナス\pm.3
57.0±プラスマイナス\pm.1
.39
.45
.42
.45
.32
.38
表 14: WebNLG における異なる適応方法を用いた GPT-2。私たちが実施したすべての実験において、MET と TER の分散は 0.010.010.01 未満です。「U」は未見のカテゴリを、「S」は見たカテゴリを、「A」は WebNLG のテストセットにおけるすべてのカテゴリを示します。
GPT-3における異なる適応方法での追加の実行をTable 15に示します。焦点は、パフォーマンスと学習可能なパラメータの数とのトレードオフを特定することにあります。
方法
ハイパーパラメータ
学習可能なパラメータ
ウィキSQL
MNLI-m
微調整
-
175B
73.8
89.5
PrefixEmbed
lp=32,li=8formulae-sequencesubscript𝑙𝑝32subscript𝑙𝑖8l_{p}=32,l_{i}=8
0.4 M
55.9
84.9
lp=64,li=8formulae-sequencesubscript𝑙𝑝64subscript𝑙𝑖8l_{p}=64,l_{i}=8
0.9 M
58.7
88.1
lp=128,li=8formulae-sequencesubscript𝑙𝑝128subscript𝑙𝑖8l_{p}=128,l_{i}=8
1.7 M
60.6
88.0
lp=256,li=8formulae-sequencesubscript𝑙𝑝256subscript𝑙𝑖8l_{p}=256,l_{i}=8
3.2 M
63.1
88.6
lp=512,li=8formulae-sequencesubscript𝑙𝑝512subscript𝑙𝑖8l_{p}=512,l_{i}=8
6.4 M
55.9
85.8
プレフィックスレイヤー
lp=2,li=2formulae-sequencesubscript𝑙𝑝2subscript𝑙𝑖2l_{p}=2,l_{i}=2
5.1 M
68.5
89.2
lp=8,li=0formulae-sequencesubscript𝑙𝑝8subscript𝑙𝑖0l_{p}=8,l_{i}=0
10.1 M
69.8
88.2
lp=8,li=8formulae-sequencesubscript𝑙𝑝8subscript𝑙𝑖8l_{p}=8,l_{i}=8
20.2 M
70.1
89.5
lp=32,li=4formulae-sequencesubscript𝑙𝑝32subscript𝑙𝑖4l_{p}=32,l_{i}=4
44.1 M
66.4
89.6
lp=64,li=0formulae-sequencesubscript𝑙𝑝64subscript𝑙𝑖0l_{p}=64,l_{i}=0
76.1 M
64.9
87.9
AdapterHsuperscriptAdapterH\text{Adapter}^{\text{H}}
r=1𝑟1r=1
7.1 M
71.9
89.8
r=4𝑟4r=4
21.2 M
73.2
91.0
r=8𝑟8r=8
40.1 M
73.2
91.5
r=16𝑟16r=16
77.9 M
73.2
91.5
r=64𝑟64r=64
304.4 M
72.6
91.5
LoRA
rv=2subscript𝑟𝑣2r_{v}=2
4.7 M
73.4
91.7
rq=rv=1subscript𝑟𝑞subscript𝑟𝑣1r_{q}=r_{v}=1
4.7 M
73.4
91.3
rq=rv=2subscript𝑟𝑞subscript𝑟𝑣2r_{q}=r_{v}=2
9.4 M
73.3
91.4
rq=rk=rv=ro=1subscript𝑟𝑞subscript𝑟𝑘subscript𝑟𝑣subscript𝑟𝑜1r_{q}=r_{k}=r_{v}=r_{o}=1
9.4 M
74.1
91.2
rq=rv=4subscript𝑟𝑞subscript𝑟𝑣4r_{q}=r_{v}=4
18.8 M
73.7
91.3
rq=rk=rv=ro=2subscript𝑟𝑞subscript𝑟𝑘subscript𝑟𝑣subscript𝑟𝑜2r_{q}=r_{k}=r_{v}=r_{o}=2
18.8 M
73.7
91.7
rq=rv=8subscript𝑟𝑞subscript𝑟𝑣8r_{q}=r_{v}=8
37.7 M
73.8
91.6
rq=rk=rv=ro=4subscript𝑟𝑞subscript𝑟𝑘subscript𝑟𝑣subscript𝑟𝑜4r_{q}=r_{k}=r_{v}=r_{o}=4
37.7 M
74.0
91.7
rq=rv=64subscript𝑟𝑞subscript𝑟𝑣64r_{q}=r_{v}=64
301.9 M
73.6
91.4
rq=rk=rv=ro=64subscript𝑟𝑞subscript𝑟𝑘subscript𝑟𝑣subscript𝑟𝑜64r_{q}=r_{k}=r_{v}=r_{o}=64
603.8 M
73.9
91.4
LoRA+PE
rq=rv=8,lp=8,li=4formulae-sequencesubscript𝑟𝑞subscript𝑟𝑣8formulae-sequencesubscript𝑙𝑝8subscript𝑙𝑖4r_{q}=r_{v}=8,l_{p}=8,l_{i}=4
37.8 M
75.0
91.4
rq=rv=32,lp=8,li=4formulae-sequencesubscript𝑟𝑞subscript𝑟𝑣32formulae-sequencesubscript𝑙𝑝8subscript𝑙𝑖4r_{q}=r_{v}=32,l_{p}=8,l_{i}=4
151.1 M
75.9
91.1
rq=rv=64,lp=8,li=4formulae-sequencesubscript𝑟𝑞subscript𝑟𝑣64formulae-sequencesubscript𝑙𝑝8subscript𝑙𝑖4r_{q}=r_{v}=64,l_{p}=8,l_{i}=4
302.1 M
76.2
91.3
LoRA+PL
rq=rv=8,lp=8,li=4formulae-sequencesubscript𝑟𝑞subscript𝑟𝑣8formulae-sequencesubscript𝑙𝑝8subscript𝑙𝑖4r_{q}=r_{v}=8,l_{p}=8,l_{i}=4
52.8 M
72.9
90.2
表15: WikiSQLおよびMNLIにおける異なる適応アプローチのハイパーパラメータ分析。プレフィックス埋め込みチューニング(PrefixEmbed)とプレフィックスレイヤーチューニング(PrefixLayer)は、学習可能なパラメータの数を増やすとパフォーマンスが悪化しますが、LoRAのパフォーマンスは安定します。パフォーマンスは検証精度で測定されます。
低データ領域におけるさまざまな適応アプローチのパフォーマンスを評価するために、MNLIの完全なトレーニングセットからランダムに100、1k、10kのトレーニング例をサンプリングして、低データMNLI-n𝑛nタスクを形成します。Table 16では、MNLI-n𝑛nにおけるさまざまな適応アプローチのパフォーマンスを示します。驚くべきことに、PrefixEmbedとPrefixLayerはMNLI-100データセットで非常に悪いパフォーマンスを示し、PrefixEmbedはランダムなチャンス(37.6%対33.3%)よりもわずかに良いだけです。PrefixLayerはPrefixEmbedよりも良いパフォーマンスを示しますが、MNLI-100におけるFine-TuneやLoRAよりも依然として大幅に劣っています。トレーニング例の数を増やすにつれて、プレフィックスベースのアプローチとLoRA/Fine-tuningの間のギャップは小さくなり、これはプレフィックスベースのアプローチがGPT-3の低データタスクには適していない可能性を示唆しています。LoRAはMNLI-100およびMNLI-Fullの両方でファインチューニングよりも優れたパフォーマンスを達成し、MNLI-1kおよびMNLI-10Kではランダムシードによる(±0.3plus-or-minus0.3\pm 0.3)のばらつきを考慮すると同等の結果を示します。
方法
MNLI(m)-100
MNLI(m)-1k
MNLI(m)-10k
MNLI(m)-392K
GPT-3 (ファインチューニング)
60.2
85.8
88.9
89.5
GPT-3 (PrefixEmbed)
37.6
75.2
79.5
88.6
GPT-3 (プレフィックスレイヤー)
48.3
82.5
85.9
89.6
GPT-3 (LoRA)
63.8
85.6
89.2
91.7
表16: GPT-3 175Bを使用したMNLIのサブセットにおける異なる手法の検証精度。MNLI-n𝑛nはn𝑛nのトレーニング例を持つサブセットを示します。完全な検証セットで評価します。LoRAは、ファインチューニングを含む他の手法と比較して、好ましいサンプル効率を示します。
異なる適応アプローチのMNLI-nにおけるトレーニングハイパーパラメータはTable 17に報告されています。トレーニング損失が大きな学習率では減少しないため、MNLI-100セットのPrefixLayerにはより小さな学習率を使用します。
ハイパーパラメータ
適応
MNLI-100
MNLI-1k
MNLI-10K
MNLI-392K
オプティマイザー
-
アダムW
ウォームアップトークン
-
250,000
LR スケジュール
-
線形
バッチサイズ
-
20
20
100
128
# エポック
-
40
40
4
2
学習率
ファインチューニング
5.00E-6
PrefixEmbed
2.00E-04
2.00E-04
4.00E-04
5.00E-04
プレフィックスレイヤー
5.00E-05
5.00E-05
5.00E-05
1.00E-04
LoRA
2.00E-4
PrefixEmbed lpsubscript𝑙𝑝l_{p}
16
32
64
256
適応-
PrefixEmbed lisubscript𝑙𝑖l_{i}
8
特定の
プレフィックスチューン
lp=li=8subscript𝑙𝑝subscript𝑙𝑖8l_{p}=l_{i}=8
LoRA
rq=rv=8subscript𝑟𝑞subscript𝑟𝑣8r_{q}=r_{v}=8
表17: MNLI(m)-n𝑛nにおける異なるGPT-3適応方法に使用されるハイパーパラメータ。
この論文では、2つの列直交正規行列 U_{A}^{i} \in \mathbb{R}^{d\times i} と U_{B}^{j} \in \mathbb{R}^{d\times j} の部分空間の類似性を測定するために、次の測度を使用します:\phi(A,B,i,j)=\psi(U_{A}^{i},U_{B}^{j})=\frac{|U_{A}^{i\top}U_{B}|_{F}^{2}}{\min{i,j}}。これは、行列 A と B の左特異行列の列を取り出すことによって得られます。この類似性は、部分空間間の距離を測定する標準の投影メトリックの逆であることを指摘します Ham & Lee (2008)。
具体的には、U_{A}^{i\top}U_{B}^{j}の特異値をσ_{1},σ_{2},⋯,σ_{p}とし、ここでp=\min{i,j}とします。Projection Metric Ham & Lee (2008)は次のように定義されます:
d(U_{A}^{i},U_{B}^{j})=\sqrt{p-\sum_{i=1}^{p}\sigma_{i}^{2}}\in[0,\sqrt{p}]
私たちの類似性は次のように定義されます:
ϕ(A,B,i,j)=ψ(UAi,UBj)=∑i=1pσi2p=1p(1−d(UAi,UBj)2)italic-ϕ𝐴𝐵𝑖𝑗𝜓superscriptsubscript𝑈𝐴𝑖superscriptsubscript𝑈𝐵𝑗superscriptsubscript𝑖1𝑝superscriptsubscript𝜎𝑖2𝑝1𝑝1𝑑superscriptsuperscriptsubscript𝑈𝐴𝑖superscriptsubscript𝑈𝐵𝑗2\phi(A,B,i,j)=\psi(U_{A}^{i},U_{B}^{j})=\frac{\sum_{i=1}^{p}\sigma_{i}^{2}}{p}=\frac{1}{p}\left(1-d(U_{A}^{i},U_{B}^{j})^{2}\right)
この類似性は、もしUAisuperscriptsubscript𝑈𝐴𝑖U_{A}^{i}とUBjsuperscriptsubscript𝑈𝐵𝑗U_{B}^{j}が同じ列のスパンを共有するならば、ϕ(A,B,i,j)=1であることを満たします。もしそれらが完全に直交しているならば、ϕ(A,B,i,j)=0です。そうでなければ、ϕ(A,B,i,j)∈(0,1)です。
低ランク更新行列に関する我々の調査からの追加結果を提示します。
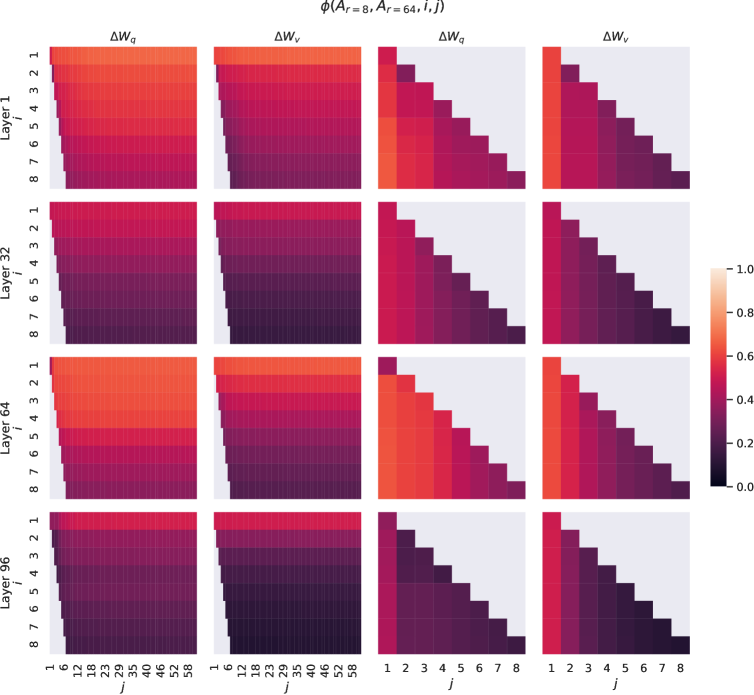
図6: 96層のTransformerにおける1層目、32層目、64層目、96層目からのΔWqΔsubscript𝑊𝑞\Delta W_{q}およびΔWvΔsubscript𝑊𝑣\Delta W_{v}に対するAr =8subscript𝐴𝑟8A_{r=8}とAr =64subscript𝐴𝑟64A_{r=64}の列ベクトル間の正規化された部分空間類似度。
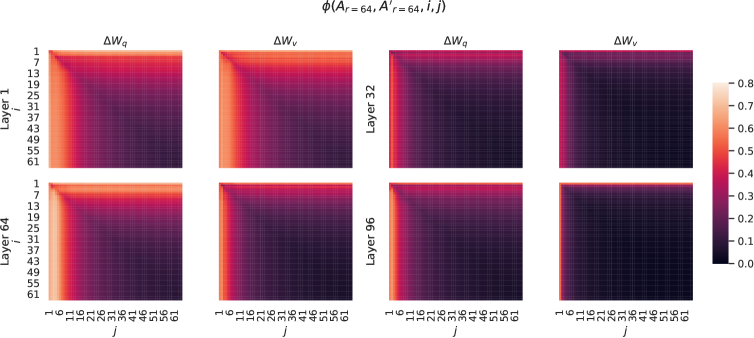
図7: 2つのランダムシードされた実行からのAr=64の列ベクトル間の正規化された部分空間類似性、96層のTransformerの1層目、32層目、64層目、96層目におけるΔWqとΔWvの両方について。
我々はGPT-2におけるr𝑟rの効果についての実験を繰り返します(セクション 7.2)。E2E NLGチャレンジデータセットを例として使用し、26,000ステップのトレーニング後に異なるr𝑟rの選択によって達成された検証損失とテストメトリックを報告します。結果は表 18に示します。GPT-2 Mediumの最適ランクは、使用されるメトリックに応じて4から16の間であり、これはGPT-3 175Bのそれと類似しています。モデルサイズと適応のための最適ランクとの関係は、依然として未解決の問題であることに注意してください。
ランク r𝑟r
val ext{loss}
BLEU
NIST
流星
ROUGE\_L
CIDEr
1
1.23
68.72
8.7215
0.4565
0.7052
2.4329
2
1.21
69.17
8.7413
0.4590
0.7052
2.4639
4
1.18
70.38
8.8439
0.4689
0.7186
2.5349
8
1.17
69.57
8.7457
0.4636
0.7196
2.5196
16
1.16
69.61
8.7483
0.4629
0.7177
2.4985
32
1.16
69.33
8.7736
0.4642
0.7105
2.5255
64
1.16
69.24
8.7174
0.4651
0.7180
2.5070
128
1.16
68.73
8.6718
0.4628
0.7127
2.5030
256
1.16
68.92
8.6982
0.4629
0.7128
2.5012
512
1.16
68.78
8.6857
0.4637
0.7128
2.5025
1024
1.17
69.37
8.7495
0.4659
0.7149
2.5090
表18: LoRAによるE2E NLGチャレンジでの検証損失とテストセットメトリクス、異なるランクr𝑟rを使用したGPT-2 Medium。GPT-3ではr=1𝑟1r=1で多くのタスクに十分であるのに対し、ここでは検証損失でr=16𝑟16r=16、BLEUでr=4𝑟4r=4でパフォーマンスがピークに達し、GPT-2 MediumはGPT-3 175Bと比較して適応のための類似の内在的ランクを持つことを示唆しています。いくつかのハイパーパラメータはr=4𝑟4r=4で調整されており、これは別のベースラインのパラメータ数と一致するため、他のr𝑟rの選択肢に対して最適ではない可能性があります。
See 図8 for the normalized subspace similarity between W𝑊W and ΔWΔ𝑊\Delta W with varying r𝑟r.
再度注意してください、ΔWΔ𝑊\Delta WはW𝑊Wの上位特異方向を含んでいません。なぜなら、ΔWΔ𝑊\Delta Wの上位4方向とW𝑊Wの上位10%の方向との類似性はほとんど0.2を超えないからです。これは、ΔWΔ𝑊\Delta WがW𝑊Wでは強調されていない「タスク特有」の方向を含んでいることを示す証拠です。
次に答えるべき興味深い質問は、「タスク特有の指示をどれだけ“強く”増幅する必要があるのか」、モデルの適応がうまく機能するためには?
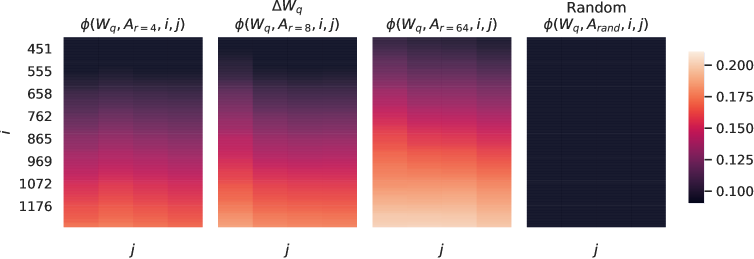
図8: W_{q}の特異方向とΔW_{q}の特異方向との間の正規化された部分空間類似性、r𝑟rが変化し、ランダムなベースラインとともに。ΔW_{q}はW_{W}で強調されていないが重要な方向を増幅します。r𝑟rが大きいΔWは、すでにW_{W}で強調されている方向をより多く選択する傾向があります。
自然に 特徴増幅係数 を 比 ‖ΔW‖F‖U⊤WV⊤‖FsubscriptnormΔ𝑊𝐹subscriptnormsuperscript𝑈top𝑊superscript𝑉top𝐹\frac{|\Delta W| _{F}}{|U^{\top}WV^{\top}| _{F}} と考えることができ、ここで U𝑈U と V𝑉V は ΔWΔ𝑊\Delta W の SVD 分解の左および右の特異行列です。(UU⊤WV⊤V𝑈superscript𝑈top𝑊superscript𝑉top𝑉UU^{\top}WV^{\top}V は W𝑊W の ΔWΔ𝑊\Delta W によって張られる部分空間への「射影」を与えます。)
直感的に言うと、ΔWΔ𝑊\Delta Wが主にタスク特有の方向を含む場合、この量はそれらがΔWΔ𝑊\Delta Wによってどれだけ増幅されるかを測定します。 セクション 7.3に示されているように、r=4𝑟4r=4の場合、この増幅係数は最大で20です。言い換えれば、各層には(一般的に言って)4つの特徴方向があり(事前学習モデルW𝑊Wの全特徴空間の中から)、ダウンストリーム特定タスクのために報告された精度を達成するために、非常に大きな係数20で増幅される必要があります。そして、異なるダウンストリームタスクごとに増幅される特徴方向のセットは非常に異なることが期待されます。
しかし、r=64のとき、この増幅係数は約2に過ぎず、これはΔWで学習された方向の_ほとんど_があまり増幅されていないことを意味します。これは驚くべきことではなく、実際には「タスク特有の方向」を表現するために_必要な_内在的ランクが低いことを再び示す証拠となります。それに対して、ΔWのランク4バージョン(r=4に対応する)における方向は、はるかに大きな係数20で増幅されます。
Generated on Thu Mar 7 00:23:07 2024 by LaTeXML