この記事は主に、書籍「Operating Systems: Three Easy Pieces」の第 40 章から「編集」されています。これは非常に本書です。は理解しやすく、オペレーティング システムについて混乱しているすべての学生にお勧めします。 このファイル システムは、データ構造 と 読み取りおよび書き込みプロセス を主要な行として、非常に小さなハード ディスク領域に基づいています。各基本リンクを 0 から 1 まで推定し、迅速に確立するのに役立ちます。ファイルシステムの理解、直感。
ファイルシステムは基本的にはブロックストレージ上に構築されています。しかしもちろん、現在の一部の分散ファイルシステム、例えば JuiceFS は、基盤としてオブジェクトストレージを使用しています。しかし、ブロックストレージであれオブジェクトストレージであれ、その本質は「データブロック」によるアドレッシングとデータ交換にあります。
まず、ハードディスク上のデータ構造、つまりレイアウトについて完全なファイルシステムを探究します。その後、開閉や読み書きのプロセスを通じて各サブモジュールを連結し、ファイルシステムの要点を網羅することになります。
著者:木鳥雑記 https://www.qtmuniao.com/2024/02/28/mini-filesystem 転載時は出典を明記してください
この記事は、ストレージ、データベース、分散システム、AI インフラ、コンピューターの基礎に焦点を当てた、大規模データ システムのコラム「[システムの日常知識] (https://xiaobot.net/p/system- Thinking)」からのものです。 購読とサポートを歓迎して、より多くの記事のロックを解除してください。 あなたのサポートは私が前進するための最大の動機です。

仮定すると、私たちのブロックサイズは4KBで、非常に小さいハードディスクがあり、ブロックが64個だけ(したがって総サイズは64 * 4KB = 256KB)で、そのハードディスクはファイルシステム専用です。ハードディスクはブロック単位でアドレス指定されるため、アドレス空間は0〜63です。
このミニディスクに基づいて、私たちは一緒にこの極小ファイルシステムを段階的に導き出していきましょう。
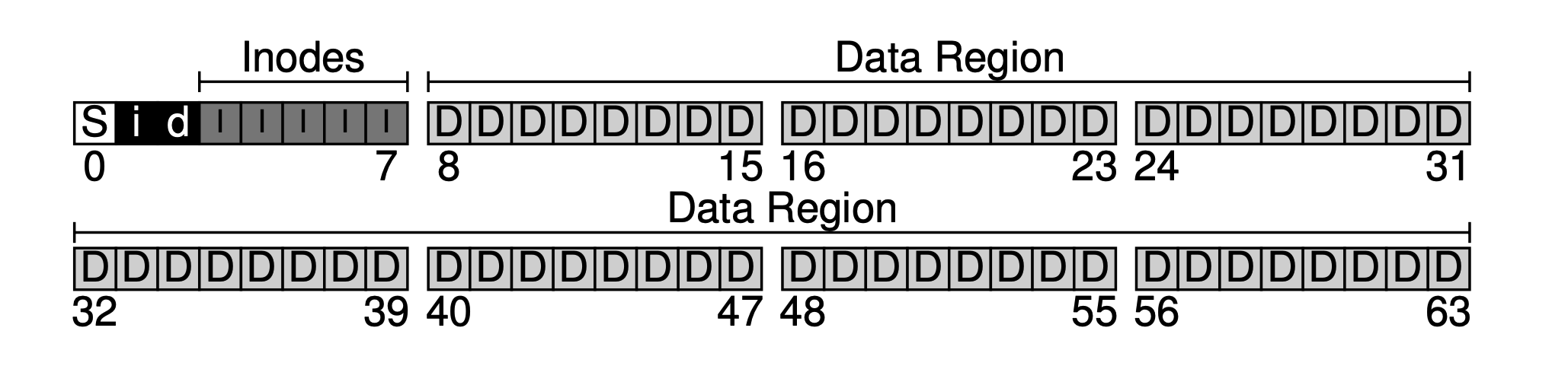
ファイルシステムの主要な目的はユーザーデータの保存にあることは間違いありません。そのため、ディスクにデータ領域(Data Region)として一部を確保します。ここでは、後ろの56ブロックをデータ領域として使用すると仮定します。なぜ56ブロックなのでしょうか?後でわかるように、実際には計算できるのです —— メタデータと実際のデータの比率を大まかに算出し、それに基づいて両方のサイズを決定することができます。
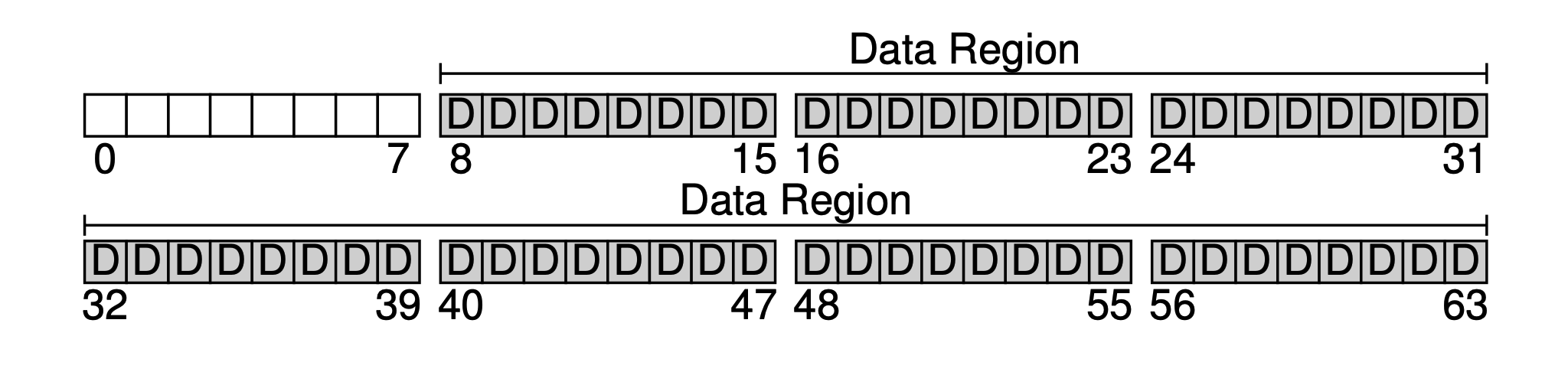
次に、システム内の各ファイルにいくつかのメタデータを保存する必要があります。例えば:
- ファイル名
- ファイルサイズ
- ファイルの所有者
- アクセス権限
- 作成、変更時間
等々。これらのメタデータを保存するデータブロックを、通常 inode (インデックスノード)と呼びます。以下のように、inodeに5つのブロックを割り当てます。
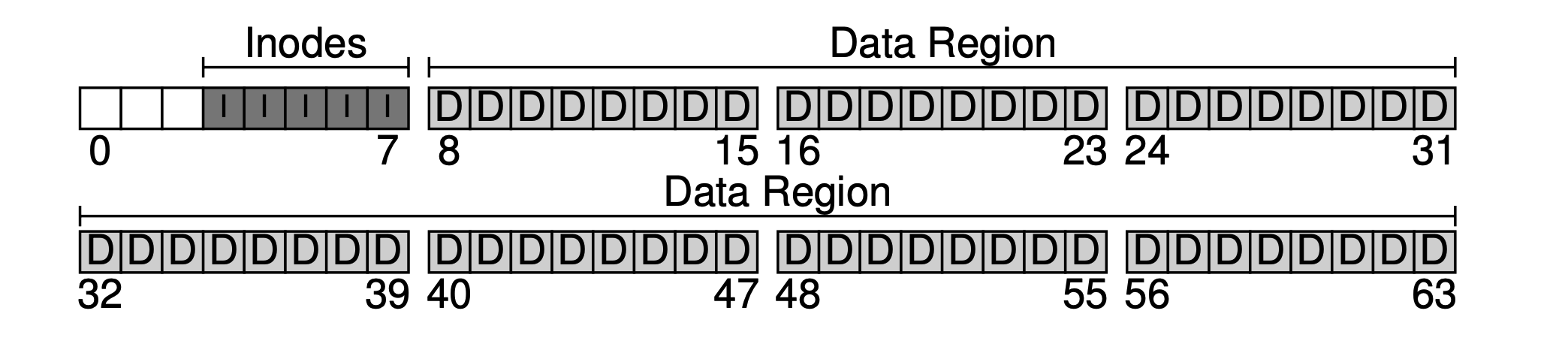
メタデータが占めるスペースは比較的小さいです。例えば128Bや256Bです。ここでは、各inodeが256Bを占めると仮定します。すると、各4KBブロックは16個のinodeを収容できます。したがって、私たちのファイルシステムは最大で5 * 16 = 80個のinodeをサポートできます。つまり、私たちのミニファイルシステムは最大で80個のファイルをサポートできますが、ディレクトリもinodeを占めるため、実際に使用できるファイル数は80より少なくなります。
現在、データ領域とファイルメタデータ領域を持っていますが、正常に使用されるファイルシステムでは、どのデータブロックが使用されていて、どれがまだ使用されていないかを追跡する必要があります。このようなデータ構造を割り当て構造(allocation structures)と呼びます。業界で一般的に使用される方法には空きリスト(free list)があり、すべての空きブロックをリストの形でつなげます。しかし、簡単のために、ここではもっとシンプルなデータ構造を使用します:ビットマップ(bitmap)、データ領域には一つ、データビットマップ(data bitmap)と呼ばれます;inode表には一つ、inodeビットマップ(inode bitmap)と呼ばれます。
ビットマップの考え方は非常にシンプルで、各inodeまたはデータブロックに1ビットのデータを使用して、空きかどうかをマークします:0は空きを示し、1はデータがあることを示します。4KBのビットマップは最大で32Kのオブジェクトを追跡できます。便宜上、inode表とデータプールにそれぞれ完全なブロックを割り当てます(全てを使用するわけではありませんが)、そうすることで以下の図が得られます。
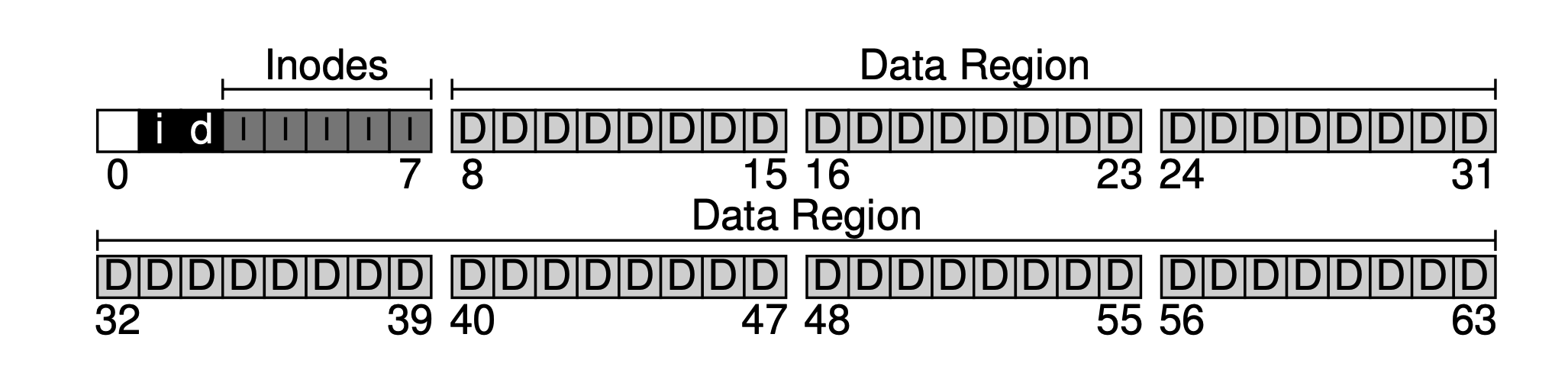
可以看出,私たちの基本的な考え方は、後ろから前に向かってデータレイアウトを行い、最後にはブロックが一つ残ります。このブロックは意図的に残されており、ファイルシステムの超級ブロック(superblock)として機能します。超級ブロックはファイルシステムの入口として機能し、通常、ファイルシステムレベルのメタデータ(例えば、このファイルシステムにはいくつのinodeとデータブロックがあるか(80と56)、inodeテーブルの開始ブロックのオフセット(3)など)を保存します。
したがって、ファイルシステムがマウントされるとき、オペレーティングシステムは最初にスーパーブロック(だから最前面に置かれる)を読み取り、これに基づいて一連のパラメータを初期化し、それをデータボリュームとしてファイルシステムツリーにマウントします。これらの基本情報があれば、そのボリューム内のファイルにアクセスされたとき、その位置を段階的に特定できるようになり、これが私たちが後で説明する読み書きプロセスです。
しかし、読み書きのプロセスについて話す前に、いくつかの重要なデータ構造を拡大して、その内部のレイアウトを見てみる必要があります。
inode は索引ノード(index node)の略称で、ファイルやフォルダーの索引ノードです。簡単にするために、配列を使って索引ノードを組織します。各 inode は一つの番号(inumber)、つまり配列内のインデックス(オフセット)に関連付けられます。
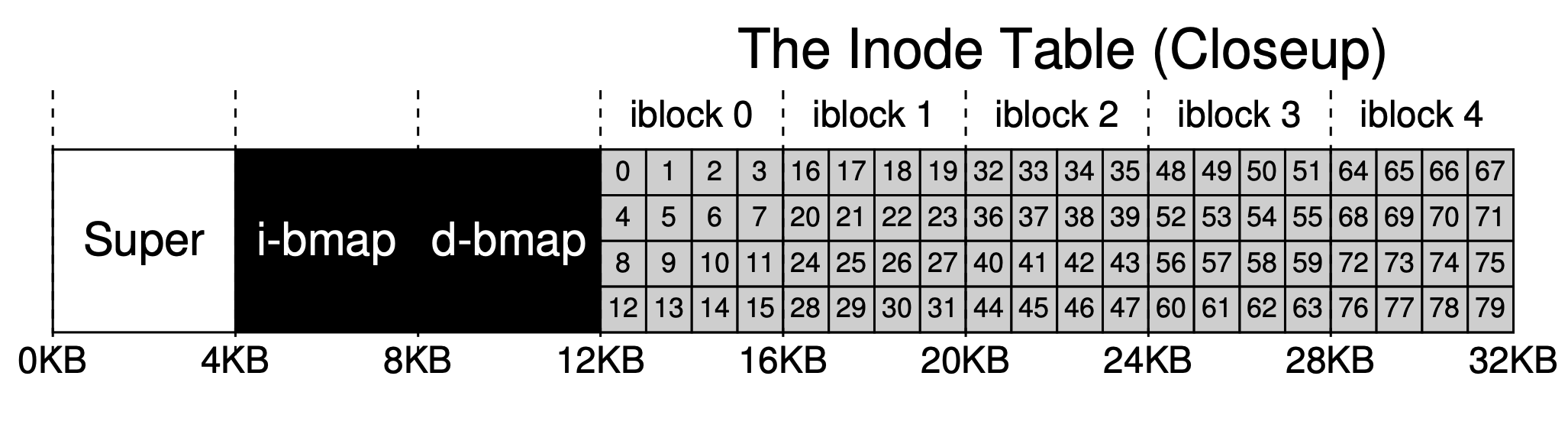
前述したように、各 i ノードは 256B を占有します。 inumber が与えられると、ハードディスク内のそのオフセット (12KB + inumber * 256) を計算できますが、内部メモリと外部メモリの交換はブロック単位で実行されるため、それが配置されているディスクをさらに計算できます。
inode は主にファイル名、いくつかのメタデータ(アクセス権限、様々なイベント、いくつかのフラグ)とデータブロックのインデックスを保存します。データブロックのインデックスは実際にはメタデータの一部ですが、非常に重要であるため別途言及されます。
私たちは比較的シンプルなインデックス方式を使用しています:間接ポインタ(indirect pointer)。つまり、inodeに保存されているのはデータブロックを直接指すポインタではなく、ポインタブロック(データ領域に割り当てられているが、二次ポインタが保存されている)を指すものです。ファイルが十分に大きい場合、三次ポインタを引き出すこともあります(私たちのこの小さなシステムでそれが必要かどうかは、皆さんが推測することができます)。
しかし、私たちの統計によると、ほとんどのファイルシステムでは、小さいファイルが多数を占めています。どれほど小さいかというと?一つのデータブロックで保存できるほどです。

そのため、実践では、inode内で直接ポインタと間接ポインタの混合方式を使用して表現します。私たちのファイルシステムでは、12個の直接ポインタと1個の間接ポインタを使用しています。したがって、ファイルサイズが12個のデータブロックを超えない限り、直接ポインタを直接使用できます。ファイルサイズが大きすぎる場合のみ、間接ポインタを使用し、データエリアに新たにデータブロックを割り当てて、間接ポインタを格納します。
私たちのデータ領域は非常に小さく、56個のブロックしかありません。4バイトでインデックスを使用すると仮定すると、二次ポインタは最大で(12 + 1024)・4K、つまり4144KBサイズのファイルをサポートできます。
別の実践でよく使われる方法はデータセグメント(extents)です。つまり、各連続データ領域を開始ポインタとサイズで表し、ファイルのすべてのデータセグメントを連結します。しかし、複数のデータセグメントがある場合、最後のデータセグメントにアクセスしたり、ランダムアクセスを行うと、パフォーマンスが非常に悪くなります(次のデータセグメントへのポインタは前のデータセグメントに保存されています)。アクセス速度を最適化するために、データセグメントのインデックスリストをメモリ内に保持することが一般的です。Windowsの初期のファイルシステムFATは、この方法を採用していました。
私たちのファイルシステムでは、ディレクトリの構成は非常にシンプルです —— つまり、ファイルと同様に、各ディレクトリも1つのinodeを占有しますが、inodeが指すデータブロックにはファイルの内容ではなく、そのディレクトリに含まれるすべてのファイルとフォルダの情報が保存されています。これは通常、List<entry name, inode number>で表されます。もちろん、実際のエンコーディングに変換するには、ファイル名の長さなどの情報も保存する必要があります(ファイル名は可変長です)。
簡単な例を見てみましょう。フォルダー dir(inode 番号は 5)があり、その中に3つのファイル(foor、bar、foobar)があり、それぞれの inode 番号は 12、13、24 です。すると、そのフォルダのデータブロックに保存されている情報は以下の通りです。

その中で reclen(レコード長)はファイル名が占める空間の大きさで、strlen は実際の長さです。点と点点は、このフォルダと上位フォルダへの2つのポインタを指します。reclen の記録は少し余計に見えるかもしれませんが、ファイル削除の問題を考慮する必要があります(例えば 0 のような特別な inum を使って削除をマークできます)。フォルダ内のファイルやディレクトリが削除されると、ストレージには空洞が発生します。reclen の存在は、削除によって残された空洞を後で追加されるファイルが再利用できるようにします。
説明が必要なのは、ディレクトリ内のファイルを線形に整理することが最も簡単な方法であるということです。実際には、他にも方法があります。例えばXFSでは、ディレクトリ内のファイルやサブフォルダが特に多い場合、B+木を使用して整理されます。これにより、挿入時に同名のファイルが存在するかどうかを迅速に知ることができます。
新しいファイルやディレクトリ項目を作成する必要がある場合、ファイルシステムから利用可能なスペースを取得する必要があります。したがって、空きスペースを効率的に管理する方法は非常に重要な問題です。私たちは2つのビットマップを使用して管理しており、その利点はシンプルさにありますが、欠点は空きビットを探すために毎回線形スキャンを行わなければならず、また、ブロック粒度でしか対応できず、ブロック内に余剰スペースがあっても対応できません。
ディスク上のデータ構造を理解した後、読み書きのプロセスを通じて異なるデータ構造を連結してみましょう。ファイルシステムが既にマウントされていると仮定します:つまり、スーパーブロック(superblock)は既にメモリ内にあります。
私たちの操作はとてもシンプルで、ファイル(例:/foo/bar)を開いて読み取り、その後閉じることです。簡単にするために、ファイルサイズが1ブロック、つまり4kであると仮定します。
システムコール open("/foo/bar", O RDONLY) を発行するとき、ファイルシステムはまずファイル bar の inode を見つける必要があり、そのメタデータとデータの位置情報を取得します。しかし、現在私たちが持っているのはファイルパスだけです。それではどうすればいいのでしょうか?
答えは:ルートディレクトリから下にトラバースする。ルートディレクトリのinode番号は、スーパーブロックに保存するか、またはハードコードする(例えば2、ほとんどのUnixファイルシステムは2から始まる)。つまり、事前に知っていなければならない(well known)。
そのため、ファイルシステムはそのルートディレクトリのinodeをハードディスクからメモリに読み込み、さらにinode内のポインタを通じてその指し示すデータブロックを見つけ、そこから全てのサブディレクトリとフォルダの中からfooフォルダとその対応するinodeを見つけ出します。このプロセスを再帰的に繰り返し、openシステムコールの最終ステップでは、barのinodeをメモリに読み込み、権限チェック(プロセスのユーザ権限とinodeのアクセス権限制御を比較)を行い、ファイルディスクリプタを割り当ててプロセスのオープンファイルテーブルに置き、それをユーザーに返します。
一旦ファイルが開かれた後、read() のシステムコールを発行して、実際にデータを読み取ることができます。読み取り時には、まずファイルの inode 情報に基づいて最初のブロックを見つけます(lseek() を使用してオフセットを変更していない限り)。その後、読み取りを行います。同時に、inode のメタデータ(例えばアクセス時間)を変更することがあります。その後、プロセス内のそのファイルディスクリプタのオフセットを更新し、さらに読み進め、ある時点で close() を呼び出してそのファイルディスクリプタを閉じます。
プロセスがファイルを閉じるとき、必要な作業はずっと少なく、ファイルディスクリプタを解放するだけで済み、実際のディスクIOは発生しません。
最後、このファイル読み込みプロセスをもう一度整理しましょう。ルートディレクトリのinode番号から始めて、inodeと対応するデータブロックを交互に読み取り、最終的に検索対象のファイルを見つけます。その後、データの読み取りを行い、inodeのアクセス時間などのメタデータを更新して書き戻します。下の表はこのプロセスを簡単にまとめたもので、読み取りパスが全体を通して割り当て構造(data bitmapおよびinode bitmap)に関わることはないことがわかります。
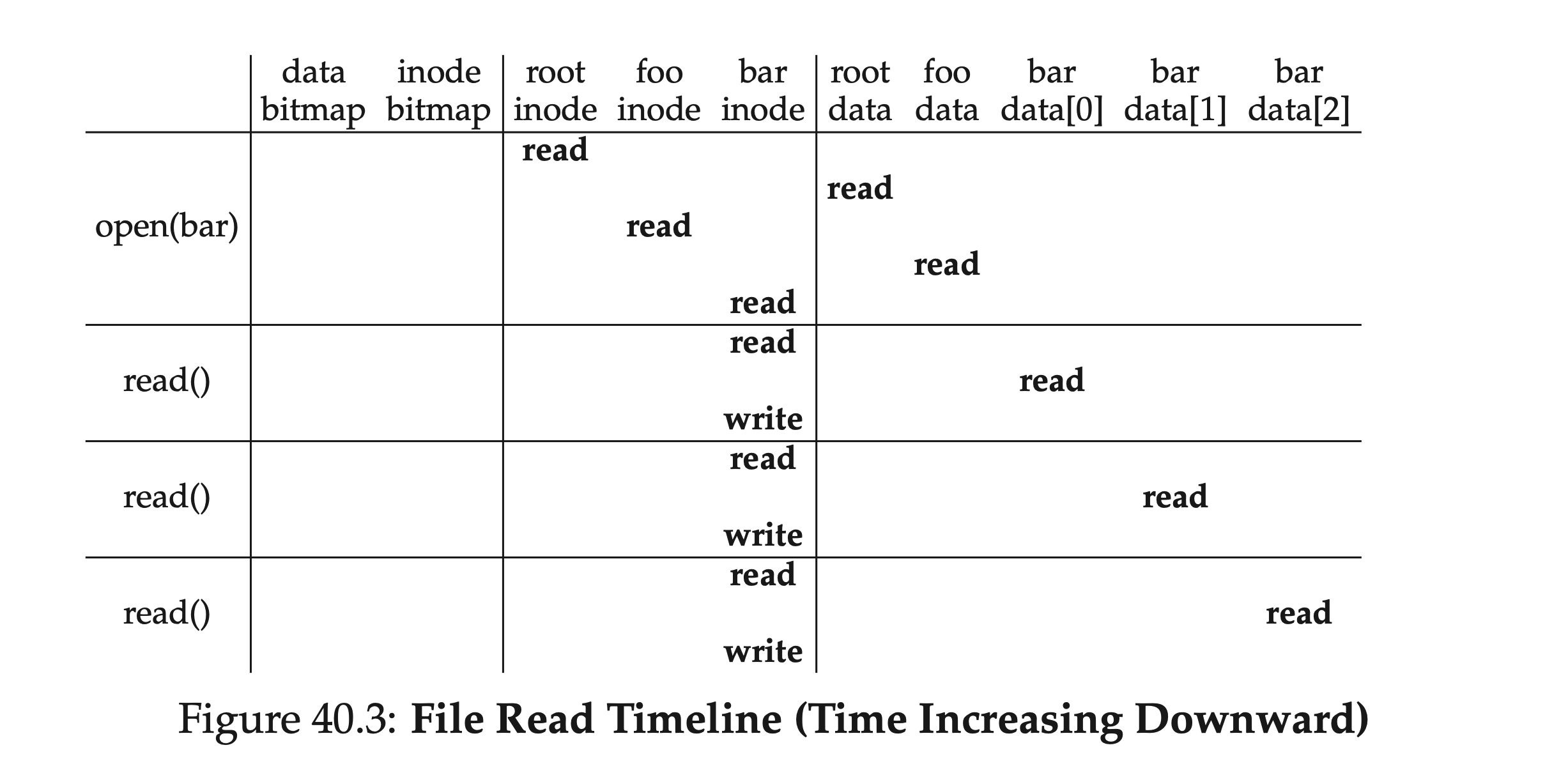
深さの面から言えば、探索するパスのレベルが非常に多い場合、このプロセスは線形に増加します;幅の面から言えば、途中で検索する際に関わるフォルダが含むディレクトリ項目が特に多く、つまりファイルツリーが「非常に広い」場合、ディレクトリ内で検索を行う際に、複数のデータブロックを読み取る必要があるかもしれません。
ファイルを書き込むプロセスと読み取るプロセスは非常に似ており、ファイルを開く(ルートディレクトリから対応するファイルを見つける)ことから始まります。その後、書き込みを開始し、最後に閉じます。しかし、ファイルを読み取るのとは異なり、書き込みには新しいデータブロックを割り当てる必要があり、これには以前のビットマップが関係してきます。通常、書き込みには少なくとも5回のIOが必要です。
- data bitmapを読み取る(空きブロックを見つけ、メモリ内で使用中とマークするため)
- data bitmapを書き戻す(他のプロセスに見えるようにするため)
- inodeを読み取る(新しいデータ位置のポインタを追加するため)
- inodeを書き戻す
- 見つかった空きブロックにデータを書き込む
これは既に存在するファイルへの書き込みに過ぎません。まだ存在しないファイルを作成して書き込む場合、そのプロセスはさらに複雑になります:inodeを作成する必要があり、これにより一連の新しいIOが導入されます:
- inode bitmap の最初の読み取り(空き inode の検索)
- inode bitmap への最初の書き戻し(ある inode が使用中であるとマークする)
- inode 自体への最初の書き込み(初期化)
- 親フォルダの対応するディレクトリエントリデータブロックの読み書き(新しく作成されたファイルと inode の追加)
- 親フォルダの inode の読み書き(変更日の更新)
もし親フォルダのデータブロックが足りなければ、新たに空間を割り当てる必要があり、それにはdata bitmapとdata blockを再度読み込む必要があります。下図は/foo/barファイルを作成する際のタイムラインで発生するIOに関連しています。
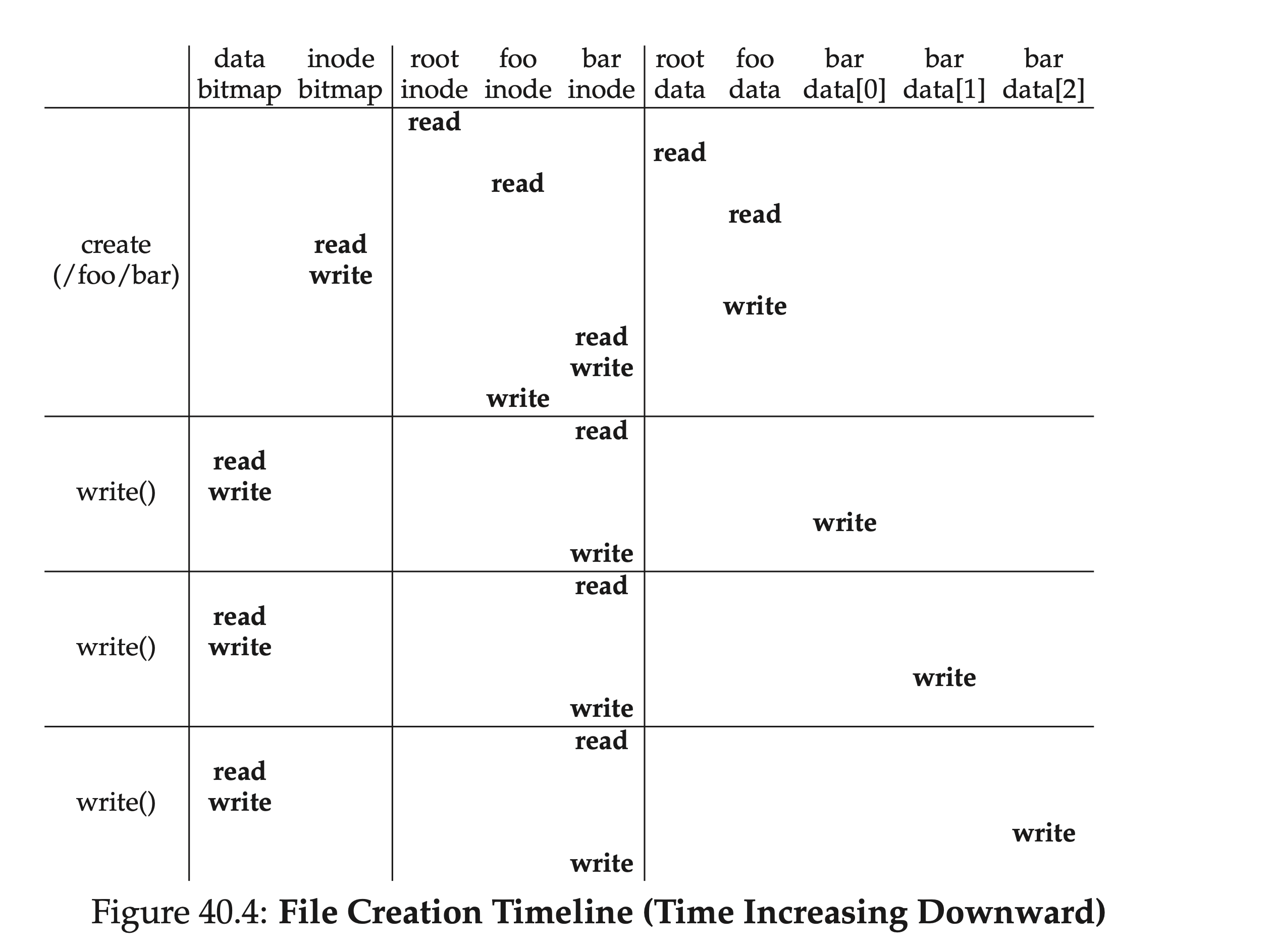
上記の読み書きプロセスの分析からわかるように、このように単純な読み書き操作でさえ、大量のIOを伴うことになり、これは実際には受け入れがたい。この問題を解決するために、ほとんどの産業用ファイルシステムでは、メモリを十分に活用し、重要な(つまり頻繁にアクセスされる)データブロックをメモリ内にキャッシュする;同時に、頻繁なディスク書き込みを避けるために、変更を先にメモリバッファに適用し、その後、一定量が溜まったらディスクに書き込む。
早期のファイルシステムは固定サイズキャッシュ(fixed-size cache)を導入しており、満杯になるとLRUなどの置換アルゴリズムを利用してページを追い出します。その欠点は、キャッシュが満杯でない時に空間を無駄にし、満杯になると頻繁にページを交換する可能性があることです。このスタイルを静的分割(static partitioning)と呼びます。現代のほとんどのファイルシステムは、動的分割(dynamic partitioning)技術を使用しています。例えば、仮想メモリページとファイルシステムページを一つのプールに置き、統一ページキャッシュ(unified page cache)と呼び、これにより両者の割り当てがより柔軟になります。キャッシュに乗った後、同じディレクトリ内の複数のファイルを読み取る場合、後続の読み取りで多くのIOを省くことができます。
書き込みプロセスは、前半部でパスに従ってデータブロックを検索する際に読み取りが関与するため、キャッシュからも恩恵を受けます。しかし、書き込みの部分については、書き込みバッファリングを通じてディスクへの書き込みを遅らせることができます。ディスクへの書き込みを遅らせることには多くの利点があります。例えば、bitmapを複数回変更しても、一度だけ書き込めば済む可能性があります;一連の変更を蓄積することで、IO帯域の利用率を向上させることができます;もしファイルが先に増えてから削除される場合、ディスクへの書き込みを完全に省略できるかもしれません。
しかし、これらの性能向上には代償が伴います —— 予期せぬダウンがデータ損失を引き起こす可能性があります。そのため、現代のファイルシステムのほとんどが読み書きのバッファリングを有効にしているにもかかわらず、direct I/O の方式を通じて、ユーザーがキャッシュをバイパスして直接ディスクに書き込むことを許可しています。データ損失に敏感なアプリケーションは、対応するシステムコール fsync() を利用して即時にディスクにフラッシュすることができます。
ここに至って、私たちは極めてシンプルなファイルシステムの実装を完成させました。「小さなスズメでも、五臓がそろっている」ことから、ファイルシステム設計のいくつかの基本的な理念を見ることができます:
- inodeを使用してファイル粒度のメタデータを保存し、データブロックを使用して実際のファイルデータを保存します
- ディレクトリは特殊なファイルの一種で、ファイルの内容ではなく、フォルダのサブディレクトリエントリを保存します
- inodeとデータブロック以外にも、空きブロックを追跡するためのbitmapなど、いくつかの他のデータ構造が必要です
この基本的なファイルシステムから出発して、実際には取捨選択や最適化できる点が特に多いことがわかります。興味があれば、皆さんはこの記事を基に、産業用のファイルシステムの設計を見てみることができます。