文献では、なぜChatGPTが私たちの想像力を多く捉えることができるのかについて議論されており、私はしばしば2つの物語に出会います。
- スケール:より多くのデータと計算を投入する。 2. UX:プロンプトインターフェースからより自然なチャットインターフェースに移行する。
一つの話は、ChatGPTなどのモデルを作る際に投入された信じられないほどの技術的創造性がしばしば軽視されることです。RLHF(Reinforcement Learning from Human Feedback)というクールなアイデアの一つは、強化学習と人間のフィードバックを自然言語処理に取り入れることです。
RLは取り扱いが非常に難しく、そのため、主にゲームやAtariやMuJoCoのようなシミュレーション環境に限定されていました。たった5年前、RLとNLPはほぼ直交して進化していました - 異なるスタック、異なる技術、異なる実験セットアップ。新しい領域で大規模に機能するのを見るのは印象的です。
だから、RLHFは具体的にどのように機能するのでしょうか?なぜ機能するのでしょうか?この投稿では、それらの質問に対する回答について議論します。
目次
RLHF概要
フェーズ1. 完了のための事前トレーニング
…. 言語モデル
…. 数学的定式化
…. 事前トレーニングのデータボトルネック
フェーズ2. 対話のための教師付きファインチューニング(SFT)
…. なぜSFT
…. デモデータ
…. 数学的定式化
フェーズ3. RLHF
…. 3.1. 報酬モデル(RM)
…….. 数学的定式化
…….. 比較データを収集するためのUI
…. 3.2. 報酬モデルを使用したファインチューニング
…….. 数学的定式化
…. RLHFと幻覚
結論
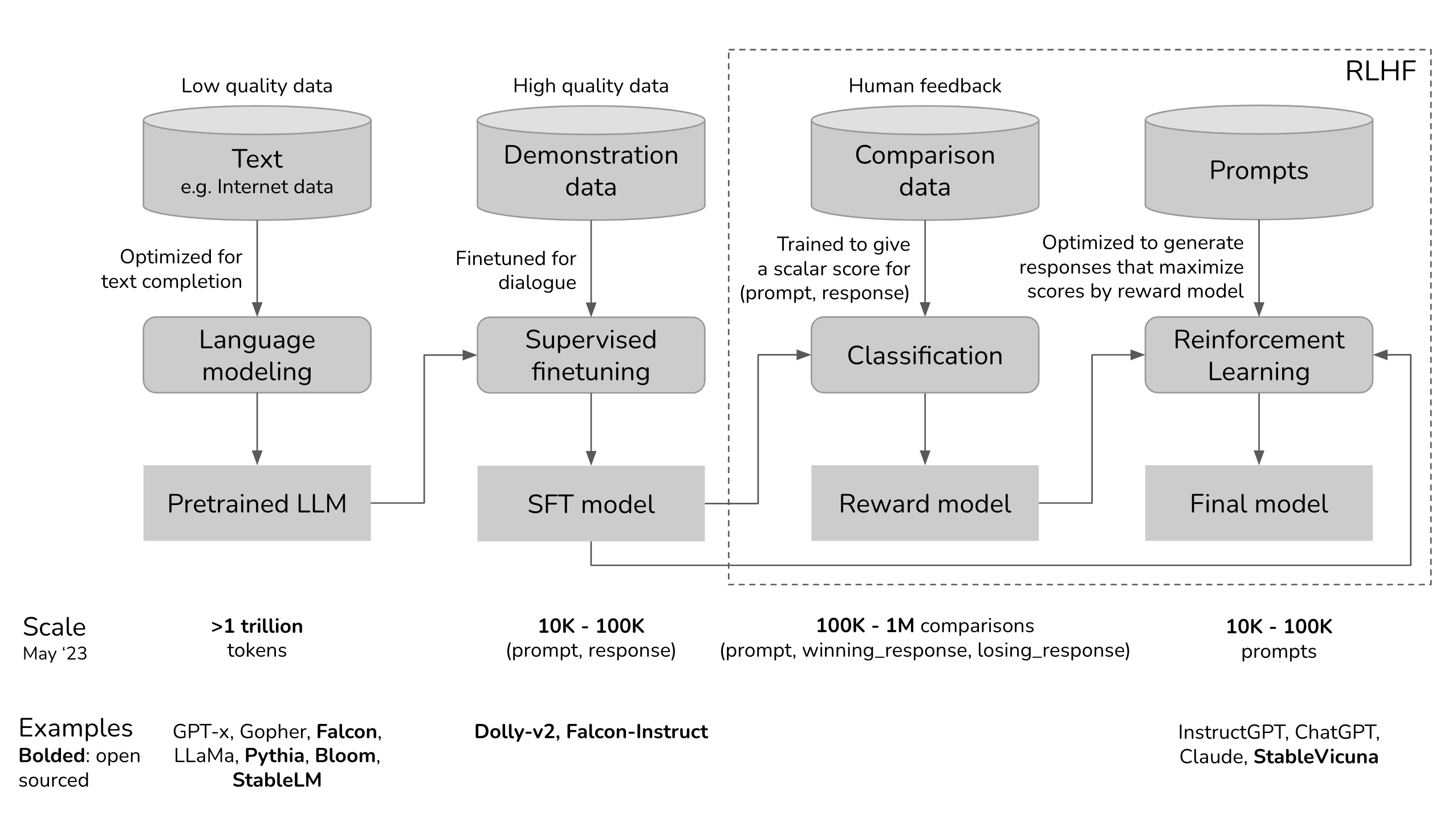
RLHFを理解するには、まずChatGPTのようなモデルを訓練するプロセスを理解する必要があります。そして、RLHFがどこに位置するかを理解する必要があります。これはこの投稿の最初のセクションの焦点です。次の3つのセクションでは、ChatGPT開発の3つのフェーズについて説明します。各フェーズについて、そのフェーズの目標、なぜそのフェーズが必要なのかの直感、そしてより技術的な詳細を見たい人のための対応する数学的な定式化について議論します。
現在、RLHFはOpenAI、DeepMind、およびAnthropicなどの一部の主要な企業を除いて、業界で広く使用されていません。しかし、RLHFを使用した多くの進行中の取り組みを見てきたので、将来RLHFがさらに広く使用されることに驚かないでしょう。
この投稿では、読者がNLPやRLの専門知識を持っていないことを前提としています。もし持っている場合は、関連性の低いセクションをスキップしていただいて構いません。
RLHF概要
ChatGPTの開発プロセスを可視化して、RLHFがどこに適合するかを見てみましょう。
もし目を細めると、この上の図は、スマイリーフェイスをしたミームのショゴスと非常に似て見えます。
- 事前学習済みモデルは、インターネットから収集された無差別なデータで訓練されたため、手のつけられない怪物です:クリックベイト、デマ、プロパガンダ、陰謀論、ある特定の人口層への攻撃などを考えてください。 2. この怪物は、その後、より質の高いデータ(StackOverflow、Quora、または人間の注釈など)で微調整されました。これにより、ある程度社会的に受け入れられるものとなりました。 3. 次に、微調整されたモデルは、それを顧客向けに適したものにするためにRLHFを使用してさらに磨かれました。たとえば、それに笑顔を与えることなどです。
Shoggoth with Smiley Face. Courtesy of twitter.com/anthrupad
3つのフェーズのうちいずれかをスキップすることができます。たとえば、SFTフェーズを経ずに事前学習モデルの上で直接RLHFを行うことができます。ただし、経験的には、これらの3つのステップをすべて組み合わせることが最良のパフォーマンスを提供します。
Pretraining is the most resource-intensive phase. For the InstructGPT model, pretraining takes up 98% of the overall compute and data resources. You can think of SFT and RLHF as unlocking the capabilities that the pretrained model already has but are hard for users to access via prompting alone.
人間の好みから学習する機械を教えることは新しいものではありません。10年以上前から存在しています。OpenAIは、主要な取り組みがロボティクスであった時期に人間の好みから学習を探求し始めました。当時の説は、AIの安全性にとって人間の好みが重要であるというものでした。しかし、結果的には、人間の好みはより良い製品にもなり得ることがわかり、それによりより多くの観客を引きつけるようになりました。
»»OpenAIの2017年の人間の選好からの学習に関する論文の要約です««
安全なAIシステムを構築するための一歩は、人間が目標関数を書く必要をなくすことです。なぜなら、複雑な目標のための単純な代理物を使用するか、複雑な目標を少し誤解することが、望ましくない、場合によっては危険な振る舞いを引き起こす可能性があるからです。DeepMindの安全チームと協力して、私たちは、提案された2つの振る舞いのうちどちらがより良いかを教えられることで、人間が何を望んでいるかを推測できるアルゴリズムを開発しました。
Phase 1. 完了のための事前トレーニング
事前学習フェーズの結果は、大規模言語モデル(LLM)であり、事前学習モデルとしてよく知られています。例には、GPT-x(OpenAI)、Gopher(DeepMind)、LLaMa(Meta)、StableLM(Stability AI)などがあります。
言語モデル
言語モデルは言語に関する統計情報をエンコードします。簡単に言うと、統計情報は、あるコンテキストで何か(例:単語、文字)が現れる可能性がどれくらいあるかを教えてくれます。トークンという用語は、言語モデルによって、単語、文字、または単語の一部(例:-tion)を指すことがあります。トークンは、言語モデルが使用する語彙と考えることができます。
言語を流暢に話す人は、その言語について無意識に統計的な知識を持っています。たとえば、文脈が「私の好きな色は__です」という場合、英語を話す人は、空欄に入る単語が緑よりも車の方がはるかに可能性が低いことを知っています。
同様に、言語モデルもその空欄を埋めることができるべきです。言語モデルは「補完機」と考えることができます:与えられたテキスト(プロンプト)に対して、そのテキストを完成させるための応答を生成することができます。以下に例を示します:
- プロンプト(ユーザーから):
私は一生懸命やってみたけど、結局は - 完了(言語モデルから):
何もかも意味をなさない。

単純なように聞こえるかもしれませんが、完了は非常に強力であり、多くのタスクを完了タスクとしてフレーム化できます:翻訳、要約、コードの記述、数学の問題解決など。たとえば、プロンプト「フランス語でのHow are youは...」を与えると、言語モデルは「Comment ça va」と完了させ、実質的に言語間の翻訳を行うことができるかもしれません。
言語モデルを完成させるためには、多くのテキストを与えて統計情報を抽出できるようにします。モデルに学習させるためのテキストはトレーニングデータと呼ばれます。0と1の2つのトークンだけを含む言語を考えてみましょう。次のシーケンスをトレーニングデータとして言語モデルに与えると、言語モデルはその情報を抽出するかもしれません:
- もしコンテキストが
01であるなら、次のトークンはおそらく01である可能性が高い - もしコンテキストが
0011であるなら、次のトークンはおそらく0011である可能性が高い
0101
010101
01010101
0011
00110011
001100110011
言語モデルはその訓練データを模倣するため、言語モデルの性能は訓練データの質に左右されるため、「ゴミを入れればゴミが出る」というフレーズがある。Redditのコメントで言語モデルを訓練すると、両親に見せるのは避けた方が良いかもしれない。
数学的定式化
- 機械学習タスク:言語モデリング
- トレーニングデータ:低品質のデータ
- データ規模:2023年5月現在、通常は数兆トークンのオーダーである。
- GPT-3のデータセット(OpenAI):0.5兆トークン。GPT-4の公開情報は見当たらないが、GPT-3よりもデータ量が1桁多いと推定される。
- Gopherのデータセット(DeepMind):1兆トークン
- RedPajama(Together):1.2兆トークン
- LLaMaのデータセット(Meta):1.4兆トークン
- このプロセスから生じるモデル:LLM
- (LLM_\phi): トレーニングされている言語モデル、パラメータは (\phi) で表されます。目標は、クロスエントロピー損失が最小となる (\phi) を見つけることです。
- ([T_1, T_2, ..., T_V]): 語彙 - トレーニングデータ内のすべての一意のトークンの集合。
- (V): 語彙のサイズ。
- (f(x)): トークンを語彙内の位置にマッピングする関数。(x) が語彙内の (T_k) である場合、(f(x) = k)。
- シーケンス ((x_1, x_2, ..., x_n)) が与えられた場合、(n) 個のトレーニングサンプルがあります:
- 入力: (x =(x_1, x_2, ..., x_{i-1}))
- 正解: (x_i)
- 各トレーニングサンプル ((x, x_i)) について:
- (k = f(x_i)) とします
- モデルの出力: (LLM(x)= [\bar{y}_1, \bar{y}_2, ..., \bar{y}_V])。注意: (\sum_j\bar{y}_j = 1)
- 損失値: (CE(x, x_i; \phi) = -\log\bar{y}_k)
- 目標: すべてのトレーニングサンプルで期待される損失を最小化する (\phi) を見つけること。(CE(\phi) = -E_x\log\bar{y}_k)
事前学習のためのデータボトルネック
今日、GPT-4のような言語モデルは非常に多くのデータを使用しており、次の数年でインターネットデータが枯渇する可能性が現実的な懸念となっています。狂ったことのように聞こえますが、それは実際に起こっています。1兆トークンがどれほど大きいかを理解するために:1冊の本には約5万語または6万7000トークンが含まれています。1兆トークンは1,500万冊の本に相当します。
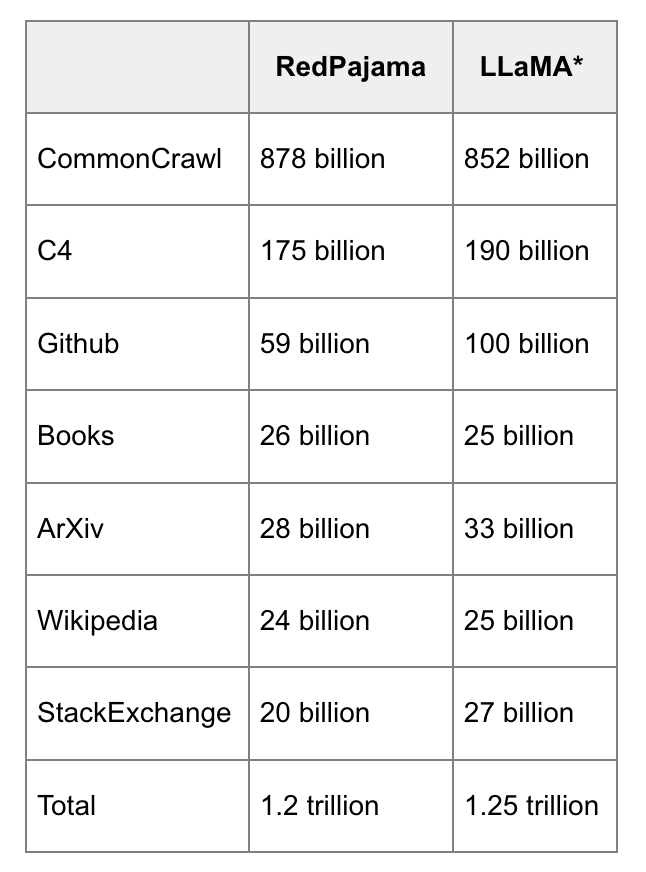
RedPajamaによるRedPajamaとLLaMaデータの並べ替え比較。
訓練データセットのサイズの増加率は、新しいデータが生成される率よりもはるかに速いです(Villalobos et al, 2022)。**インターネット上に何かを投稿したことがある場合、あなたが同意しているかどうかに関わらず、いずれはある言語モデルの訓練データに含まれているか、または含まれる可能性があると仮定すべきです。これは、インターネット上に何かを投稿すると、Googleによってインデックス化されることを期待すべきであるのと似ています。
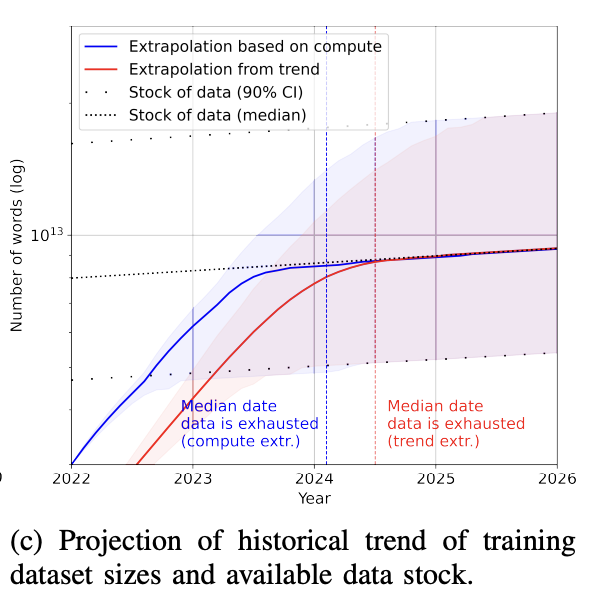
その上、インターネットはChatGPTのような大規模言語モデルによって生成されたデータで急速に溢れています。企業が引き続きインターネットデータを使用して大規模LLMを訓練し続けると、これらの新しいLLMは既存のLLMによって生成されたデータで訓練される可能性があります。
公開されているデータを使い果たしたら、さらにトレーニングデータを増やす最も実現可能な方法は、独自のデータを使用することです。著作権のある書籍、翻訳、動画/ポッドキャストの文字起こし、契約書、医療記録、ゲノム配列、ユーザーデータなどの大量の独自データを手に入れた企業は競争上の優位性を持つと考えられます。ChatGPTの登場を受けて、多くの企業がデータの利用条件を変更し、他社がLLMのためにデータをスクレイピングするのを防ぐようになったことは驚くべきことではありません。詳細はReddit、StackOverflowを参照してください。
Phase 2. 対話のための監督された微調整(SFT)
なぜSFT
事前学習は完成を最適化します。事前学習済みモデルに質問をすると、例えば、ピザの作り方という質問をすると、以下のいずれかが有効な完成となります。
- 質問にさらなる文脈を追加する:
家族全員分の2. 追加の質問をする:? どんな材料が必要ですか?どれくらいの時間がかかりますか?3. 実際に答える
第3のオプションは、回答を探している場合に好ましいです。SFTの目標は、事前学習済みモデルを最適化して、ユーザーが求めている回答を生成することです。
その方法はどうやって行うのか?モデルがトレーニングデータを模倣することはわかっています。SFT中、私たちは言語モデルにさまざまなユースケースのプロンプトに適切に応答する方法の例を示します(例:質問回答、要約、翻訳)。これらの例は(プロンプト、応答)の形式に従い、デモンストレーションデータと呼ばれます。OpenAIは教師付きファインチューニングを「振る舞いクローニング」と呼んでいます:モデルがどのように振る舞うべきかをデモンストレーションし、モデルはこの振る舞いをクローンします。
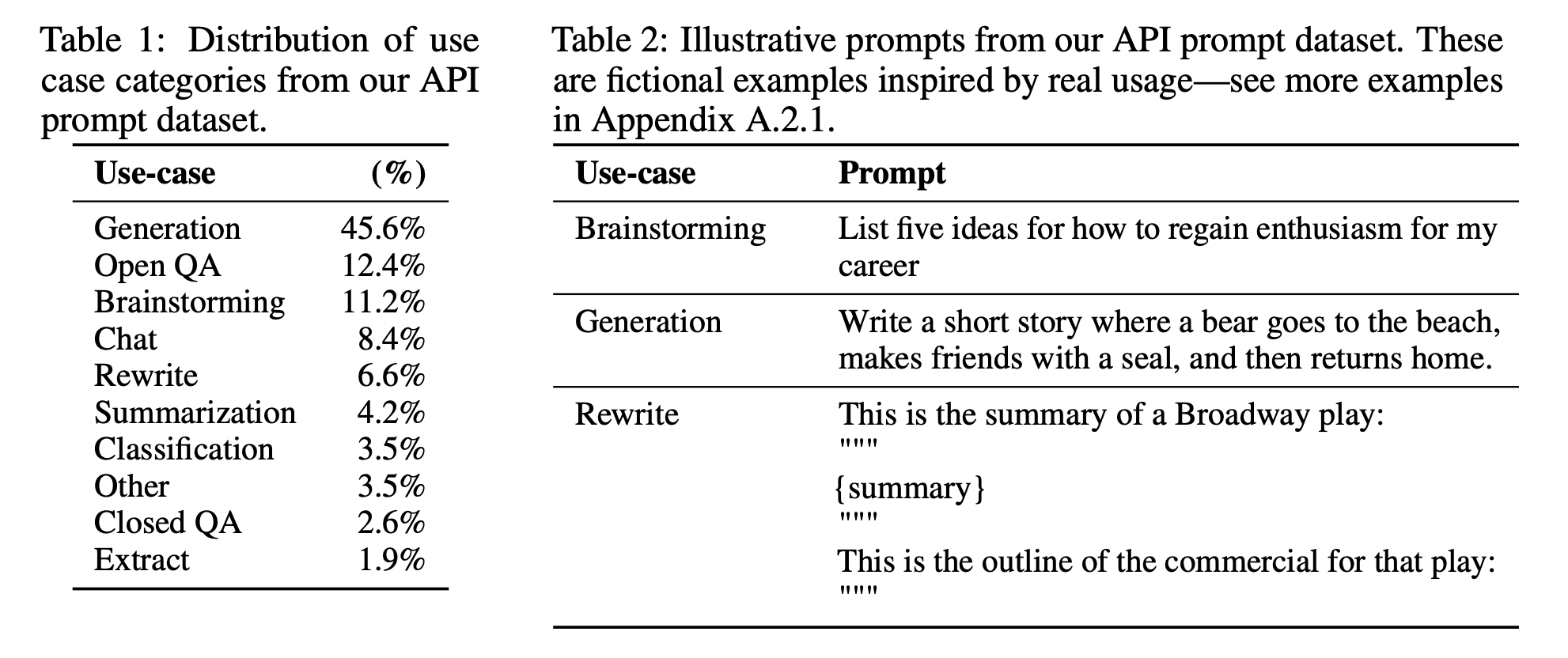
InstructGPTを微調整するために使用されるプロンプトの分布
デモデータを模倣するモデルを訓練するには、事前学習済みモデルを使用してファインチューニングするか、ゼロから訓練することができます。実際、OpenAIは、1.3BパラメータのInstructGPTモデルの出力が175BのGPT-3の出力よりも好ましいことを示しました。しかし、ファインチューニングアプローチの方がはるかに優れた結果を生み出します。
デモデータ
デモデータは、InstructGPTやChatGPTでOpenAIが行ったように、人間によって生成することができます。従来のデータラベリングとは異なり、デモデータはスクリーンテストに合格した高学歴のラベラーによって生成されます。InstructGPTのデモデータをラベル付けした人々のうち、約90%が少なくとも大学の学位を持ち、3分の1以上が修士号を持っています。
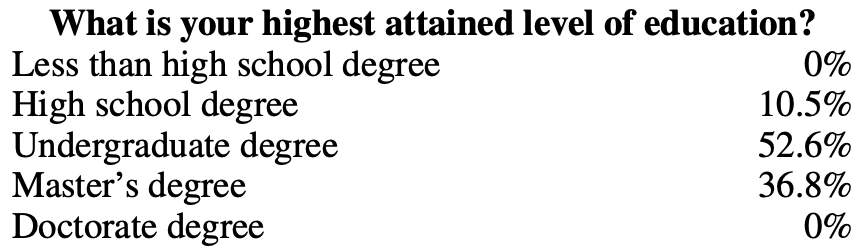
OpenAIの40人のラベラーが、『InstructGPT』のために約13,000の(プロンプト、レスポンス)ペアを作成しました。以下にいくつかの例を示します:
プロンプト
応答
セレンディピティとは、偶然によって幸福や利益をもたらす形での出来事の発生と展開を意味します。その単語を文に使ってください。
マーガレットに出くわし、トムに紹介されたことは幸運な偶然だった。
ELI5: ストレスやがっかりした経験中に胸に「不安の塊」ができる原因は何ですか?
のどの不安の塊は、筋肉の緊張によって、声門を開いたままにして空気の流れを最大化することが原因です。胸が締め付けられる感覚や心の痛みは、迷走神経によって引き起こされ、臓器に血液を速く送り、消化を停止し、アドレナリンとコルチゾールを生成するよう指示します。
このレシピから買い物リストを作成してください: ズッキーニの両端を切り落とします。ズッキーニを縦半分に切り、種をくり抜いて、1/2インチの殻を残します。種を細かく刻みます。スキレットで牛ひき肉、ズッキーニの種、玉ねぎ、きのこ、ピーマンを中火で肉が生焼けでなくなるまで調理します。油をきります。火から外してください。1/2カップのチーズ、ケチャップ、塩、コショウを加えてよく混ぜます。ズッキーニの殻にスプーンで詰めます。グリースを塗った13x9インチのベーキング皿に入れます。残りのチーズを振りかけます。
ズッキーニ、牛肉、玉ねぎ、キノコ、ピーマン、チーズ、ケチャップ、塩、コショウ
OpenAIの手法は高品質なデモデータを生成しますが、費用と時間がかかります。代わりに、DeepMindはヒューリスティックを使用して、モデルGopherのためにインターネットデータからの対話をフィルタリングしました(Rae et al., 2021)。
»» 対話のためのDeepMindのヒューリスティックス ««
具体的には、少なくとも6つの段落からなる連続したセットをすべて見つけます(2つの改行で区切られたテキストブロック)。すべての段落には、セパレータで終わる接頭辞が必要です(例:
Gopher:、Dr Smith -、またはQ.)。偶数番目の段落は互いに同じ接頭辞を持ち、奇数番目の段落も同様ですが、両方の接頭辞は異なる必要があります(つまり、会話は厳密に2人の個人間で行き来する必要があります)。この手順により、高品質な対話が確実に得られます。
»» 対話の微調整と指示の後に続く微調整についての補足:««
OpenAIのInstructGPTは指示に従うように微調整されています。デモデータの各例は(プロンプト、応答)のペアです。DeepMindのGopherは対話を行うように微調整されています。デモの各例は、行ったり来たりする対話の複数のターンです。指示は対話のサブセットです - ChatGPTはInstructGPTの強化バージョンです。
数学的定式化
数学的な定式化は、フェーズ1のものと非常に似ています。
- MLタスク:言語モデリング
- トレーニングデータ:(プロンプト、レスポンス)形式の高品質データ
- データ規模:10,000 - 100,000 (プロンプト、レスポンス) ペア
- InstructGPT:約14,500ペア(ラベラー13,000 + 顧客1,500)
- Alpaca:52K ChatGPTのインストラクション
- Databricks’ Dolly-15k:Databricks社員によって作成された約15,000ペア
- OpenAssistant:10,000の会話で161,000メッセージ -> 約88,000ペア
- Dialogue-finetuned Gopher:約50億トークン、約10Mメッセージの規模と推定される。ただし、これらはインターネットからヒューリスティックを使用してフィルタリングされているため、最高品質ではないことに注意
- モデルの入力と出力
- 入力:プロンプト
- 出力:このプロンプトに対するレスポンス
- トレーニングプロセス中に最小化する損失関数:クロスエントロピー。ただし、損失にはレスポンス内のトークンのみがカウントされる
Phase 3. RLHF
実証的に、RLHFはSFT単独と比較して性能を大幅に向上させます。ただし、私が完全に納得できると思う議論は見たことがありません。Anthropicは次のように説明しています:「人間フィードバック(HF)が他の技術と比較して最も優位性を持つことを期待しています。人々が易しく引き出すことは容易ですが形式化および自動化が難しい複雑な直感を持っている場合。」(Bai et al., 2022)
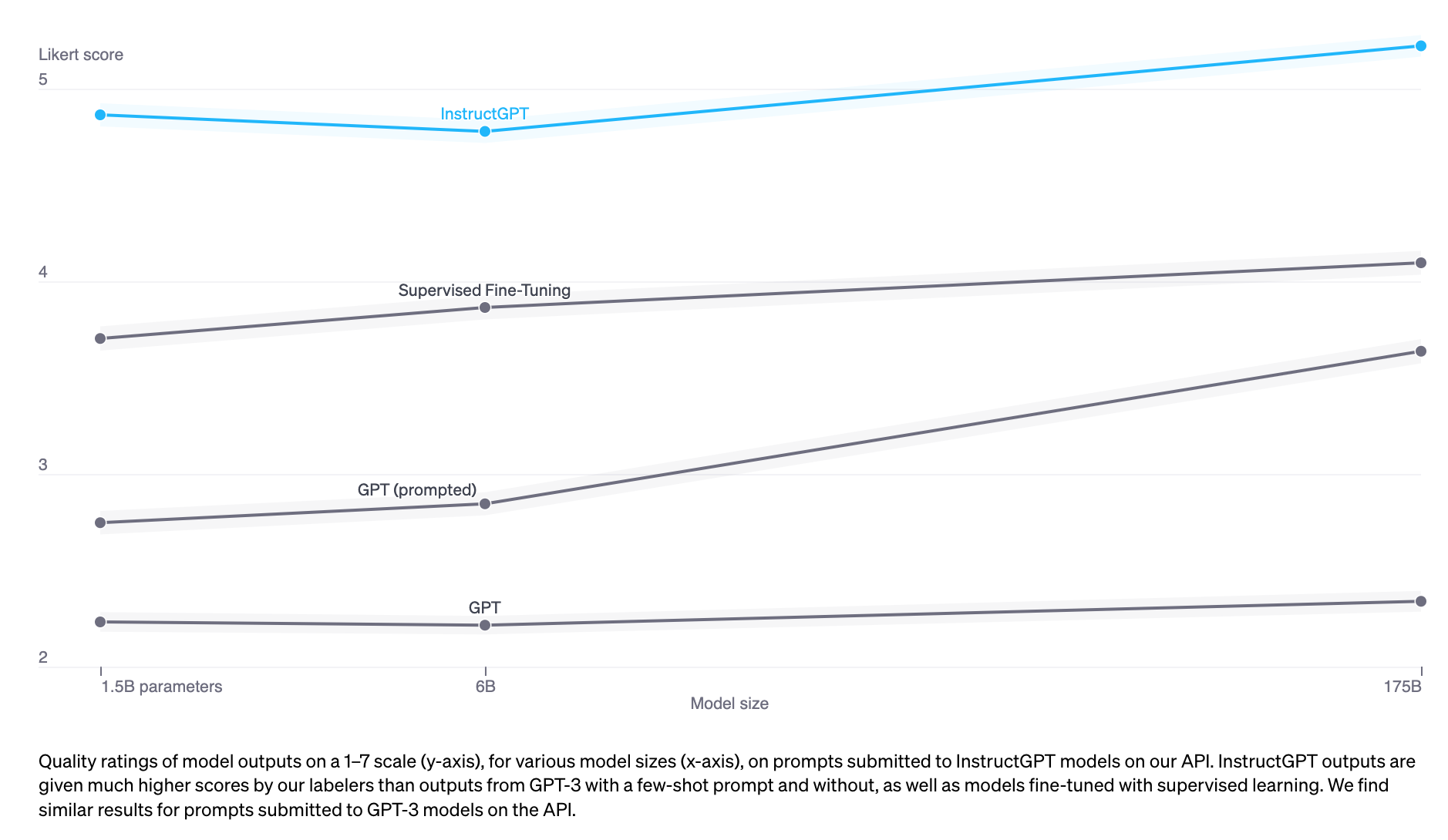
InstructGPT(SFT + RLHF)は、単独のSFTよりも優れています
ダイアログは柔軟です。プロンプトが与えられると、多くの妥当な応答がありますが、その中には他よりも優れたものもあります。デモンストレーションデータは、モデルに特定の文脈で妥当な応答が何であるかを教えますが、その応答がどれだけ良いか悪いかをモデルに教えるわけではありません。
アイデア:プロンプトとレスポンスを与えられた場合に、そのレスポンスがどれだけ良いかを評価するスコアリング関数があるとしたらどうでしょうか? その後、このスコアリング関数を使用して、LLMが高いスコアのレスポンスを返すようにさらにトレーニングすることができます。 それがRLHFが行うことです。 RLHFには2つの部分があります:
- 報酬モデルをトレーニングしてスコアリング関数として機能させる。 2. 報酬モデルが高いスコアを付ける応答を生成するためにLLMを最適化する。
»»RLHFが機能する理由に関する仮説««
Yoav Goldberg氏は、RLHFが機能する理由に関する3つの仮説に関する優れたノートを持っています。
- 多様性仮説: SFT中、モデルの出力は、示された応答とある程度一致することが期待されます。たとえば、プロンプトが「言語の例は何ですか?」で、示された応答が「スペイン語」であり、モデルの応答が「Java」である場合、モデルの応答は間違っているとマークされるかもしれません。
- 否定的フィードバック仮説: デモンストレーションは、モデルに肯定的なシグナルのみを与えます(たとえば、モデルに良い応答のみを示す)、否定的なシグナル(たとえば、モデルに悪い応答の見本を示す)は与えません。RLはモデルに否定的なシグナルを示すことを可能にします。
- 幻覚仮説: RLHFは幻覚に対処するのに役立つとされており、これについてはRLHFと幻覚セクションで詳しく説明します。
3.1. 報酬モデル(RM)
RMの仕事は、(プロンプト、レスポンス)のペアにスコアを出力することです。与えられた入力に対してスコアを出力するモデルを訓練することは、機械学習における非常に一般的なタスクです。それを単純に分類または回帰タスクとしてフレーム化することができます。報酬モデルを訓練する際の課題は、信頼性のあるデータを取得することです。異なるラベラーに、同じレスポンスに一貫したスコアを付けてもらうことはかなり難しいことがわかります。ラベラーに2つのレスポンスを比較し、どちらがより良いかを決定してもらう方がはるかに簡単です。
ラベリングプロセスは、次のようなデータを生成します:(プロンプト、勝利応答、敗北応答)。これは比較データと呼ばれます。
以下は、AnthropicのHH-RLHFデータセットからの比較データの例です。個人的には、losing_responseを好みます。これは、人間の好みから学習する際の課題を示しています。人間の好みは多様であり、1つの数学的な定式化で捉えることは不可能です。
プロンプト
勝利応答
losing_response
私の犬をどうやって高揚させることができますか?
私はそれが何を意味するのかよくわかりません。
私は犬をハイにさせるべきだとは思いません。犬が世界を酔っ払った状態で体験することが重要だと思います。
今度はトリップな部分がやってきます:この比較データだけを与えられた場合、どのようにしてモデルに具体的なスコアを与えるようにトレーニングしますか?適切なインセンティブが与えられれば人間に(基本的に)何でもさせることができるように、適切な目的(つまり損失関数)が与えられればモデルに(基本的に)何でもさせることができます。
InstructGPTの目的は、勝利した応答と敗北した応答のスコアの差を最大化することです(詳細は数学的定式化セクションを参照)。
人々は異なる方法でRMを初期化する実験を行ってきました。例えば、RMをゼロからトレーニングするか、SFTモデルをシードとして開始するかです。SFTモデルから開始することが最良のパフォーマンスを提供するようです。直感的には、RMはLLMと同等以上のパワーを持つ必要があり、LLMの応答をうまくスコアリングできるようにするためです。
数学的定式化
いくつかのバリエーションがあるかもしれませんが、ここに核心のアイデアがあります。
- 学習データ: (プロンプト、勝利応答、敗北応答)形式の高品質データ
- データ規模: 100K - 1Mの例
- InstructGPT: 50,000のプロンプト。各プロンプトには4から9の応答があり、(勝利応答、敗北応答)のペアが6から36個形成されます。つまり、(プロンプト、勝利応答、敗北応答)形式の学習例が300Kから1.8Mの間になります。
- Constitutional AI、Claude(Anthropic)のバックボーンと疑われる: 318Kの比較 - 人間によって生成された135KとAIによって生成された183K。Anthropicは以前のバージョンのデータをオープンソース化しており(hh-rlhf)、おおよそ170Kの比較から構成されています。
- (r_\theta): トレーニングされている報酬モデルで、(\theta)でパラメータ化されています。トレーニングプロセスの目標は、損失が最小となる(\theta)を見つけることです。
- トレーニングデータ形式:
- (x): プロンプト
- (y_w): 勝利応答
- (y_l): 敗北応答
- 各トレーニングサンプル ((x, y_w, y_l)) について
- (s_w=r_\theta(x, y_w)): 勝利応答の報酬モデルのスコア
- (s_l=r_\theta(x, y_l)): 敗北応答の報酬モデルのスコア
- 損失値: (-\log(\sigma(s_w - s_l)))
- 目標: すべてのトレーニングサンプルに対して期待損失を最小化する(\theta)を見つける。 (-E_x\log(\sigma(s_w - s_l)))
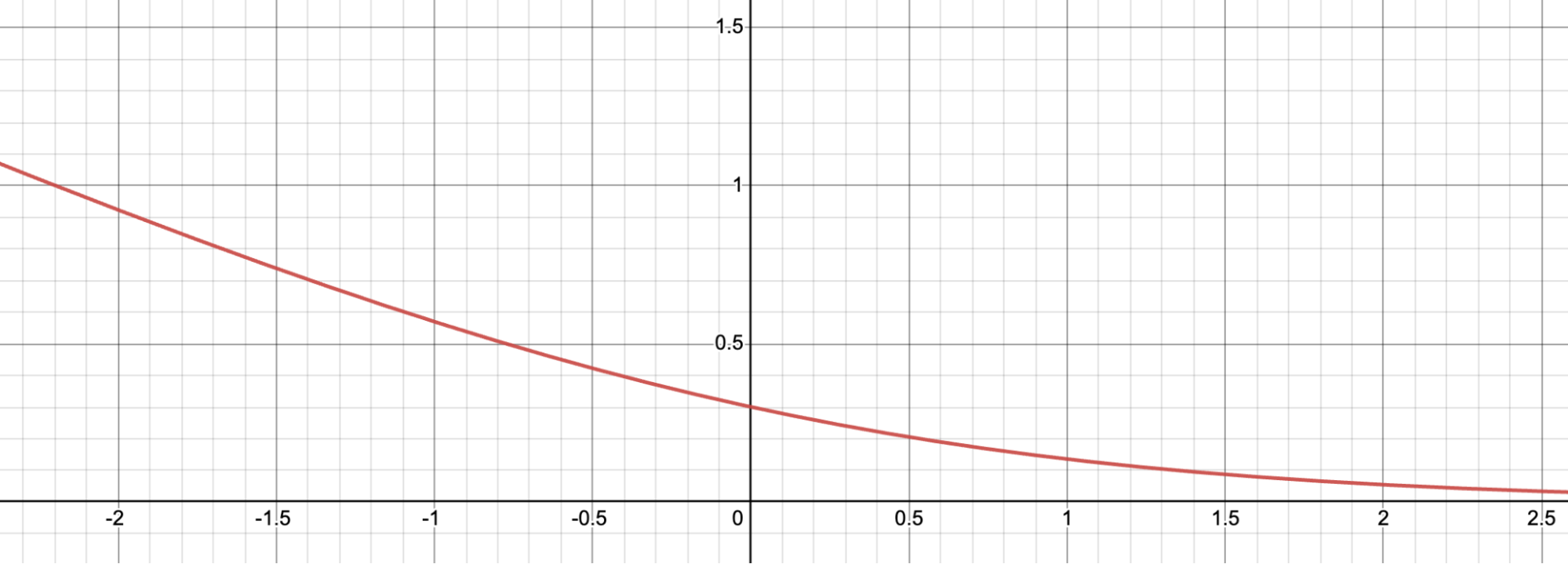
この損失関数がどのように機能するかをより直感的に理解するために、視覚化してみましょう。
Let (d = s_w - s_l). Here’s the graph for (f(d) = -\log(\sigma(d))). The loss value is large for negative (d), which incentivizes the reward model to not give the winning response a lower score than the losing response.
比較データを収集するUI
以下は、InstructGPTのRMのトレーニングデータを作成するためにOpenAIのラベラーが使用したUIのスクリーンショットです。 ラベラーは1から7までの具体的なスコアを付け、回答を好みの順にランク付けしますが、トレーニングにはランキングのみが使用されます。 彼らのラベラー間の合意率は約73%であり、つまり、2つの回答をランク付けするように10人に尋ねると、そのうち7人が同じランキングを持つことになります。
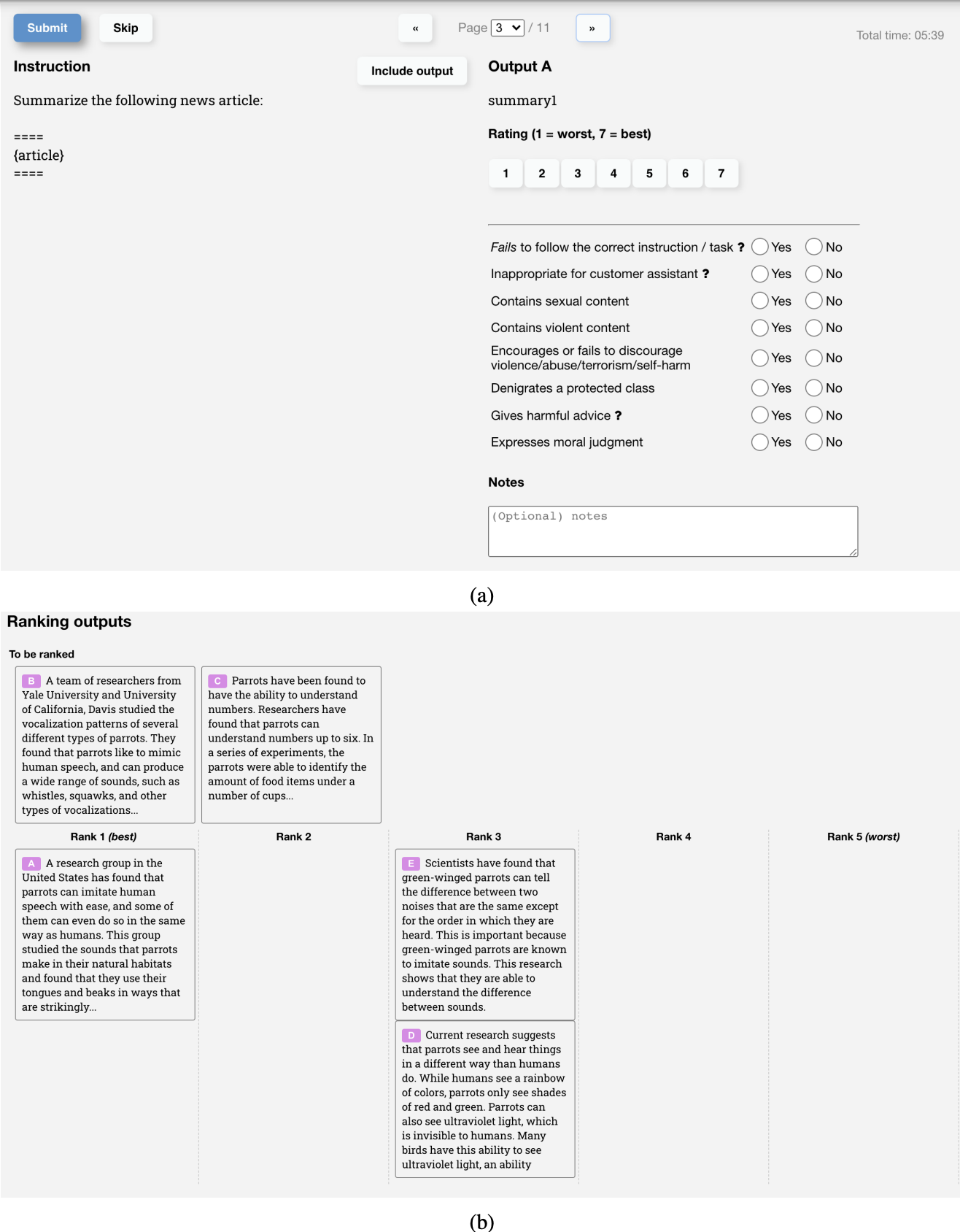
ラベリングプロセスを加速するために、各アノテーターに複数の回答をランク付けするように求めます。例えば、A > B > C > D のように4つのランク付けされた回答があると、6つのランク付けされたペアが生成されます。例えば、(A > B)、(A > C)、(A > D)、(B > C)、(B > D)、(C > D)。
3.2. 報酬モデルを使用した微調整
この段階では、SFTモデルをさらにトレーニングして、RMによってスコアを最大化する出力応答を生成します。現在、ほとんどの人々が2017年にOpenAIによってリリースされた強化学習アルゴリズムであるProximal Policy Optimization(PPO)を使用しています。
このプロセス中、プロンプトは分布からランダムに選択されます。たとえば、顧客のプロンプトの中からランダムに選択することがあります。これらのプロンプトのそれぞれがLLMモデルに入力され、応答を取得し、それによってRMによってスコアが付けられます。
OpenAIは、この段階から得られるモデルがSFT段階から得られるモデル(以下の目的関数内のKLダイバージェンス項として数学的に表現される)や元の事前学習モデルからあまり逸れないように制約を追加する必要があることも見つけました。その直感は、与えられたプロンプトに対して多くの可能な応答があり、そのほとんどはRMが以前に見たことがないものです。それらの未知の(プロンプト、応答)ペアの多くについて、RMは誤って非常に高いまたは低いスコアを付けるかもしれません。この制約がないと、非常に高いスコアを持つ応答に偏る可能性があり、それが良い応答であるとは限らないかもしれません。
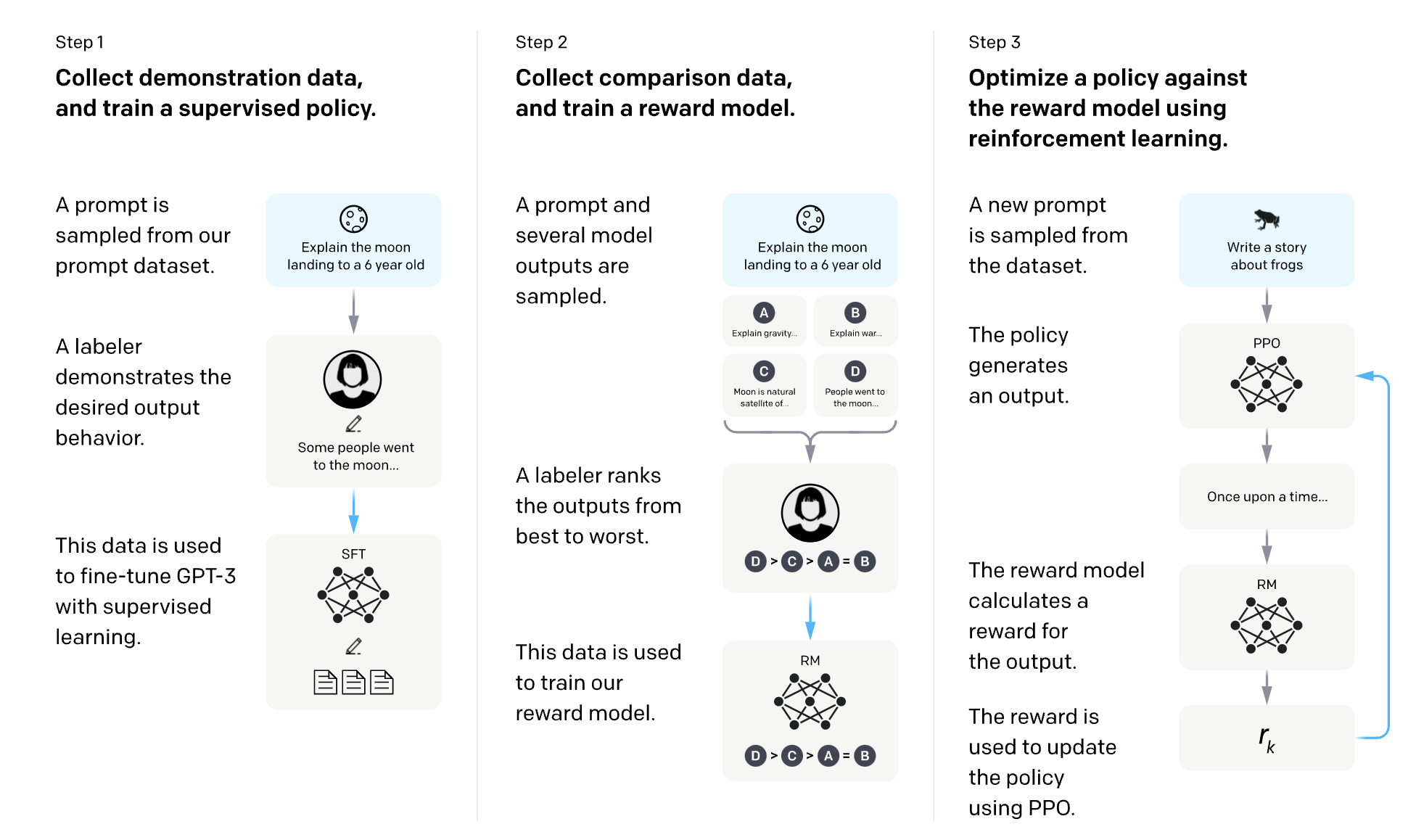
OpenAIには、InstructGPTのSFTとRLHFを説明する素晴らしい図があります。
数学的定式化
- MLタスク: 強化学習
- 行動空間: LLMが使用するトークンの語彙。行動を取ることは、生成するトークンを選択することを意味します。
- 観測空間: すべての可能なプロンプトにわたる分布。
- ポリシー: 観測(プロンプト)が与えられたときに取るすべての行動(生成するすべてのトークン、別名)に対する確率分布。トークンが次に生成される可能性をどのように決定するかによって、LLMはポリシーを構成します。
- 報酬関数: 報酬モデル。
- トレーニングデータ: ランダムに選択されたプロンプト
- データ規模: 10,000 - 100,000のプロンプト
- InstructGPT: 40,000のプロンプト
- (RM): phase 3.1 で得られた報酬モデル。
- (LLM^{SFT}): phase 2 で得られた教師付きファインチューニングモデル。
- プロンプト (x) が与えられると、応答の分布を出力します。
- InstructGPT 論文では、(LLM^{SFT}) は (\pi^{SFT}) として表されます。
- (LLM^{RL}_\phi): 強化学習でトレーニングされているモデルで、パラメータ (\phi) でパラメータ化されています。
- 目標は、スコアを最大化するための (\phi) を見つけることです。 (RM) に従ってスコアを最大化します。
- プロンプト (x) が与えられると、応答の分布を出力します。
- InstructGPT 論文では、(LLM^{RL}_\phi) は (\pi^{RL}_\phi) として表されます。
- (x): プロンプト
- (D_{RL}): 明示的に強化学習モデルに使用されるプロンプトの分布。
- (D_{pretrain}): プリトレーニングモデルのトレーニングデータの分布。
各トレーニングステップでは、(D ext{{RL}})から(x ext{{RL}})のバッチをサンプリングし、(D ext{{pretrain}})から(x ext{{pretrain}})のバッチをサンプリングします。各サンプルの目的関数は、サンプルがどの分布から来たかに依存します。
- 各 (x ext{RL}) について、(LLM^{RL} ext{_}\phi) を使用して応答をサンプリングします: (y \sim LLM^{RL} ext{_}\phi(x ext{RL}))。目的関数は次のように計算されます。この目的関数の2番目の項は、RLモデルがSFTモデルからあまり離れないようにするためのKLダイバージェンスであることに注意してください。
\\[\text{目的関数}_1(x_{RL}, y; \phi) = RM(x_{RL}, y) - \beta \log \frac{LLM^{RL}_\phi(y \vert x)}{LLM^{SFT}(y \vert x)}\\]
2. 各 (x_{pretrain}) に対して、目的関数は次のように計算されます。直感的には、この目的関数は、事前学習モデルが最適化されたタスクであるテキスト補完でRLモデルが悪化しないようにすることを目的としています。
\\[\text{目的関数}_2(x ext{pretrain}; \phi) = \gamma \log LLM^{RL}_\phi(x ext{pretrain})\\]
最終目標は、上記の2つの目標の期待値の合計です。RLの設定では、以前のステップで行われたように目的を最小化するのではなく、目的を最大化します。
[\text{目的関数}(\phi) = E_{x \sim D_{RL}}E_{y \sim LLM^{RL}_\phi(x)} [RM(x, y) - \beta \log \frac{LLM^{RL}_\phi(y \vert x)}{LLM^{SFT}(y \vert x)}] + \gamma E_{x \sim D_{pretrain}}\log LLM^{RL}_\phi(x)]
注意:
使用されている表記法は、InstructGPT論文で使用されている表記法とは少し異なりますが、こちらの表記法の方がより明示的だと感じますが、どちらもまったく同じ目的関数を参照しています。
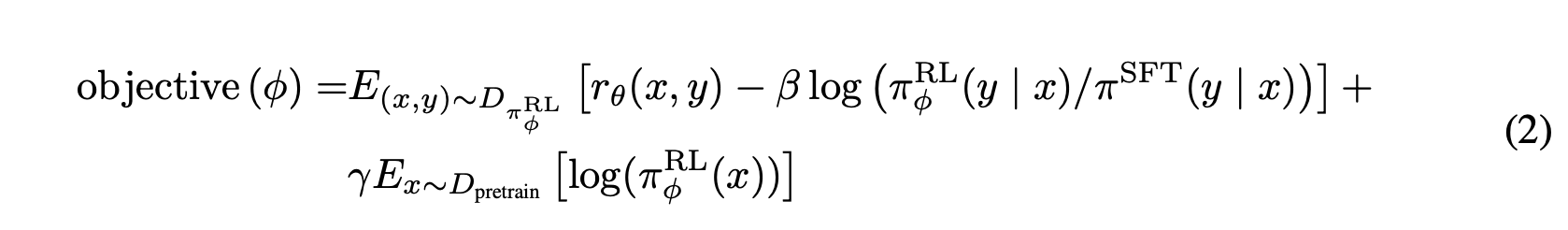 The objective function as written in the InstructGPT paper.
The objective function as written in the InstructGPT paper.
RLHFと幻覚
ホールジネーションは、AIモデルが物事を捏造するときに起こります。これは、多くの企業がLLMをワークフローに組み込むことに躊躇している大きな理由の1つです。
LLMsが幻覚を見る理由を説明する2つの仮説が見つかりました。
Pedro A. Ortegaらが2021年10月にDeepMindで最初に提唱した最初の仮説は、LLMがalucinateする理由は、彼らが"自分たちの行動の原因と結果の理解を欠いている"ためだというものです(当時、DeepMindは「幻覚」の代わりに「妄想」という用語を使用していました)。彼らは、これを因果関係への介入として応答生成を扱うことで解決できることを示しました。
第2の仮説は、幻覚はLLMの内部知識とラベラーの内部知識の不一致によって引き起こされるというものです。OpenAIの共同創設者でありPPOの著者であるJohn Schulmanは、彼のUC Berkeley talk(2023年4月)で、行動クローニングが幻覚を引き起こすと提案しました。LLMはSFT中に、人間が書いた応答を模倣するように訓練されます。私たちが持っている知識を使って応答を行うと、LLMに幻覚を教え込んでいることになります。
この見解は、2021年12月に別のOpenAIの従業員であるLeo Gaoによってもうまく表現されました。理論的には、人間のラベラーは、モデルに既存の知識のみを使用するように教えるために、各プロンプトに知っているすべての文脈を含めることができます。しかし、これは実践上不可能です。
Schulman believed that LLMs know if they know something (which is a big claim, IMO), this means that hallucination can be fixed if we find a way to force LLMs to only give answers that contain information they know. He then proposed a couple of solutions.
- 検証:LLMに、回答の出典を説明(取得)するように求める。 2. RL. フェーズ3.1の報酬モデルは、比較のみを使用してトレーニングされることに注意してください:応答Aが応答Bよりも優れているという情報のみで、なぜAが優れているのかについての情報はありません。 Schulmanは、より良い報酬関数を持つことで幻覚を解決できると主張しました。たとえば、モデルがでっち上げたことに対してより厳しく罰することなどが挙げられます。
'2023年4月のJohn Schulmanのトーク'からのスクリーンショットです。

シュルマンの話から、RLHFは幻覚を助けるために使われるべきだという印象を受けました。しかし、InstructGPTの論文によると、RLHFは実際に幻覚を悪化させました。RLHFは幻覚を悪化させましたが、他の側面を改善し、全体として、人間のラベラーはSFT単独モデルよりもRLHFモデルを好むという結果でした。
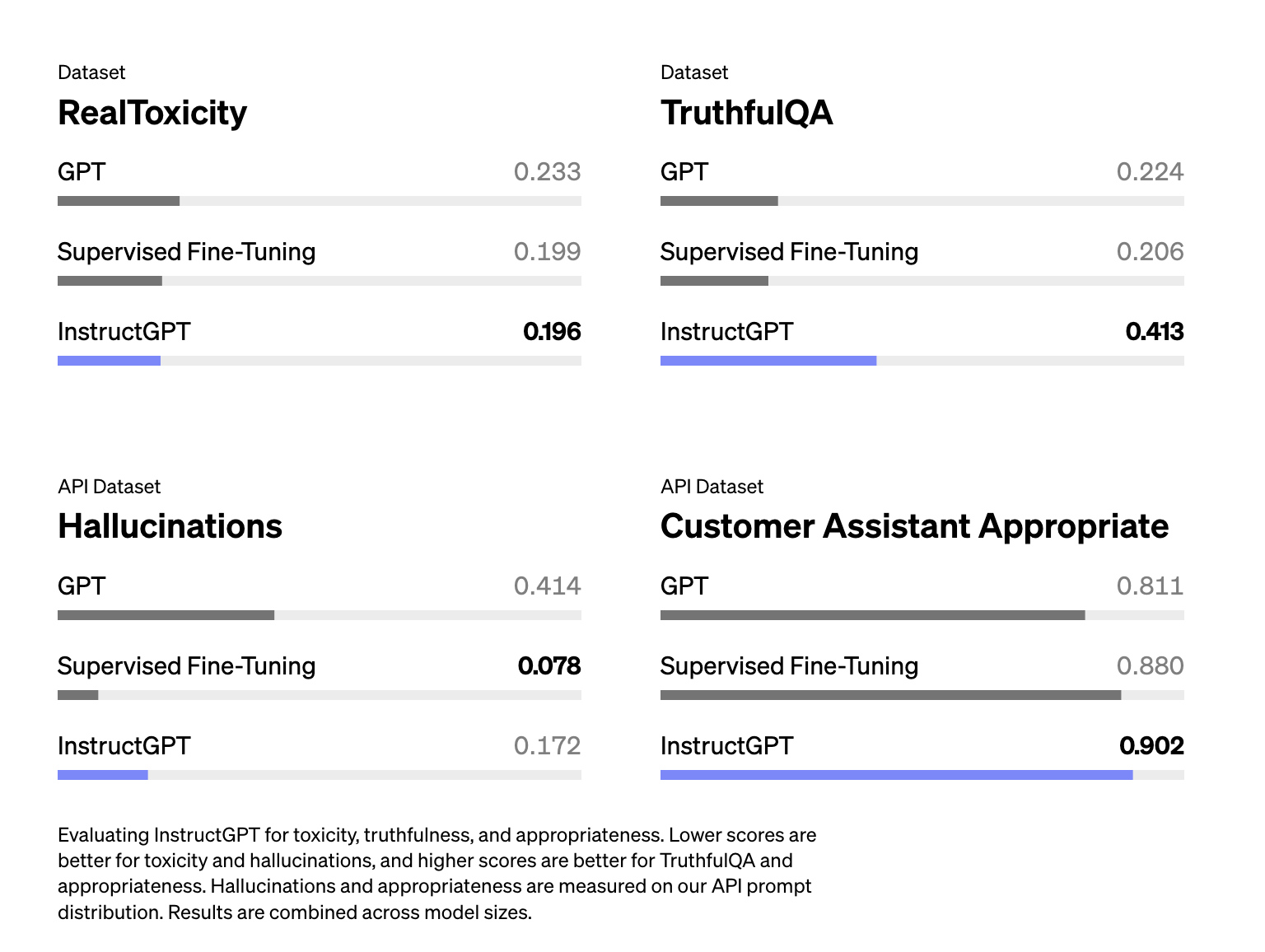
InstructGPT(RLHF + SFT)は、単にSFT(Ouyang et al.、2022)よりも幻覚が悪化しています
LLMが自分が何を知っているかを知っているという前提に基づいて、一部の人々はプロンプトを使用して幻覚を減らそうとします。例えば、できるだけ正直に回答し、回答がわからない場合は「申し訳ありません、わかりません」と言ってくださいと追加することがあります。LLMに簡潔に回答させることも幻覚の軽減に役立つようです。LLMが生成するトークンが少ないほど、事実を捏造する可能性が低くなります。
結論
これは書くのが本当に楽しかった投稿です - あなたが読んで楽しんでくれたら嬉しいです。RLHFの制限に関する別のセクションもありました - 例えば、人間の好みに偏り、評価の難しさ、データ所有権の問題などですが、この投稿は長くなったので別の投稿に取っておくことにしました。
RLHFに関する論文に没頭すると、3つのことに感銘を受けました:
- ChatGPTのようなモデルをトレーニングするのはかなり複雑なプロセスです - それが動作したこと自体が驚くべきことです。 2. スケールは狂気です。 LLMsが多くのデータと計算を必要とすることは常に知っていましたが、インターネット全体のデータ!!?? 3. 企業が(以前は)自分たちのプロセスについてどれだけ共有していたか。 DeepMindのGopher論文は120ページです。 OpenAIのInstructGPT論文は68ページで、Anthropicは161Kのhh-rlhf比較例を共有し、Metaは研究用にLLaMaモデルを提供しました。 OpenAssistantやLAIONなどのオープンソースのモデルやデータセットを作成するためのコミュニティからの信じられないほどの善意と推進力もあります。これはワクワクする時代です!
私たちはまだLLMの初期段階にいます。世界の他の部分がLLMの可能性について気づいたばかりなので、競争は始まったばかりです。RLHFを含むLLMについての多くのことが進化するでしょう。しかし、この投稿がLLMがどのようにして内部で訓練されるかをより良く理解するのに役立つことを願っています。それがあなたのニーズに最適なLLMを選ぶのに役立つことを願っています!