Dans cet article, nous plongeons dans le fonctionnement interne de Google, un outil que nous utilisons tous les jours mais que peu comprennent vraiment. Suite à la récente fuite de documents dans une poursuite antitrust contre Google, nous avons une opportunité unique d'explorer les algorithmes de Google. Certains de ces algorithmes étaient déjà connus, mais ce qui est intéressant, c'est l'information interne qui ne nous avait jamais été partagée.
Nous examinerons comment ces technologies traitent nos recherches et déterminent les résultats que nous voyons. Dans cette analyse, je vise à fournir une vue claire et détaillée des systèmes complexes derrière chaque recherche Google.
De plus, je vais tenter de représenter l'architecture de Google dans un diagramme, en tenant compte des nouvelles découvertes.
Tout d'abord, nous nous concentrerons sur l'extraction de tous les algorithmes mentionnés dans 2 documents. Le premier concerne le témoignage de Pandu Nayak (VP d'Alphabet) et le second concerne le témoignage de réfutation du professeur Douglas W. Oard, concernant les opinions exprimées par l'expert de Google, le professeur Edward A. Fox, dans son rapport daté du 3 juin 2022. Ce dernier document a débattu du célèbre et controversé « Rapport Fox », où Google a manipulé des données expérimentales pour tenter de démontrer que les données des utilisateurs ne leur sont pas si importantes.
Je vais essayer d'expliquer chaque algorithme en me basant sur les informations officielles, si elles sont disponibles, puis je mettrai les informations extraites de l'essai dans une image.

Navboost
C'est essentiel pour Google et l'un des facteurs les plus importants. Cela a également été révélé dans la fuite de «Project Veritas» en 2019 car Paul Haar l'a ajouté à son CV

Navboost collecte des données sur la manière dont les utilisateurs interagissent avec les résultats de recherche, en particulier en cliquant sur différentes requêtes. Ce système tabule les clics et utilise des algorithmes qui apprennent des évaluations de qualité faites par des humains pour améliorer le classement des résultats. L'idée est que si un résultat est fréquemment choisi (et évalué positivement) pour une requête spécifique, il devrait probablement avoir un classement plus élevé. Fait intéressant, Google a expérimenté il y a de nombreuses années la suppression de Navboost et a constaté que les résultats se détérioraient.

RankBrain
Lancé en 2015, RankBrain est un système d'intelligence artificielle et d'apprentissage automatique de Google, essentiel dans le traitement des résultats de recherche. Grâce à l'apprentissage automatique, il améliore continuellement sa capacité à comprendre le langage et les intentions derrière les recherches, et est particulièrement efficace pour interpréter des requêtes ambiguës ou complexes. On dit qu'il est devenu le troisième facteur le plus important dans le classement de Google, après le contenu et les liens. Il utilise une Unité de traitement de tenseurs (TPU) pour améliorer considérablement sa capacité de traitement et son efficacité énergétique.

Je déduis que QBST et Pondération des termes sont des composants de RankBrain. Donc, je les inclue ici.
QBST (Query Based Salient Terms) se concentre sur les termes les plus importants au sein d'une requête et des documents associés, utilisant ces informations pour influencer le classement des résultats. Cela signifie que le moteur de recherche peut rapidement reconnaître les aspects les plus importants d'une requête de l'utilisateur et prioriser les résultats pertinents. Par exemple, cela est particulièrement utile pour les requêtes ambiguës ou complexes.
Dans le document de témoignage, QBST est mentionné dans le contexte des limites de BERT. La mention spécifique est que « BERT ne subsume pas les grands systèmes de mémorisation tels que navboost, QBST, etc. » Cela signifie que bien que BERT soit très efficace pour comprendre et traiter le langage naturel, il présente certaines limites, dont sa capacité à gérer ou remplacer des systèmes de mémorisation à grande échelle comme QBST.

Pondération des termes ajuste l'importance relative des termes individuels dans une requête, en fonction de la manière dont les utilisateurs interagissent avec les résultats de recherche. Cela aide à déterminer la pertinence de certains termes dans le contexte de la requête. Cette pondération gère également efficacement les termes très courants ou très rares dans la base de données du moteur de recherche, équilibrant ainsi les résultats.

DeepRank
Va encore plus loin dans la compréhension du langage naturel, permettant au moteur de recherche de mieux comprendre l'intention et le contexte des requêtes. Cela est rendu possible grâce à BERT ; en fait, DeepRank est le nom interne de BERT. En se pré-entraînant sur une grande quantité de données de documents et en ajustant avec les retours des clics et les évaluations humaines, DeepRank peut affiner les résultats de recherche pour les rendre plus intuitifs et pertinents par rapport à ce que les utilisateurs recherchent réellement.

RankEmbed
RankEmbed se concentre probablement sur la tâche d'incorporer des caractéristiques pertinentes pour le classement. Bien qu'il n'y ait pas de détails spécifiques sur sa fonction et ses capacités dans les documents, nous pouvons en déduire qu'il s'agit d'un système d'apprentissage profond conçu pour améliorer le processus de classification de la recherche de Google.
RankEmbed-BERT
RankEmbed-BERT est une version améliorée de RankEmbed, intégrant l'algorithme et la structure de BERT. Cette intégration a été réalisée pour améliorer significativement les capacités de compréhension du langage de RankEmbed. Son efficacité peut diminuer s'il n'est pas réentraîné avec des données récentes. Pour son entraînement, il n'utilise qu'une petite fraction du trafic, ce qui indique qu'il n'est pas nécessaire d'utiliser toutes les données disponibles.
RankEmbed-BERT contribue, aux côtés d'autres modèles d'apprentissage profond tels que RankBrain et DeepRank, au score de classement final dans le système de recherche de Google, mais fonctionnerait après la récupération initiale des résultats (reclassement). Il est entraîné sur des données de clics et de requêtes, et est finement réglé à l'aide de données d'évaluateurs humains (IS), ce qui le rend plus coûteux en termes de puissance de calcul à entraîner que les modèles à propagation avant tels que RankBrain.

MUM
Il est environ 1 000 fois plus puissant que BERT et représente une avancée majeure dans la recherche de Google. Lancé en juin 2021, il comprend non seulement 75 langues, mais il est également multimodal, ce qui signifie qu'il peut interpréter et traiter des informations dans différents formats. Cette capacité multimodale permet à MUM d'offrir des réponses plus complètes et contextuelles, réduisant le besoin de multiples recherches pour obtenir des informations détaillées. Cependant, son utilisation est très sélective en raison de sa forte demande en calcul.

Tangram et colle
Tous ces systèmes fonctionnent ensemble dans le cadre de Tangram, qui est responsable de l'assemblage de la SERP avec des données de Glue. Il ne s'agit pas seulement de classer les résultats, mais de les organiser de manière utile et accessible aux utilisateurs, en tenant compte d'éléments tels que les carrousels d'images, les réponses directes et d'autres éléments non textuels.

Enfin, Freshness Node et Instant Glue garantissent que les résultats sont actuels, accordant plus de poids aux informations récentes, ce qui est particulièrement crucial dans les recherches sur les actualités ou les événements en cours.

Lors du procès, ils font référence à l'attaque à Nice, où l'intention principale de la requête a changé le jour de l'attaque, amenant Instant Glue à supprimer les images générales au profit de Tangram et à promouvoir à la place des actualités pertinentes et des photographies de Nice («belles photos» vs «Nice pictures») :

Avec tout cela, Google combinerait ces algorithmes pour :
- Comprendre la requête : Décrypter l'intention derrière les mots et les phrases que les utilisateurs saisissent dans la barre de recherche.
- Déterminer la pertinence : Classer les résultats en fonction de la correspondance avec la requête, en utilisant des signaux issus des interactions passées et des évaluations de qualité.
- Prioriser la fraîcheur : Veiller à ce que les informations les plus récentes et les plus pertinentes remontent dans les classements lorsque c'est important.
- Personnaliser les résultats : Adapter les résultats de recherche non seulement à la requête, mais aussi au contexte de l'utilisateur, comme sa localisation et l'appareil qu'il utilise. Il n'y a presque pas plus de personnalisation que cela.
D'après tout ce que nous avons vu jusqu'à présent, je crois que Tangram, Glue et RankEmbed-BERT sont les seuls éléments nouveaux qui ont fuité jusqu'à présent.
Comme nous l'avons vu, ces algorithmes sont nourris par diverses métriques que nous allons maintenant décomposer, une fois de plus, en extrayant des informations de l'essai.
Métriques utilisées par Google pour évaluer la qualité de la recherche
Dans cette section, nous nous concentrerons à nouveau sur le témoignage de réfutation du professeur Douglas W. Oard et inclurons des informations provenant d'une fuite précédente, celle de «Project Veritas».
Dans l'une des diapositives, il a été montré que Google utilise les métriques suivantes pour développer et ajuster les facteurs que son algorithme prend en compte lors du classement des résultats de recherche et pour surveiller comment les changements dans son algorithme affectent la qualité des résultats de recherche. L'objectif est d'essayer de capturer l'intention de l'utilisateur avec eux.
1. Score IS
Les évaluateurs humains jouent un rôle crucial dans le développement et l'amélioration des produits de recherche de Google. Grâce à leur travail, la métrique connue sous le nom de « IS score » (Indice de Satisfaction de l'Information, allant de 0 à 100) est générée, dérivée des évaluations des évaluateurs et utilisée comme indicateur principal de la qualité chez Google.
Il est évalué de manière anonyme, où les évaluateurs ne savent pas s'ils testent Google ou Bing, et il est utilisé pour comparer les performances de Google à celles de son principal concurrent.
Ces scores IS reflètent non seulement la qualité perçue, mais sont également utilisés pour entraîner divers modèles au sein du système de recherche de Google, y compris des algorithmes de classification tels que RankBrain et RankEmbed BERT.
Selon les documents, à partir de 2021, ils utilisent IS4. IS4 est considéré comme une approximation de l'utilité pour l'utilisateur et doit être traité comme tel. Il est décrit comme potentiellement la métrique de classement la plus importante, mais ils soulignent qu'il s'agit d'une approximation et qu'il est sujet à des erreurs que nous discuterons plus tard.

Un dérivé de cette métrique, le IS4@5, est également mentionné.
La métrique IS4@5 est utilisée par Google pour mesurer la qualité des résultats de recherche, en se concentrant spécifiquement sur les cinq premières positions. Cette métrique inclut à la fois des fonctionnalités de recherche spéciales, telles que les OneBoxes (connues sous le nom de «liens bleus»). Il existe une variante de cette métrique, appelée IS4@5 web, qui se concentre exclusivement sur l'évaluation des cinq premiers résultats Web, en excluant d'autres éléments tels que la publicité dans les résultats de recherche.

Bien que IS4@5 soit utile pour évaluer rapidement la qualité et la pertinence des meilleurs résultats d'une recherche, sa portée est limitée. Il ne couvre pas tous les aspects de la qualité de la recherche, en omettant notamment des éléments tels que la publicité dans les résultats. Par conséquent, la métrique fournit une vue partielle de la qualité de la recherche. Pour une évaluation complète et précise de la qualité des résultats de recherche de Google, il est nécessaire de prendre en compte un éventail plus large de métriques et de facteurs, de manière similaire à l'évaluation de la santé générale à travers une variété d'indicateurs et pas seulement par le poids.
**Limitations des évaluateurs humains
Les évaluateurs sont confrontés à plusieurs problèmes, tels que la compréhension des requêtes techniques ou l'évaluation de la popularité des produits ou des interprétations des requêtes. De plus, les modèles de langage comme MUM pourraient parvenir à comprendre le langage et les connaissances mondiales de manière similaire aux évaluateurs humains, offrant à la fois des opportunités et des défis pour l'avenir de l'évaluation de la pertinence.
Malgré leur importance, leur perspective diffère significativement de celle des utilisateurs réels. Les évaluateurs peuvent manquer de connaissances spécifiques ou d'expériences antérieures que les utilisateurs pourraient avoir par rapport à un sujet de requête, ce qui pourrait potentiellement influencer leur évaluation de la pertinence et la qualité des résultats de recherche.
À partir de documents divulgués de 2018 et 2021, j'ai pu compiler une liste de toutes les erreurs que Google reconnaît avoir dans ses présentations internes.
- Désynchronisations temporelles : Des écarts peuvent survenir car les requêtes, les évaluations et les documents peuvent provenir de périodes différentes, ce qui conduit à des évaluations qui ne reflètent pas avec précision la pertinence actuelle des documents. 2. Réutilisation des évaluations : La pratique de réutiliser des évaluations pour évaluer rapidement et maîtriser les coûts peut entraîner des évaluations qui ne sont pas représentatives de la fraîcheur ou de la pertinence actuelle du contenu. 3. Compréhension des requêtes techniques : Les évaluateurs peuvent ne pas comprendre les requêtes techniques, ce qui rend difficile l'évaluation de la pertinence des sujets spécialisés ou de niche. 4. Évaluation de la popularité : Il est intrinsèquement difficile pour les évaluateurs de juger de la popularité parmi les interprétations de requêtes concurrentes ou les produits rivaux, ce qui pourrait affecter la précision de leurs évaluations. 5. Diversité des évaluateurs : Le manque de diversité parmi les évaluateurs dans certaines régions, et le fait qu'ils sont tous des adultes, ne reflète pas la diversité de la base d'utilisateurs de Google, qui inclut des mineurs. 6. Contenu généré par les utilisateurs : Les évaluateurs ont tendance à être sévères avec le contenu généré par les utilisateurs, ce qui peut conduire à sous-estimer sa valeur et sa pertinence, bien qu'il soit utile et pertinent. 7. Formation des nœuds de fraîcheur : Ils signalent un problème avec l'ajustement des modèles de fraîcheur en raison d'un manque d'étiquettes de formation adéquates. Les évaluateurs humains ne prêtent souvent pas suffisamment attention à l'aspect de la fraîcheur de la pertinence ou manquent du contexte temporel pour la requête. Cela conduit à sous-évaluer les résultats récents pour les requêtes cherchant de la nouveauté. L'utilitaire Tangram existant, basé sur IS et utilisé pour former la pertinence et d'autres courbes de notation, a souffert du même problème. En raison de la limitation des étiquettes humaines, les courbes de notation du nœud de fraîcheur ont été ajustées manuellement lors de sa première publication.
Je crois sincèrement que les évaluateurs humains ont été responsables du bon fonctionnement du « Parasite SEO », quelque chose qui a finalement attiré l'attention de Danny Sullivan et est partagé dans ce tweet :

Si nous examinons les changements apportés aux dernières directives de qualité, nous pouvons voir comment ils ont enfin ajusté la définition des métriques de Satisfaction des besoins et ont inclus un nouvel exemple pour que les évaluateurs le prennent en compte, même si un résultat est fiable, s'il ne contient pas les informations recherchées par l'utilisateur, il ne devrait pas être évalué aussi favorablement.

Le nouveau lancement de Google Notes, je crois, pointe également dans cette direction. Google est incapable de savoir avec 100% de certitude ce qui constitue un contenu de qualité.

Je crois que ces événements dont je parle, qui se sont produits presque simultanément, ne sont pas une coïncidence et que nous verrons bientôt des changements.
2. PQ (Page Quality)
Ici, je déduis qu'ils parlent de la Qualité de la Page, donc voici mon interprétation. S'il en est ainsi, il n'y a rien dans les documents d'essai au-delà de sa mention en tant que métrique utilisée. La seule chose officielle que j'ai mentionnant la QP provient des Directives des évaluateurs de la qualité de la recherche, qui évoluent avec le temps. Donc, ce serait une autre tâche pour les évaluateurs humains.

Ces informations sont également envoyées aux algorithmes pour créer des modèles. Ici, nous pouvons voir une proposition de cela divulguée dans le «Project Veritas» :

Un point intéressant ici, selon les documents, les évaluateurs de qualité n'évaluent que les pages sur mobile.

3. Côte à côte
Cela fait probablement référence à des tests où deux ensembles de résultats de recherche sont placés côte à côte afin que les évaluateurs puissent comparer leur qualité relative. Cela aide à déterminer quel ensemble de résultats est plus pertinent ou utile pour une requête de recherche donnée. Si c'est le cas, je me souviens que Google avait son propre outil téléchargeable pour cela, le sxse.

L'outil permet aux utilisateurs de voter pour l'ensemble des résultats de recherche qu'ils préfèrent, fournissant ainsi un retour direct sur l'efficacité des différents ajustements ou versions des systèmes de recherche.
4. Expériences en direct
Les informations officielles publiées dans Comment fonctionne la recherche indiquent que Google mène des expériences avec du trafic réel pour tester comment les gens interagissent avec une nouvelle fonctionnalité avant de la déployer pour tout le monde. Ils activent la fonctionnalité pour un petit pourcentage d'utilisateurs et comparent leur comportement avec un groupe témoin qui n'a pas la fonctionnalité. Les métriques détaillées sur l'interaction des utilisateurs avec les résultats de recherche incluent :
- Clics sur les résultats
- Nombre de recherches effectuées
- Abandon de la requête
- Temps mis par les utilisateurs pour cliquer sur un résultat
Ces données permettent de mesurer si l'interaction avec la nouvelle fonctionnalité est positive et garantissent que les changements augmentent la pertinence et l'utilité des résultats de recherche.
Mais les documents du procès ne mettent en évidence que deux mesures :

- Clics longs pondérés par la position : Cette métrique prendrait en compte la durée des clics et leur position sur la page de résultats, reflétant la satisfaction de l'utilisateur par rapport aux résultats trouvés. 2. Attention : Cela pourrait impliquer de mesurer le temps passé sur la page, donnant une idée de la durée pendant laquelle les utilisateurs interagissent avec les résultats et leur contenu.
De plus, dans la transcription du témoignage de Pandu Nayak, il est expliqué qu'ils réalisent de nombreux tests d'algorithmes en utilisant l'interleaving au lieu des tests A/B traditionnels. Cela leur permet d'effectuer des expériences rapides et fiables, ce qui leur permet d'interpréter les fluctuations dans les classements.
5. Fraîcheur
La fraîcheur est un aspect crucial à la fois des résultats et des fonctionnalités de recherche. Il est essentiel de montrer des informations pertinentes dès qu'elles sont disponibles et de cesser d'afficher du contenu lorsqu'il devient obsolète.
Pour que les algorithmes de classement affichent les documents récents dans les pages de résultats des moteurs de recherche, les systèmes d'indexation et de diffusion doivent être capables de découvrir, d'indexer et de diffuser des documents récents avec une très faible latence. Idéalement, l'ensemble de l'index serait aussi à jour que possible, mais il existe des contraintes techniques et financières qui empêchent l'indexation de chaque document avec une faible latence. Le système d'indexation donne la priorité à des documents sur des chemins séparés, offrant différents compromis entre la latence, le coût et la qualité.
Il existe un risque que le contenu très récent voie sa pertinence sous-estimée et, inversement, que le contenu avec beaucoup de preuves de pertinence devienne moins pertinent en raison d'un changement de sens de la requête.

Le rôle du Nœud de Fraîcheur est d'apporter des corrections aux scores obsolètes. Pour les requêtes cherchant du contenu frais, il promeut le contenu frais et dégrade le contenu obsolète.
Il n'y a pas si longtemps, il a été révélé que Google Caffeine n'existe plus (également connu sous le nom de système d'indexation basé sur Percolator). Bien que le nom ancien soit toujours utilisé en interne, ce qui existe maintenant est en fait un tout nouveau système. Le nouveau «caféine» est en réalité un ensemble de microservices qui communiquent entre eux. Cela implique que différentes parties du système d'indexation fonctionnent comme des services indépendants mais interconnectés, chacun exécutant une fonction spécifique. Cette structure peut offrir une plus grande flexibilité, une évolutivité et une facilité de mise à jour et d'amélioration.
Tel que je l'interprète, une partie de ces microservices serait Tangram et Glue, plus précisément le Nœud de Fraîcheur et Glue Instantané. Je dis cela car dans un autre document divulgué par «Project Veritas», j'ai trouvé qu'il y avait une proposition datant de 2016 pour créer ou incorporer un «Instant Navboost» en tant que signal de fraîcheur, ainsi que des visites sur Chrome.

Jusqu'à présent, ils avaient déjà incorporé «Freshdocs-instant» (extrait d'une liste de pubsub appelée freshdocs-instant-docs pubsub, où ils ont pris les nouvelles publiées par ces médias dans la minute suivant leur publication) et les pics de recherche et les corrélations de génération de contenu :

Dans les métriques de fraîcheur, nous en avons plusieurs qui sont détectées grâce à l'analyse des N-grammes corrélés et des termes saillants corrélés :
- NGrammes corrélés : Il s'agit de groupes de mots qui apparaissent ensemble dans un schéma statistiquement significatif. La corrélation peut soudainement augmenter lors d'un événement ou d'un sujet tendance, indiquant un pic.
- Termes saillants corrélés : Il s'agit de termes remarquables qui sont étroitement associés à un sujet ou un événement et dont la fréquence d'occurrence augmente dans les documents sur une courte période, suggérant un pic d'intérêt ou d'activité connexe.
Une fois que des pics sont détectés, les métriques de fraîcheur suivantes pourraient être utilisées :
- Unigrammes (RTW) : Pour chaque document, le titre, les textes d'ancre et les 400 premiers caractères du texte principal sont utilisés. Ils sont décomposés en unigrammes pertinents pour la détection de tendances et ajoutés à l'index Hivemind. Le texte principal contient généralement le contenu principal de l'article, à l'exclusion des éléments répétitifs ou communs (boilerplate).
- Demi-heures depuis l'époque (TEHH) : Il s'agit d'une mesure du temps exprimée en nombre de demi-heures depuis le début du temps Unix. Cela permet de déterminer quand quelque chose s'est produit avec une précision de demi-heure.
- Entités du graphe de connaissances (RTKG) : Références à des objets dans le graphe de connaissances de Google, qui est une base de données d'entités réelles (personnes, lieux, choses) et de leurs interconnexions. Cela contribue à enrichir la recherche avec une compréhension sémantique et un contexte.
- Cellules S2 (S2) : Références à des objets dans le graphe de connaissances de Google, qui est une base de données d'entités réelles (personnes, lieux, choses) et de leurs interconnexions. Cela contribue à enrichir la recherche avec une compréhension sémantique et un contexte.
- Score d'article Freshbox (RTF) : Il s'agit de divisions géométriques de la surface de la Terre utilisées pour l'indexation géographique dans les cartes. Elles facilitent l'association du contenu web avec des emplacements géographiques précis.
- NSR du document (RTN) : Cela pourrait se référer à la Pertinence des Nouvelles du Document et semble être une mesure qui détermine à quel point un document est pertinent et fiable par rapport aux actualités ou événements tendances. Cette mesure peut également aider à filtrer les contenus de faible qualité ou indésirables, garantissant que les documents indexés et mis en évidence sont de haute qualité et significatifs pour les recherches en temps réel.
- Dimensions géographiques : Caractéristiques qui définissent l'emplacement géographique d'un événement ou d'un sujet mentionné dans le document. Celles-ci peuvent inclure des coordonnées, des noms de lieu ou des identifiants tels que les cellules S2.
Si vous travaillez dans les médias, cette information est essentielle et je l'inclus toujours dans mes formations pour les rédacteurs numériques.
L'importance des clics
Dans cette section, nous nous concentrerons sur la présentation interne de Google partagée dans un e-mail, intitulée «Unified Click Prediction», la présentation «Google is Magical», la présentation Search All Hands, un e-mail interne de Danny Sullivan, et les documents de la fuite «Project Veritas».
Tout au long de ce processus, nous voyons l'importance fondamentale des clics dans la compréhension du comportement/besoins des utilisateurs. En d'autres termes, Google a besoin de nos données. Fait intéressant, l'une des choses que Google était interdit de mentionner était les clics.

Avant de commencer, il est important de noter que les principaux documents discutant des clics datent d'avant 2016, et Google a subi des changements significatifs depuis lors. Malgré cette évolution, la base de leur approche reste l'analyse du comportement des utilisateurs, le considérant comme un signal de qualité. Vous souvenez-vous du brevet où ils expliquent le modèle CAS?

Chaque recherche et clic fourni par les utilisateurs contribue à l'apprentissage et à l'amélioration continue de Google. Cette boucle de rétroaction permet à Google de s'adapter et de «apprendre» sur les préférences de recherche et les comportements, maintenant l'illusion qu'il comprend les besoins des utilisateurs.

Chaque jour, Google analyse plus d'un milliard de nouveaux comportements au sein d'un système conçu pour ajuster en continu et dépasser les prédictions futures basées sur les données passées. Au moins jusqu'en 2016, cela dépassait la capacité des systèmes d'IA de l'époque, nécessitant le travail manuel que nous avons vu précédemment ainsi que des ajustements effectués par RankLab.
RankLab, je comprends, est un laboratoire qui teste différents poids dans les signaux et les facteurs de classement, ainsi que leur impact ultérieur. Ils pourraient également être responsables de l'outil interne «Twiddler» (quelque chose que j'ai également lu il y a des années chez «Project Veritas»), dans le but de modifier manuellement les scores IR de certains résultats, ou en d'autres termes, être capable de faire tout ce qui suit :

Après cette brève parenthèse, je continue.
Alors que les évaluations des évaluateurs humains offrent une vue de base, les clics fournissent un panorama beaucoup plus détaillé du comportement de recherche.


Cela révèle des schémas complexes et permet d'apprendre les effets de deuxième et troisième ordre.
- Les effets de second ordre reflètent des schémas émergents : si la majorité préfère et choisit des articles détaillés plutôt que des listes rapides, Google le détecte. Avec le temps, il ajuste ses algorithmes pour prioriser ces articles plus détaillés dans les recherches connexes.
- Les effets de troisième ordre sont des changements plus larges et à long terme : si les tendances de clic favorisent les guides complets, les créateurs de contenu s'adaptent. Ils commencent à produire plus d'articles détaillés et moins de listes, changeant ainsi la nature du contenu disponible sur le web.
Dans les documents analysés, un cas spécifique est présenté où la pertinence des résultats de recherche a été améliorée grâce à l'analyse des clics. Google a identifié une disparité dans les préférences des utilisateurs, basée sur les clics, en faveur de quelques documents qui se sont avérés pertinents, malgré leur entourage de 15 000 documents considérés comme non pertinents. Cette découverte souligne l'importance des clics des utilisateurs comme un outil précieux pour discerner la pertinence cachée dans de grands volumes de données.

Google «trains with the past to predict the future» pour éviter le surajustement. Grâce à des évaluations constantes et à la mise à jour des données, les modèles restent actuels et pertinents. Un aspect clé de cette stratégie est la personnalisation de la localisation, garantissant que les résultats sont pertinents pour différents utilisateurs dans diverses régions.
En ce qui concerne la personnalisation, dans un document plus récent, Google affirme qu'elle est limitée et change rarement les classements. Ils mentionnent également qu'elle ne se produit jamais dans les «Top Stories». Elle est utilisée pour mieux comprendre ce qui est recherché, par exemple en utilisant le contexte des recherches précédentes et pour faire des suggestions prédictives avec l'autocomplétion. Ils mentionnent qu'ils pourraient légèrement favoriser un fournisseur de vidéos que l'utilisateur utilise fréquemment, mais tout le monde verrait essentiellement les mêmes résultats. Selon eux, la requête est plus importante que les données utilisateur.
Il est important de se rappeler que cette approche axée sur les clics est confrontée à des défis, surtout avec du contenu nouveau ou peu fréquent. Évaluer la qualité des résultats de recherche est un processus complexe qui va au-delà de la simple comptabilisation des clics. Bien que cet article que j'ai écrit ait plusieurs années, je pense qu'il peut aider à approfondir cette question.
Architecture de Google
Suite à la section précédente, voici l'image mentale que je me suis formée de la manière dont nous pourrions placer tous ces éléments dans un diagramme. Il est très probable que certains composants de l'architecture de Google ne se trouvent pas à certains endroits ou ne sont pas liés de cette manière, mais je crois que c'est plus que suffisant comme approximation.
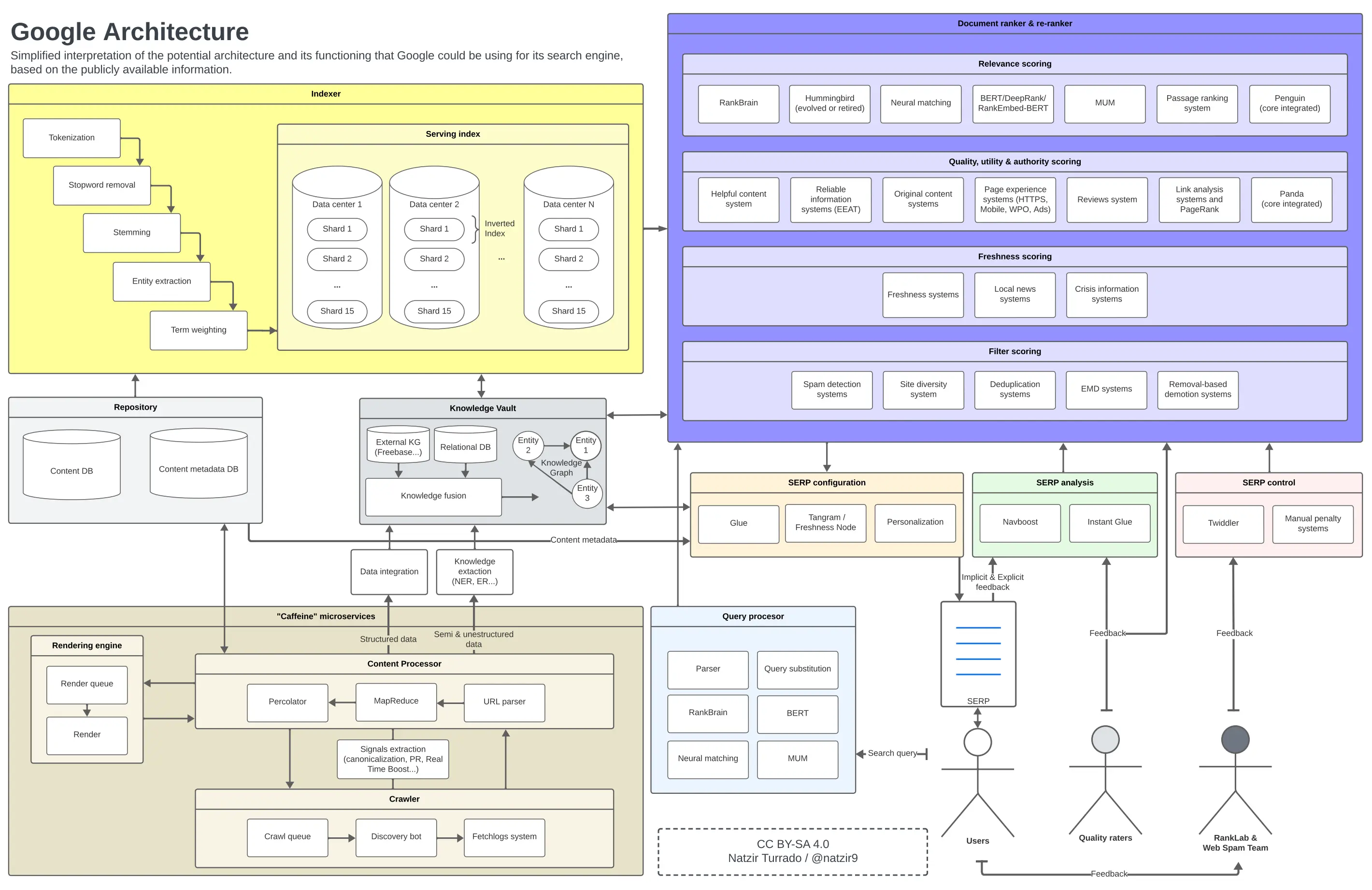
Fonctionnement et architecture possibles de Google. Cliquez pour agrandir l'image.
Google et Chrome : La lutte pour être le moteur de recherche et le navigateur par défaut
Dans cette dernière section, nous nous concentrons sur le témoignage de l'expert Antonio Rangel, économiste du comportement et professeur à Caltech, concernant l'utilisation des options par défaut pour influencer les choix des utilisateurs, dans la présentation interne intitulée « Sur la valeur stratégique de la page d'accueil par défaut de Google », ainsi que dans les déclarations de Jim Kolotouros, vice-président chez Google, dans un e-mail interne.
Comme le révèle Jim Kolotouros dans les communications internes, Chrome n'est pas seulement un navigateur, mais aussi un élément clé dans le puzzle de la domination de la recherche de Google.
Parmi les données collectées par Google figurent les tendances de recherche, les clics sur les résultats de recherche et les interactions avec différents sites web, ce qui est crucial pour affiner les algorithmes de Google, améliorer la précision des résultats de recherche et l'efficacité de la publicité ciblée.
Pour Antonio Rangel, la suprématie du marché de Chrome transcende sa popularité. Il sert de passerelle vers l'écosystème de Google, influençant la manière dont les utilisateurs accèdent aux informations et aux services en ligne. L'intégration de Chrome avec la recherche Google, en tant que moteur de recherche par défaut, confère à Google un avantage significatif dans le contrôle du flux d'informations et de la publicité numérique.

Malgré la popularité de Google, Bing n'est pas un moteur de recherche inférieur. Cependant, de nombreux utilisateurs préfèrent Google en raison de la commodité de sa configuration par défaut et des biais cognitifs associés. Sur les appareils mobiles, les effets des moteurs de recherche par défaut sont plus importants en raison de la friction associée à leur modification ; jusqu'à 12 clics sont nécessaires pour modifier le moteur de recherche par défaut.

Cette préférence par défaut influence également les décisions en matière de confidentialité des consommateurs. Les paramètres de confidentialité par défaut de Google présentent un obstacle significatif pour ceux qui préfèrent une collecte de données plus limitée. Changer l'option par défaut nécessite la prise de conscience des alternatives disponibles, l'apprentissage des étapes nécessaires pour effectuer le changement et sa mise en œuvre, ce qui représente un obstacle considérable. De plus, des biais comportementaux tels que le statu quo et l'aversion à la perte incitent les utilisateurs à préférer maintenir les options par défaut de Google. J'explique tout cela plus en détail ici.
Le témoignage d'Antonio Rangel résonne directement avec les révélations de l'analyse interne de Google. Le document révèle que le paramétrage de la page d'accueil du navigateur a un impact significatif sur la part de marché des moteurs de recherche et le comportement des utilisateurs. Plus précisément, un pourcentage élevé d'utilisateurs ayant Google comme page d'accueil par défaut effectuent 50% de recherches supplémentaires sur Google par rapport à ceux qui ne l'ont pas.

Cela suggère une forte corrélation entre la page d'accueil par défaut et la préférence du moteur de recherche. De plus, l'influence de ce paramètre varie selon les régions, étant plus prononcée en Europe, au Moyen-Orient, en Afrique et en Amérique latine, et moins en Asie-Pacifique et en Amérique du Nord. L'analyse montre également que Google est moins vulnérable aux changements dans le paramètre de la page d'accueil par rapport à des concurrents comme Yahoo et MSN, qui pourraient subir des pertes importantes s'ils perdent ce paramètre.

Le paramétrage de la page d'accueil est identifié comme un outil stratégique clé pour Google, non seulement pour maintenir sa part de marché, mais aussi comme une vulnérabilité potentielle pour ses concurrents. De plus, cela met en évidence que la plupart des utilisateurs ne choisissent pas activement un moteur de recherche, mais se tournent vers l'accès par défaut fourni par leur paramétrage de page d'accueil. En termes économiques, une valeur vie client incrémentielle d'environ 3 $ par utilisateur est estimée pour Google lorsqu'il est défini comme page d'accueil.

Conclusion
Après avoir exploré les algorithmes et le fonctionnement interne de Google, nous avons constaté le rôle significatif que les clics des utilisateurs et les évaluateurs humains jouent dans le classement des résultats de recherche.
Clics, en tant qu'indicateurs directs des préférences des utilisateurs, sont essentiels pour que Google ajuste et améliore continuellement la pertinence et la précision de ses réponses. Bien que parfois ils pourraient vouloir le contraire lorsque les chiffres ne correspondent pas...
De plus, les évaluateurs humains apportent une couche cruciale d'évaluation et de compréhension qui, même à l'ère de l'intelligence artificielle, reste indispensable. Personnellement, je suis très surpris à ce stade, sachant que les évaluateurs étaient importants, mais pas à ce point.
Ces deux entrées combinées, le retour automatique via des clics et la supervision humaine, permettent à Google non seulement de mieux comprendre les requêtes de recherche, mais aussi de s'adapter aux tendances changeantes et aux besoins en information. Avec l'avancée de l'IA, il sera intéressant de voir comment Google continue à équilibrer ces éléments pour améliorer et personnaliser l'expérience de recherche dans un écosystème en constante évolution, avec un accent sur la confidentialité.
D'autre part, Chrome est bien plus qu'un navigateur ; c'est le composant essentiel de leur domination numérique. Sa synergie avec la recherche Google et son implémentation par défaut dans de nombreux domaines impactent la dynamique du marché et l'environnement numérique dans son ensemble. Nous verrons comment se termine le procès pour abus de position dominante, mais ils ont déjà dû payer environ 10 000 millions d'euros d'amendes depuis plus de 10 ans.