Récupération Augmentée Génération (RAG) est un terme surchargé. Il promet beaucoup, mais après avoir développé un pipeline RAG, beaucoup d'entre nous se demandent pourquoi cela ne fonctionne pas aussi bien que prévu.
Comme la plupart des outils, RAG est facile à utiliser mais difficile à maîtriser. La vérité est qu'il y a plus à RAG que de simplement mettre des documents dans une base de vecteurs et d'ajouter un LLM par-dessus. Cela peut fonctionner, mais ce n'est pas toujours le cas.
Cet ebook vise à vous dire quoi faire lorsque le RAG prêt à l'emploi ne fonctionne pas. Dans ce premier chapitre, nous verrons ce qui est souvent la solution la plus facile et la plus rapide à mettre en œuvre pour les pipelines RAG suboptimaux — nous allons apprendre à connaître les rerankers.
Vidéo complémentaire pour ce chapitre.
Fenêtres de rappel par rapport aux fenêtres contextuelles
Avant de nous plonger dans la solution, parlons du problème. Avec RAG, nous effectuons une recherche sémantique à travers de nombreux documents textuels, pouvant aller de dizaines de milliers à des dizaines de milliards de documents.
Pour garantir des temps de recherche rapides à grande échelle, nous utilisons généralement la recherche vectorielle. C'est-à-dire, nous transformons notre texte en vecteurs, les plaçons tous dans un espace vectoriel, et comparons leur proximité avec un vecteur de requête en utilisant une mesure de similarité comme la similarité cosinus.
Pour que la recherche vectorielle fonctionne, nous avons besoin de vecteurs. Ces vecteurs sont essentiellement des compressions du "sens" derrière un texte en vecteurs de 768 ou 1536 dimensions (typiquement). Il y a une perte d'information car nous compressons cette information en un seul vecteur.
En raison de cette perte d'informations, il arrive souvent que les trois premiers (par exemple) documents de recherche vectorielle ne contiennent pas les informations pertinentes. Malheureusement, la récupération peut renvoyer des informations pertinentes en dessous de notre seuil top_k.
Que faisons-nous si des informations pertinentes à une position inférieure pourraient aider notre LLM à formuler une meilleure réponse ? La méthode la plus simple est d'augmenter le nombre de documents que nous renvoyons (augmenter top_k) et de les transmettre tous au LLM.
La métrique que nous mesurerions ici est le rappel — ce qui signifie "combien de documents pertinents récupérons-nous". Le rappel ne prend pas en compte le nombre total de documents récupérés — nous pouvons donc manipuler la métrique et obtenir un rappel parfait en renvoyant tout.
rappel@K = \frac{#;de;documents;pertinents;retournés}{#;de;documents;pertinents;dans;l'ensemble;de;données}
Malheureusement, nous ne pouvons pas tout retourner. Les LLM ont des limites sur la quantité de texte que nous pouvons leur transmettre — nous appelons cette limite la fenêtre de contexte. Certains LLM ont de grandes fenêtres de contexte, comme Claude d'Anthropic, avec une fenêtre de contexte de 100 000 jetons [1"]. Avec cela, nous pourrions adapter de nombreuses dizaines de pages de texte — pourrions-nous donc retourner de nombreux documents (pas tout à fait tous) et "remplir" la fenêtre de contexte pour améliorer le rappel?
Encore une fois, non. Nous ne pouvons pas utiliser le contexte de remplissage car cela réduit les performances de rappel du LLM - notez que c'est le rappel du LLM, qui est différent du rappel de récupération dont nous avons discuté jusqu'à présent.
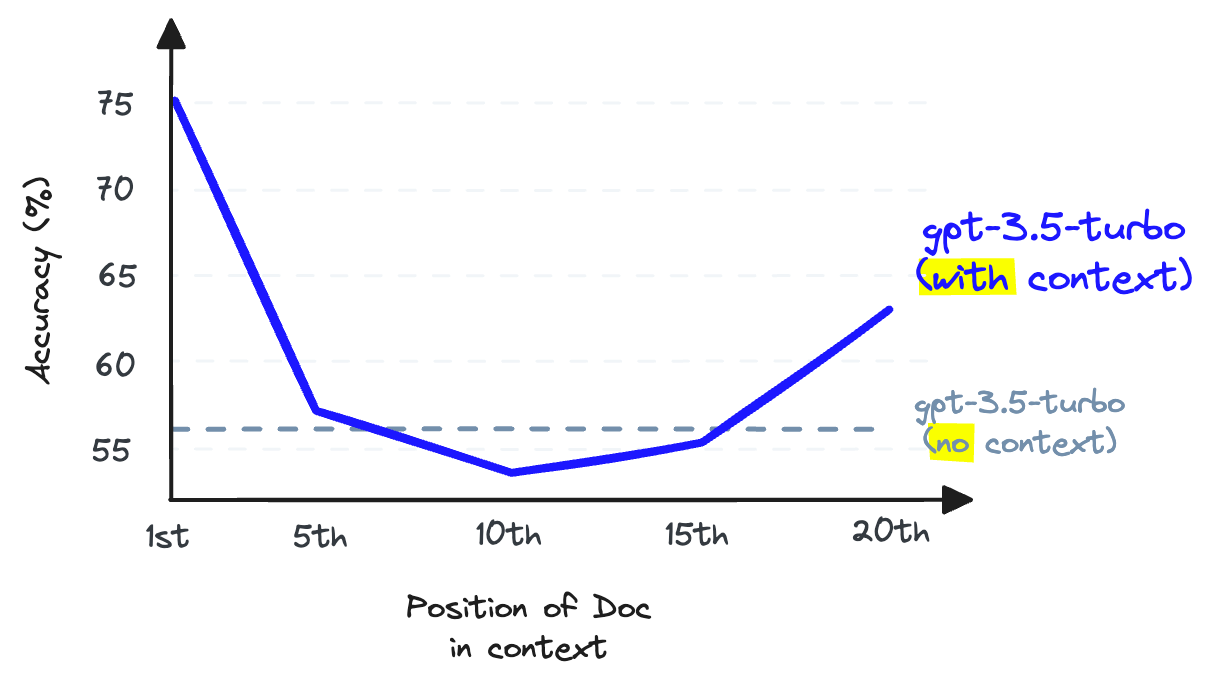
Lorsque l'information est stockée au milieu d'une fenêtre contextuelle, la capacité d'un LLM à se souvenir de cette information devient pire que si elle n'avait pas été fournie en premier lieu \[2\].
Le rappel de LLM fait référence à la capacité d'un LLM à trouver des informations dans le texte placé dans sa fenêtre contextuelle. Des recherches montrent que le rappel de LLM diminue lorsque nous ajoutons plus de jetons dans la fenêtre contextuelle [2]. Les LLM sont également moins susceptibles de suivre les instructions lorsque nous surchargeons la fenêtre contextuelle, donc surcharger le contexte est une mauvaise idée.
Nous pouvons augmenter le nombre de documents renvoyés par notre base de vecteurs pour augmenter le rappel de récupération, mais nous ne pouvons pas les transmettre à notre LLM sans endommager le rappel du LLM.
La solution à ce problème consiste à maximiser le rappel de récupération en récupérant un grand nombre de documents, puis à maximiser le rappel de LLM en minimisant le nombre de documents qui parviennent au LLM. Pour ce faire, nous réorganisons les documents récupérés et ne conservons que les plus pertinents pour notre LLM - pour ce faire, nous utilisons le reranking.
Puissance des réordonneurs
Un modèle de réordonnancement, également connu sous le nom de cross-encoder, est un type de modèle qui, étant donné une paire requête-document, produira un score de similarité. Nous utilisons ce score pour réorganiser les documents par pertinence par rapport à notre requête.
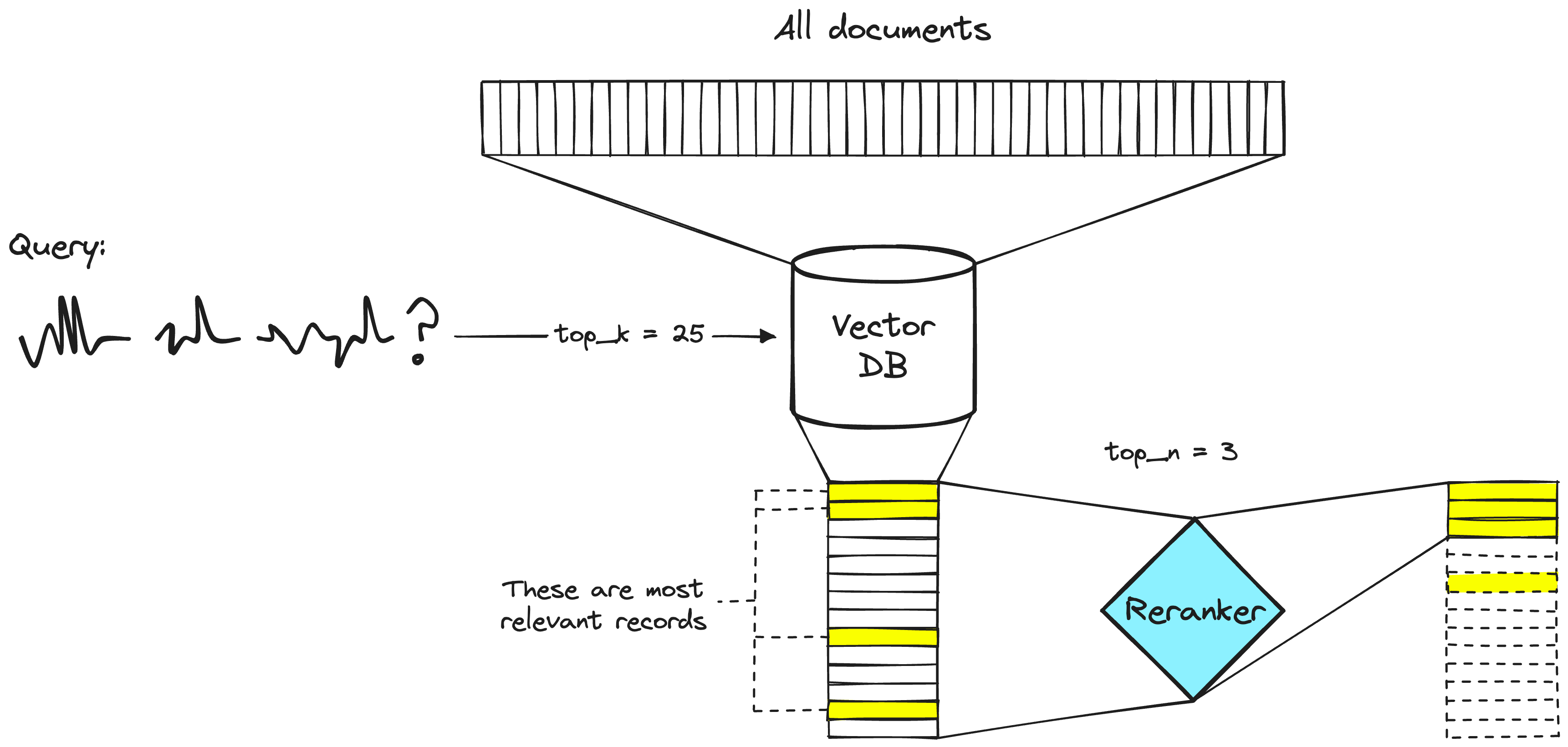
Un système de recherche à deux étapes. L'étape de la base de données vectorielle inclura généralement un modèle d'encodage bi-étage ou un modèle d'incorporation sparse.
Les ingénieurs de recherche utilisent des rerankers dans les systèmes de recherche à deux étapes depuis longtemps. Dans ces systèmes à deux étapes, un premier modèle (un modèle d'incorporation/recherche) récupère un ensemble de documents pertinents à partir d'un ensemble de données plus large. Ensuite, un deuxième modèle (le reranker) est utilisé pour réorganiser ces documents récupérés par le premier modèle.