Recuperación Aumentada Generación (RAG) es un término sobrecargado. Promete mucho, pero después de desarrollar un pipeline de RAG, muchos nos preguntamos por qué no funciona tan bien como esperábamos.
Como la mayoría de las herramientas, RAG es fácil de usar pero difícil de dominar. La verdad es que hay más en RAG que simplemente poner documentos en una base de datos vectorial y agregar un LLM encima. Eso puede funcionar, pero no siempre.
Este libro electrónico tiene como objetivo decirte qué hacer cuando el RAG predeterminado no funciona. En este primer capítulo, veremos cuál es a menudo la solución más fácil y rápida de implementar para tuberías RAG subóptimas: aprenderemos sobre rerankers.
Video complementario para este capítulo.
Recuperación vs. Ventanas de Contexto
Antes de adentrarnos en la solución, hablemos del problema. Con RAG, estamos realizando una búsqueda semántica en muchos documentos de texto, que podrían ser decenas de miles o incluso decenas de miles de millones de documentos.
Para garantizar tiempos de búsqueda rápidos a escala, normalmente utilizamos la búsqueda vectorial, es decir, transformamos nuestro texto en vectores, los colocamos todos en un espacio vectorial y comparamos su proximidad a un vector de consulta utilizando una métrica de similitud como la similitud del coseno.
Para que la búsqueda de vectores funcione, necesitamos vectores. Estos vectores son básicamente compresiones del 'significado' detrás de algún texto en vectores de (típicamente) 768 o 1536 dimensiones. Existe cierta pérdida de información debido a que estamos comprimiendo esta información en un solo vector.
Debido a esta pérdida de información, a menudo vemos que los tres principales (por ejemplo) documentos de búsqueda de vectores no incluirán información relevante. Desafortunadamente, la recuperación puede devolver información relevante por debajo de nuestro límite superior de k.
¿Qué hacemos si la información relevante en una posición más baja ayudaría a nuestro LLM a formular una mejor respuesta? El enfoque más sencillo es aumentar el número de documentos que estamos devolviendo (aumentar top_k) y pasarlos todos al LLM.
El indicador que mediríamos aquí es recall — lo que significa 'cuántos de los documentos relevantes estamos recuperando'. El recall no considera el número total de documentos recuperados — así que podemos manipular el indicador y obtener un recall perfecto devolviendo todo.
recall@K=# de documentos relevantes devueltos# de documentos relevantes en el conjunto de datosrecall@K = \frac{#;de;documentos;relevantes;devueltos}{#;de;documentos;relevantes;en;el;conjunto;de;datos}
Desafortunadamente, no podemos devolverlo todo. Los LLM tienen límites en la cantidad de texto que podemos pasarles, a esto lo llamamos la ventana de contexto. Algunos LLM tienen ventanas de contexto enormes, como Claude de Anthropic, con una ventana de contexto de 100K tokens [1]. Con eso, podríamos ajustar muchas decenas de páginas de texto, ¿podríamos devolver muchos documentos (casi todos) y 'llenar' la ventana de contexto para mejorar la recuperación?
Nuevamente, no. No podemos usar el relleno de contexto porque esto reduce el rendimiento de recuperación del LLM; tenga en cuenta que este es el recuerdo del LLM, que es diferente del recuerdo de recuperación que hemos estado discutiendo hasta ahora.
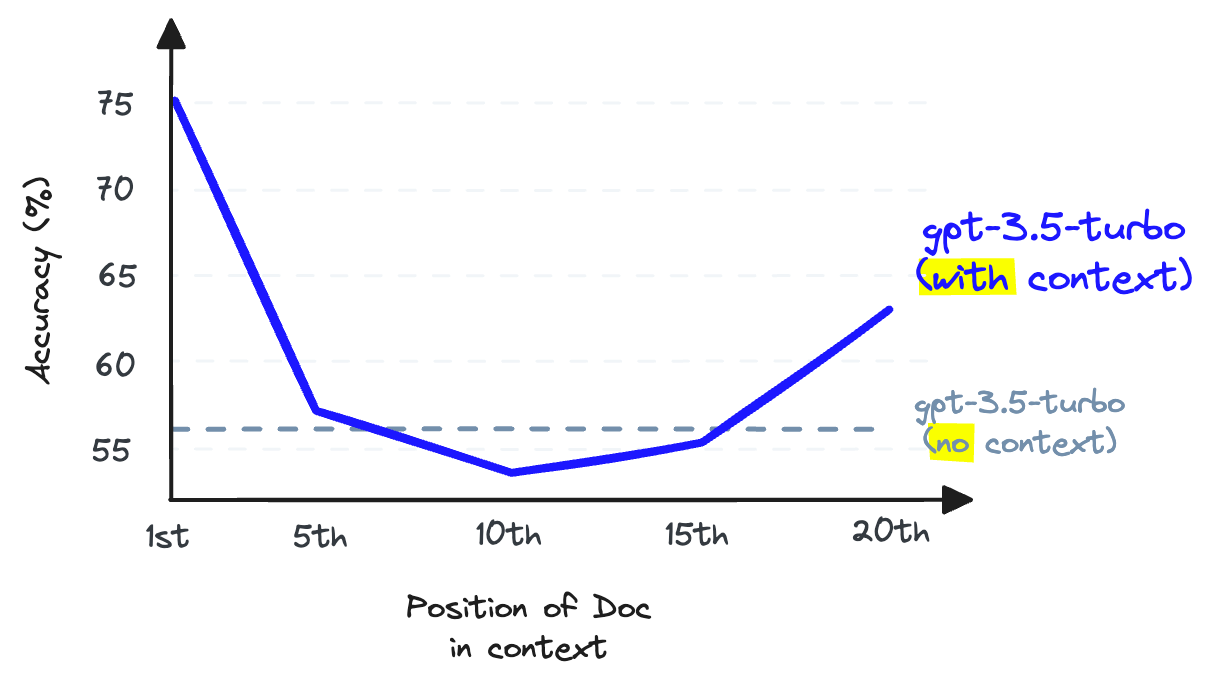
Cuando se almacena información en el medio de una ventana de contexto, la capacidad de recordar esa información de un LLM empeora en comparación con si no se hubiera proporcionado en primer lugar [2].
El recuerdo de LLM se refiere a la capacidad de un LLM para encontrar información del texto colocado dentro de su ventana de contexto. La investigación muestra que el recuerdo de LLM se degrada a medida que colocamos más tokens en la ventana de contexto [2]. Los LLM también son menos propensos a seguir instrucciones a medida que llenamos la ventana de contexto, por lo que rellenar el contexto es una mala idea.
Podemos aumentar el número de documentos devueltos por nuestra base de vectores para aumentar la recuperación, pero no podemos pasarlos a nuestro LLM sin dañar la recuperación del LLM.
La solución a este problema es maximizar la recuperación recordando al recuperar una gran cantidad de documentos y luego maximizar la recuperación de LLM al minimizar la cantidad de documentos que llegan al LLM. Para hacer eso, reordenamos los documentos recuperados y conservamos solo los más relevantes para nuestro LLM, para hacer eso, usamos reranking.
Poder de los reordenadores
Un modelo de reordenamiento, también conocido como un codificador cruzado, es un tipo de modelo que, dado un par de consulta y documento, producirá un puntaje de similitud. Utilizamos este puntaje para reordenar los documentos por relevancia a nuestra consulta.
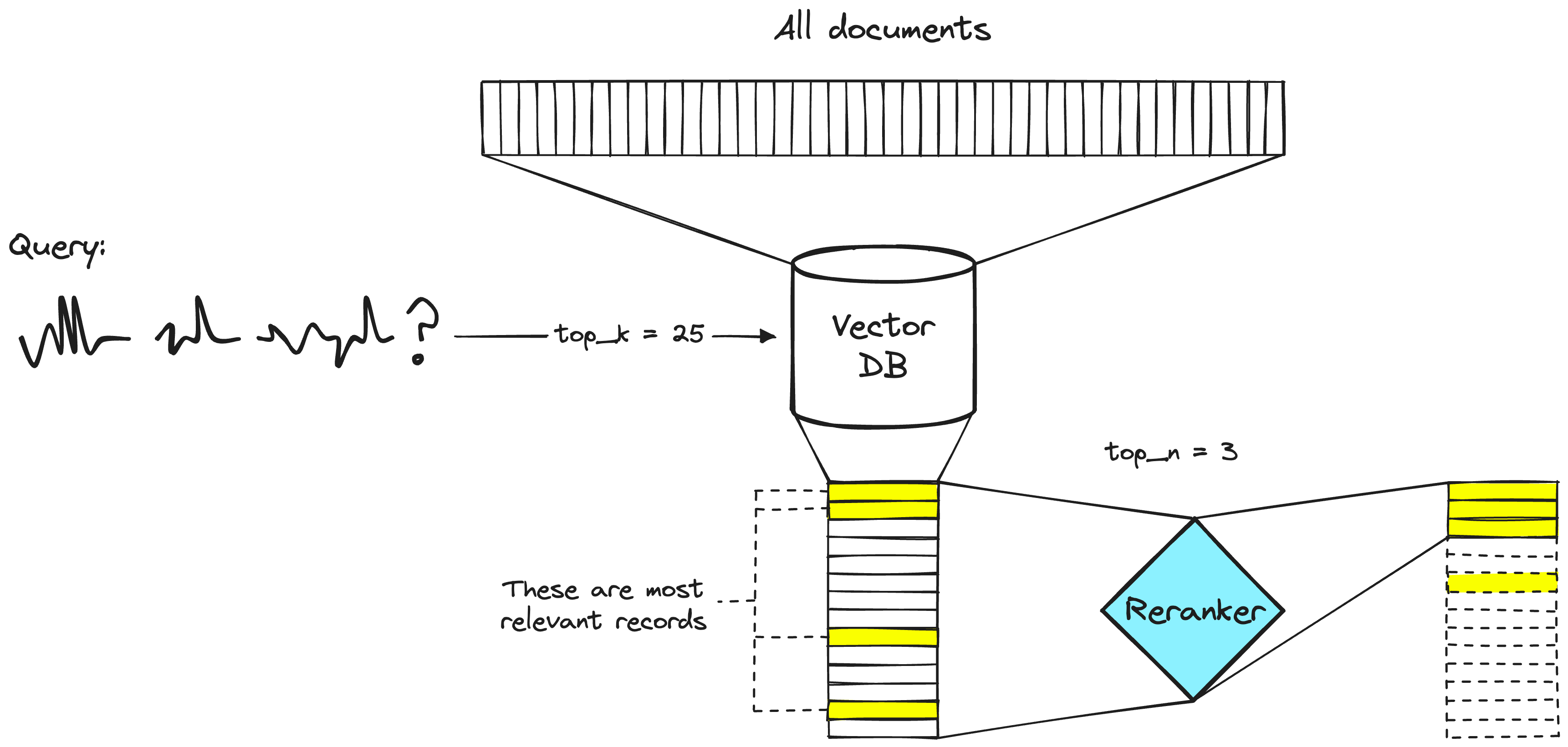
Un sistema de recuperación de dos etapas. El paso de la base de datos vectorial normalmente incluirá un modelo de bi-codificador o de incrustación dispersa.
Los ingenieros de búsqueda han utilizado rerankers en sistemas de recuperación de dos etapas durante mucho tiempo. En estos sistemas de dos etapas, un modelo de primera etapa (un modelo de incrustación/recuperador) recupera un conjunto de documentos relevantes de un conjunto de datos más grande. Luego, se utiliza un modelo de segunda etapa (el reranker) para volver a clasificar esos documentos recuperados por el modelo de primera etapa.
Usamos dos etapas porque recuperar un pequeño conjunto de documentos de un gran conjunto de datos es mucho más rápido que volver a clasificar un gran conjunto de documentos, discutiremos pronto por qué es el caso, pero en resumen, los reordenadores son lentos y los recuperadores son rápidos.
¿Por qué los reordenadores?
Si un reordenador es mucho más lento, ¿por qué molestarse en usarlo? La respuesta es que los reordenadores son mucho más precisos que los modelos de incrustación.
La intuición detrás de la precisión inferior de un bi-codificador es que los bi-codificadores deben comprimir todos los posibles significados de un documento en un solo vector, lo que significa que perdemos información. Además, los bi-codificadores no tienen contexto sobre la consulta porque no conocemos la consulta hasta que la recibimos (creamos incrustaciones antes del tiempo de consulta del usuario).
Por otro lado, un reranker puede recibir la información en bruto directamente en el cálculo del gran transformador, lo que significa menos pérdida de información. Debido a que estamos ejecutando el reranker en el momento de la consulta del usuario, tenemos el beneficio adicional de analizar el significado de nuestros documentos específicamente para la consulta del usuario, en lugar de intentar producir un significado genérico y promediado.
Los reordenadores evitan la pérdida de información de los biencoders, pero tienen una penalización diferente: el tiempo.
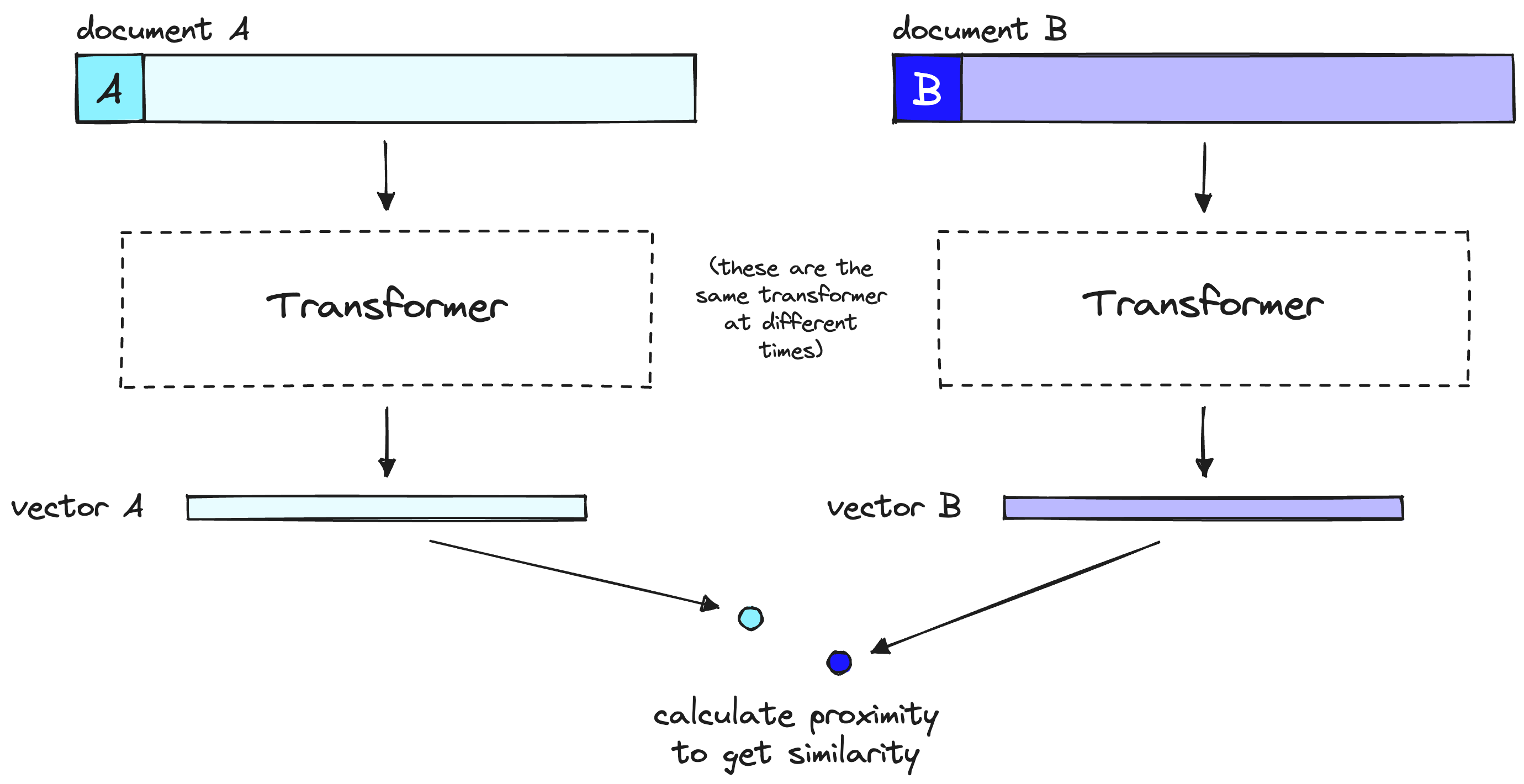
Un modelo bi-codificador comprime el significado del documento o la consulta en un solo vector. Tenga en cuenta que el bi-codificador procesa nuestra consulta de la misma manera que lo hace con los documentos, pero en el momento de la consulta del usuario.
Al utilizar modelos bi-codificador con búsqueda de vectores, adelantamos toda la computación pesada del transformador al momento de crear los vectores iniciales, lo que significa que cuando un usuario realiza consultas en nuestro sistema, ya hemos creado los vectores, por lo que todo lo que necesitamos hacer es:
- Ejecutar una sola computación del transformador para crear el vector de consulta.
- Comparar el vector de consulta con los vectores de documentos utilizando la similitud coseno (u otra métrica liviana).
Con los rerankers, no estamos precalculando nada. En cambio, estamos alimentando nuestra consulta y un solo otro documento en el transformador, ejecutando un paso completo de inferencia del transformador y produciendo un solo puntaje de similitud.
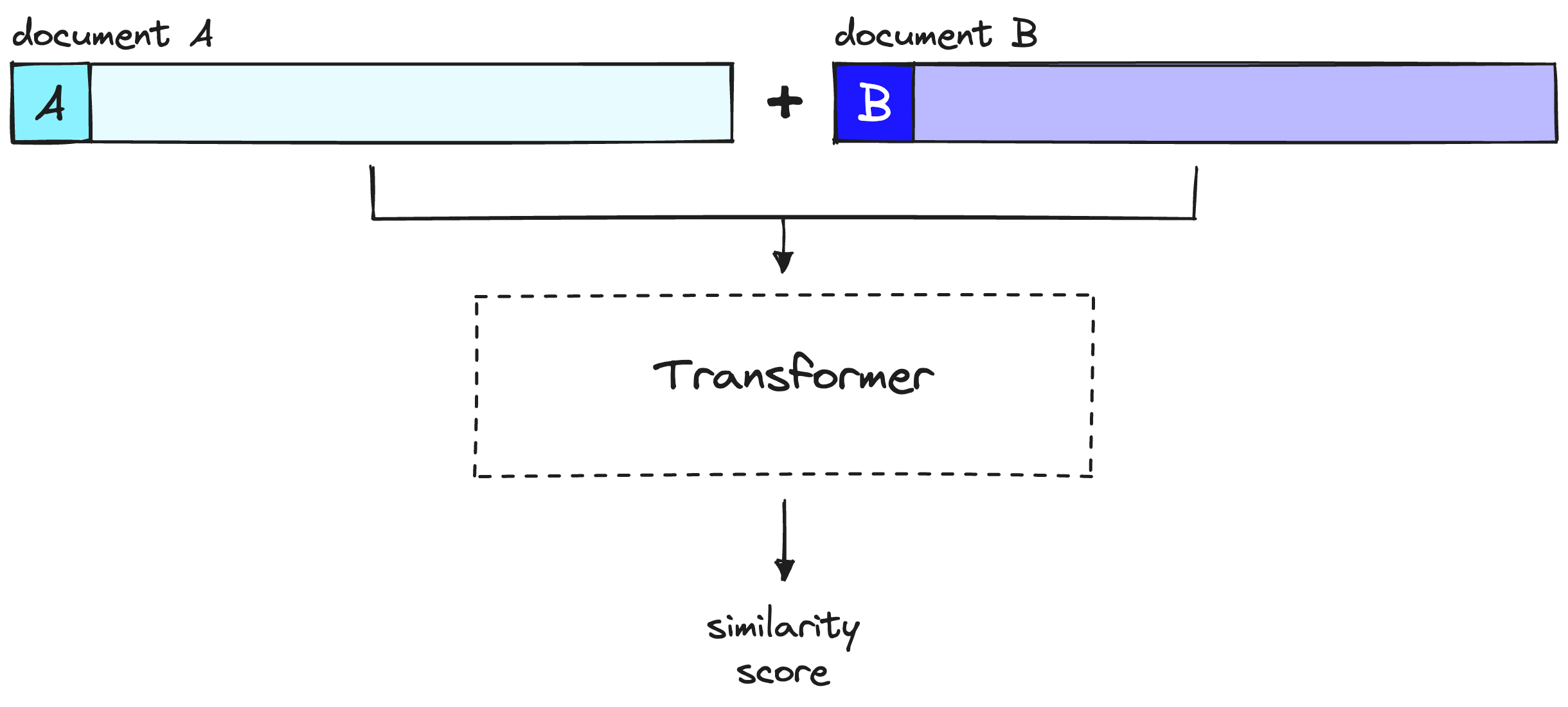
Un reranker considera la consulta y el documento para producir un solo puntaje de similitud durante un paso completo de inferencia del transformador. Tenga en cuenta que el documento A aquí es equivalente a nuestra consulta.
Dado 40 millones de registros, si usamos un modelo de reranking pequeño como BERT en una GPU V100, estaríamos esperando más de 50 horas para devolver un solo resultado de consulta [3]. Podemos hacer lo mismo en <100ms con modelos de codificación y búsqueda de vectores.
Implementación de la recuperación de dos etapas con reordenamiento
Ahora que entendemos la idea y la razón detrás de la recuperación de dos etapas con reordenadores, veamos cómo implementarlo (puedes seguirlo con este cuaderno. Para empezar, configuraremos nuestras bibliotecas previas:
!pip install -qU \
datasets==2.14.5 \
openai==0.28.1 \
pinecone-client==2.2.4 \
cohere==4.27
Preparación de datos
Antes de configurar el pipeline de recuperación, ¡necesitamos datos para recuperar! Utilizaremos el conjunto de datos jamescalam/ai-arxiv-chunked de Hugging Face Datasets. Este conjunto de datos contiene más de 400 artículos de ArXiv sobre ML, NLP y LLMs, incluidos los artículos de Llama 2, GPTQ y GPT-4.