This article is mainly "compiled" from Chapter 40 of the book Operating Systems: Three Easy Pieces. This is a very in-depth and easy-to-understand book, recommended for all students who feel confused about operating systems. This file system is based on a very small hard disk space, with data structures and read-write processes as the main line, deducing various basic links from scratch, which can help you quickly establish an intuition for the file system.
File systems are mostly built on top of block storage. However, some distributed file systems, such as JuiceFS, are based on object storage at the underlying level. Whether block storage or object storage, the essence is to address and exchange data in terms of 'data blocks'.
We will first explore the data structure, or layout, of a complete file system on the hard disk; then we will link various sub-modules together through the open-close, read-write processes to cover the key points of a file system.
Author: Woodbird's Miscellaneous Notes https://www.qtmuniao.com/2024/02/28/mini-filesystem Please indicate the source when reprinting
This article comes from my large-scale data system column "[System Daily Knowledge] (https://xiaobot.net/p/system-thinking)", focusing on storage, databases, distributed systems, AI Infra and computer basics. Welcome to subscribe and support to unlock more articles. Your support is my biggest motivation to move forward.

[](#Overall layout "Overall layout")Overall layout
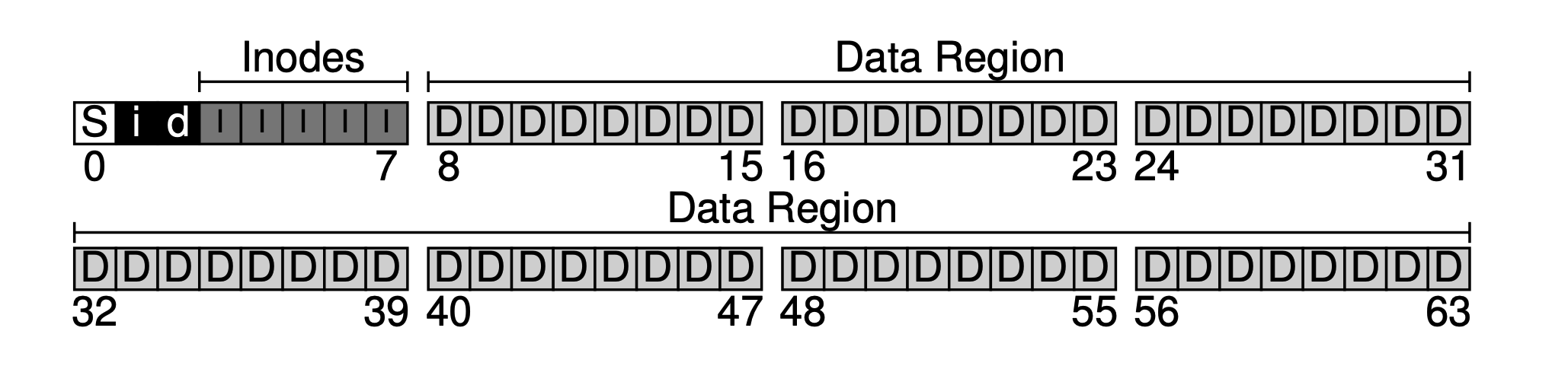
Assuming our block size is 4KB, and there is a very small hard disk with only 64 blocks (total size is 64 * 4KB = 256KB), and the hard disk is exclusively used by the file system. Since the hard disk is addressed by blocks, the address space is 0~63.
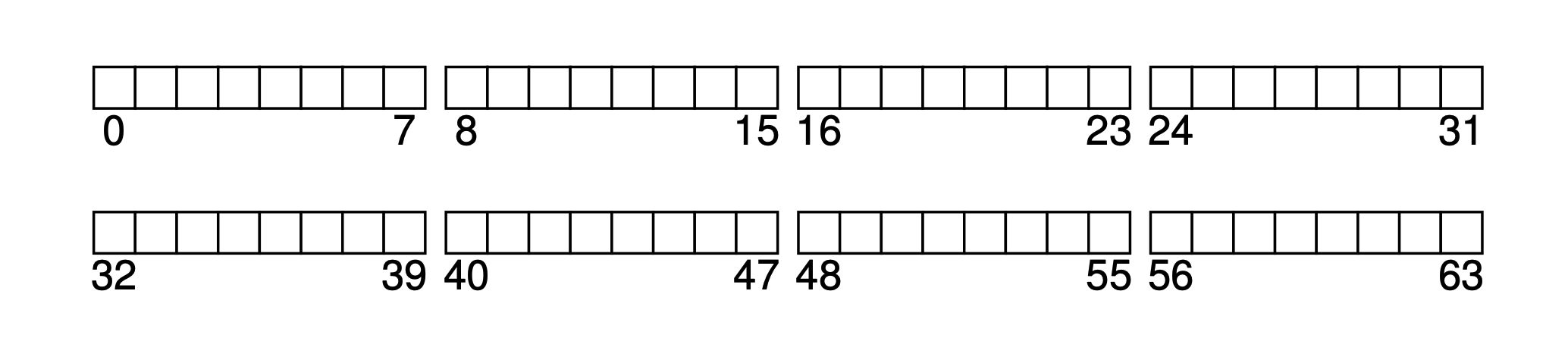
Based on this mini hard drive, let's gradually deduce this minimalist file system together.
The primary purpose of a file system is undoubtedly to store user data. For this, we reserve a Data Region on the disk. Let's assume we use the last 56 blocks as the data region. Why 56? As we will see later, this can actually be calculated - we can roughly calculate the ratio of metadata to actual data, and then determine the sizes of the two parts.
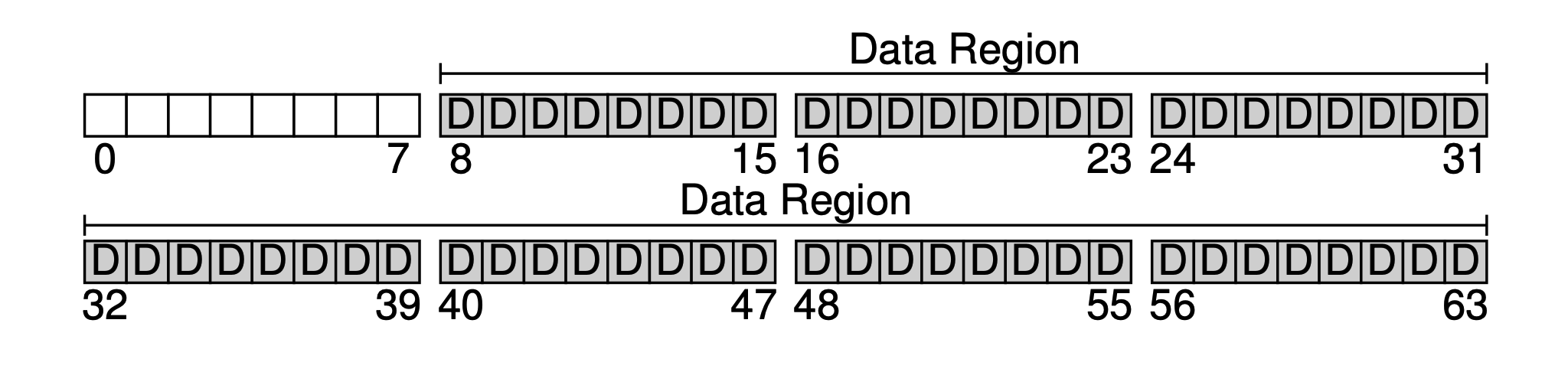
Next, we need to save some metadata for each file in the system, such as:
- File name
- File size
- File owner
- Access permissions
- Creation and modification time
Wait. The data block that stores this metadata is usually called an inode (index node). Below, we allocate 5 blocks to the inode.
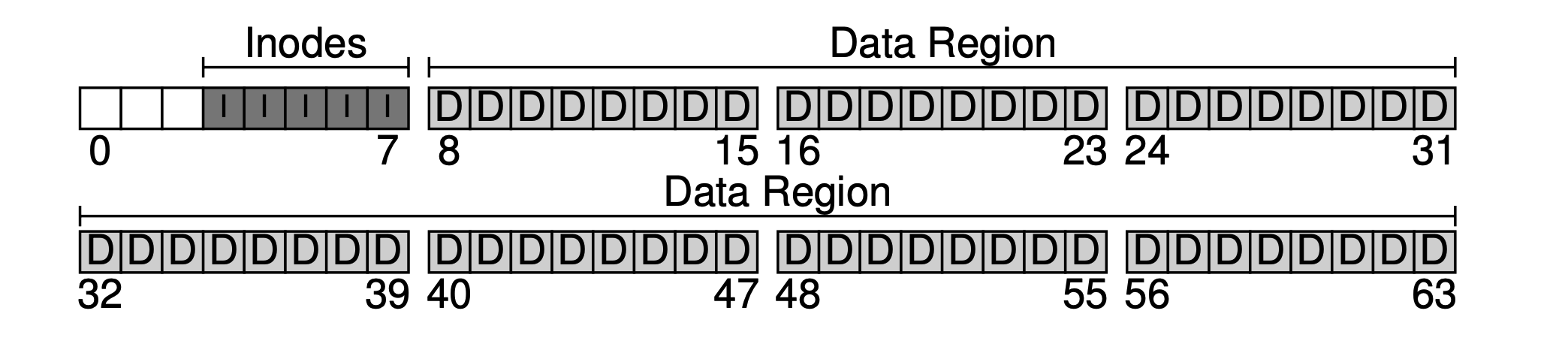
The metadata occupies a relatively small space, such as 128B or 256B. Here we assume that each inode occupies 256B. Then each 4KB block can accommodate 16 inodes, so our file system can support a maximum of 5 * 16 = 80 inodes, which means our mini file system can support a maximum of 80 files. However, since directories also occupy inodes, the actual number of available files is less than 80.
Now we have the data area and the file metadata area, but in a normally used file system, it is also necessary to track which data blocks are in use and which are not. This data structure is called the allocation structure. Common methods in the industry include the free list, which links all free blocks together in a linked list. However, for simplicity, a simpler data structure is used here: the bitmap. One is used for the data area, called the data bitmap; and one for the inode table, called the inode bitmap.
The idea of a bitmap is simple, using a data bit for each inode or data block to mark whether it is free: 0 for free, 1 for data. A 4KB bitmap can track up to 32K objects. For convenience, we allocate a complete block for the inode table and the data pool (although it is not fully used), resulting in the following diagram.
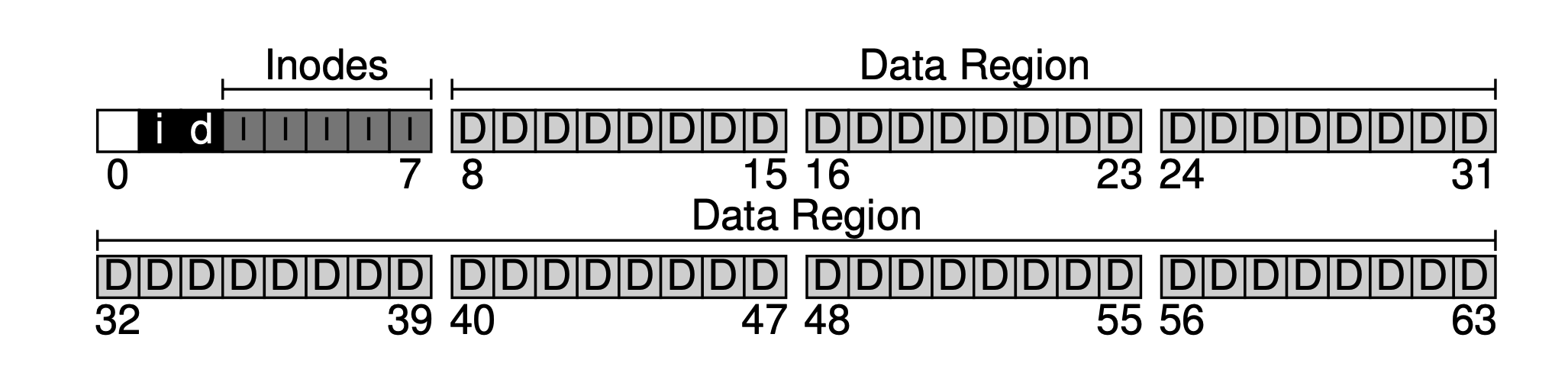
It can be seen that our basic approach is to lay out the data from back to front, leaving one block at the end. This block is intentionally left to serve as the superblock for the file system. The superblock, as an entry for a file system, typically holds some file system-level metadata, such as the number of inodes and data blocks in this file system (80 and 56), the starting block offset of the inode table (3), and so on.
When the file system is mounted, the operating system first reads the superblock (so it is placed at the beginning), initializes a series of parameters based on it, and mounts it as a data volume in the file system tree. With this basic information, when files in this volume are accessed, their locations can be gradually identified, which is the read-write process we will discuss later.
But before discussing the reading and writing process, we need to first take a closer look at the internal layout of some key data structures.
inode is the abbreviation of index node, which is the index node for files and folders. For simplicity, we use an array to organize the index nodes, and each inode will be associated with a number (inumber), which is its index (offset) in the array.
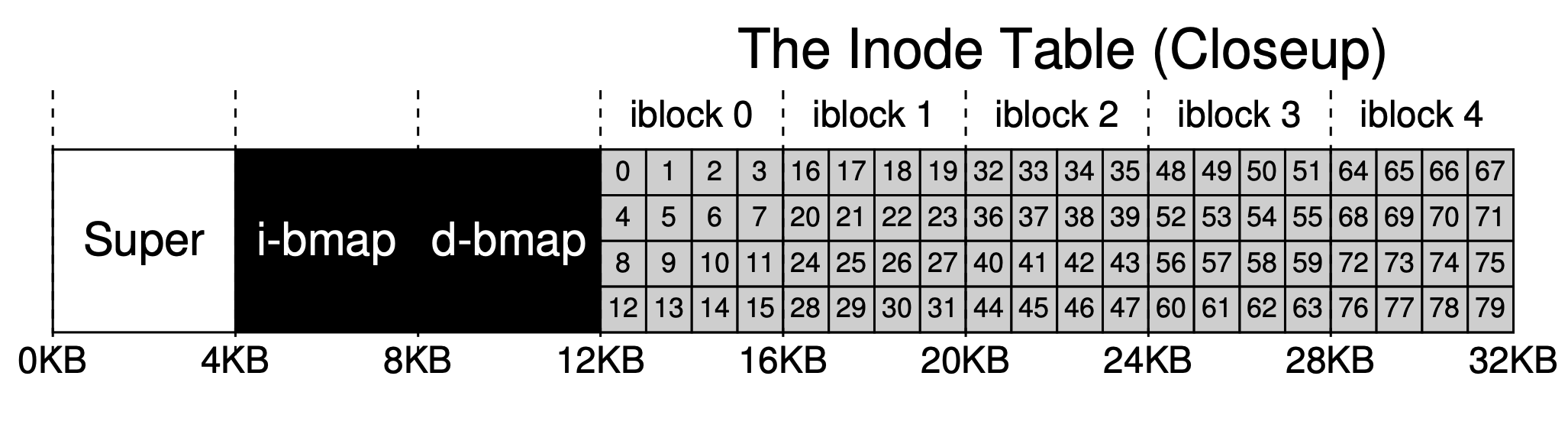
As mentioned earlier, each inode occupies 256B. Given an inumber, we can calculate its offset on the hard disk (12KB + inumber * 256), but due to the block-based nature of the internal and external storage exchange, we can further calculate the disk block it resides in based on this.
inode mainly stores the file name, some metadata (permission control, various events, some flags), and data block indexes. Data block indexes are actually metadata, but they are mentioned separately because they are very important.
我们使用一种比较简单的索引方式:间接指针(indirect pointer)。即 inode 中保存的不是直接指向数据块的指针,而是指向一个指针块(也在数据区分配,但保存的都是二级指针)。如果文件足够大,可能还会引出三级指针(至于我们这个小系统是否用的着,大家可以估算下)。
But we found that in most file systems, small files are the majority. How small? Small enough to fit into a single data block.

Therefore, in practice, we use a mixed approach of direct pointers and indirect pointers in the inode. In our file system, we use 12 direct pointers and 1 indirect pointer. So, as long as the file size does not exceed 12 data blocks, direct pointers can be used directly. Only when it is too large, indirect pointers are used, and new data blocks are allocated in the data area to store the indirect pointers.
Our data area is very small, with only 56 blocks. Assuming a 4-byte index, the secondary pointer can support a maximum of (12 + 1024)・4K, which is a file size of 4144KB.
Another commonly used method in practice is data segment (extents). That is, each continuous data area is represented by a starting pointer and size, and then all data segments of a file are strung together. However, when there are multiple data segments, the performance will be poor if you want to access the last data segment or perform random access (the pointer to the next data segment is stored in the previous data segment). In order to optimize access speed, the index chain of this data segment is often stored in memory. This is how the early Windows file system FAT operates.
In our file system, the directory is organized very simply—just like files, each directory also occupies an inode, but the data block pointed to by the inode does not store file content, but rather stores information about all the files and folders contained in that directory, usually represented as List<entry name, inode number>. Of course, it needs to be converted to actual encoding, and also store information such as file name length (because file names are variable in length).
Look at a simple example, suppose we have a folder dir (inode number is 5), inside which there are three files (foor, bar, and foobar), with corresponding inode numbers 12, 13, and 24. The information stored in the data blocks of this folder is as follows:

其中 reclen (record length)是文件名所占空间大小,strlen 是实际长度。点和点点是指向本文件夹和上级文件夹的两个指针。记录 reclen 看着有点多此一举,但要考虑到文件删除问题(可以用特殊的 inum,比如 0 来标记删除)。如果文件夹下的某个文件或者目录被删除,存储就会出现空洞。reclen 的存在,可以让删除留下的空洞为之后新增的文件复用。
It should be noted that organizing files in a directory in a linear manner is the simplest way. In practice, there are other methods. For example, in XFS, if there are a large number of files or subfolders in a directory, a B+ tree may be used for organization. This allows for quick determination of the existence of files with the same name during insertion.
When we need to create a new file or directory entry, we need to obtain a piece of available space from the file system. Therefore, it is very important to efficiently manage free space. We use two bitmaps for management, the advantage is simplicity, the disadvantage is that we have to linearly scan and search for all free bit positions every time, and we can only achieve block granularity. If there is remaining space within a block, it cannot be managed.
[](#Reading and Writing Paths)Reading and Writing Paths
Once we have a grasp of the data structures on the disk, we can then string together different data structures through the read and write processes. Assuming that the file system has been mounted: that is, the superblock has already been loaded into memory.
[](#Read file 'Read file') Read file
Our operation is very simple, just open a file (such as /foo/bar), read from it, and then close it. For simplicity, let's assume our file size occupies one block, which is 4k.
When initiating a system call open("/foo/bar", O RDONLY), the file system first needs to locate the inode corresponding to the file bar to obtain its metadata and data location information. But now we only have the file path, so what should we do?
答曰:Traverse down from the root directory. The inode number of the root directory is either stored in the superblock or hard-coded (e.g. 2, which is the starting point for most Unix file systems). In other words, it must be well known in advance.
So the file system loads the inode of the root directory from the hard disk into memory, then uses the pointers in the inode to locate its data blocks, and from there finds the 'foo' folder and its corresponding inode within all the subdirectories and folders. Recursively repeating this process, the final step of the open system call is to load the inode of 'bar' into memory, perform permission checks (comparing process user permissions and inode access control), allocate a file descriptor into the process's open file table, and return it to the user.
Once the file is opened, the system call read() can be initiated to actually read the data. When reading, it first finds the first block based on the file's inode information (unless the offset has been modified using lseek() before reading), and then reads. At the same time, some metadata of the inode may be changed, such as access time. Then, it updates the offset of the file descriptor in the process, continues reading down until at some point, the close() call closes the file descriptor in the process.
When a process closes a file, much less work is required, only the file descriptor needs to be released, and there will be no actual disk IO.
Finally, let's go over the process of reading files again. Starting from the inode number of the root directory, we alternately read the inode and the corresponding data block until we finally find the file to be searched. Then we need to read the data, update its inode's access time and other metadata, and write it back. The table below briefly summarizes this process. It can be seen that the entire reading path does not involve the allocation structure - data bitmap and inode bitmap.
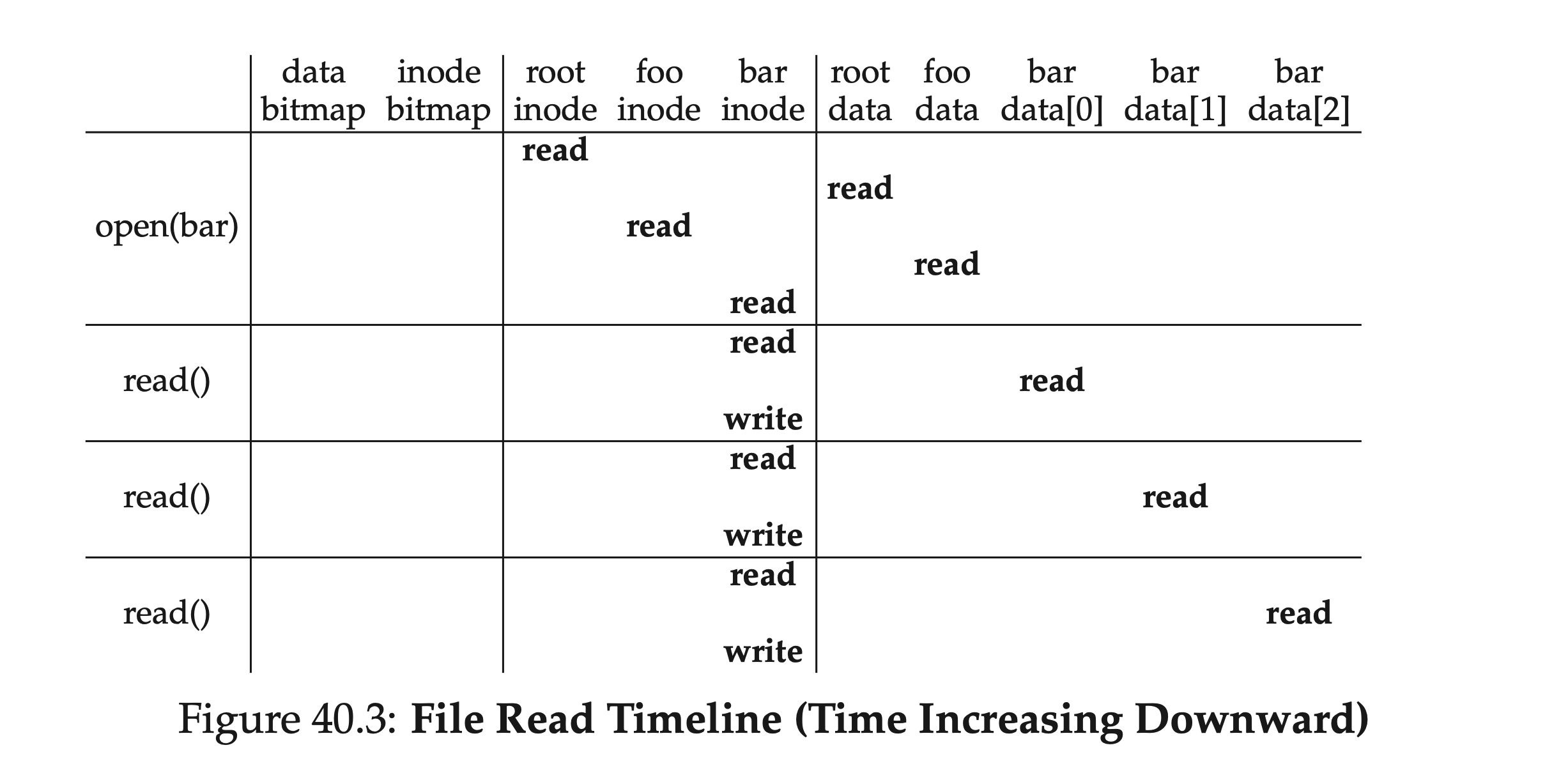
From a depth perspective, if our search path has many levels, this process will grow linearly; from a breadth perspective, if the folders involved in the intermediate search contain a large number of directory sub-items, i.e., the file tree is 'very wide', then each search in the directory may require reading more than one data block.
[](#Write to Disk "Write to Disk") Write to Disk
The process of writing files is very similar to reading files, which involves opening the file (finding the corresponding file from the root directory), then starting the writing process, and finally closing it. However, unlike reading files, writing requires allocating new data blocks, which involves our previous bitmap. Typically, writing requires at least five IO operations at a time:
- Read data bitmap (to find free blocks and mark them as used in memory)
- Write back data bitmap (to make it visible to other processes)
- Read inode (to add new data location pointers)
- Write back inode
- Write data into the found free block
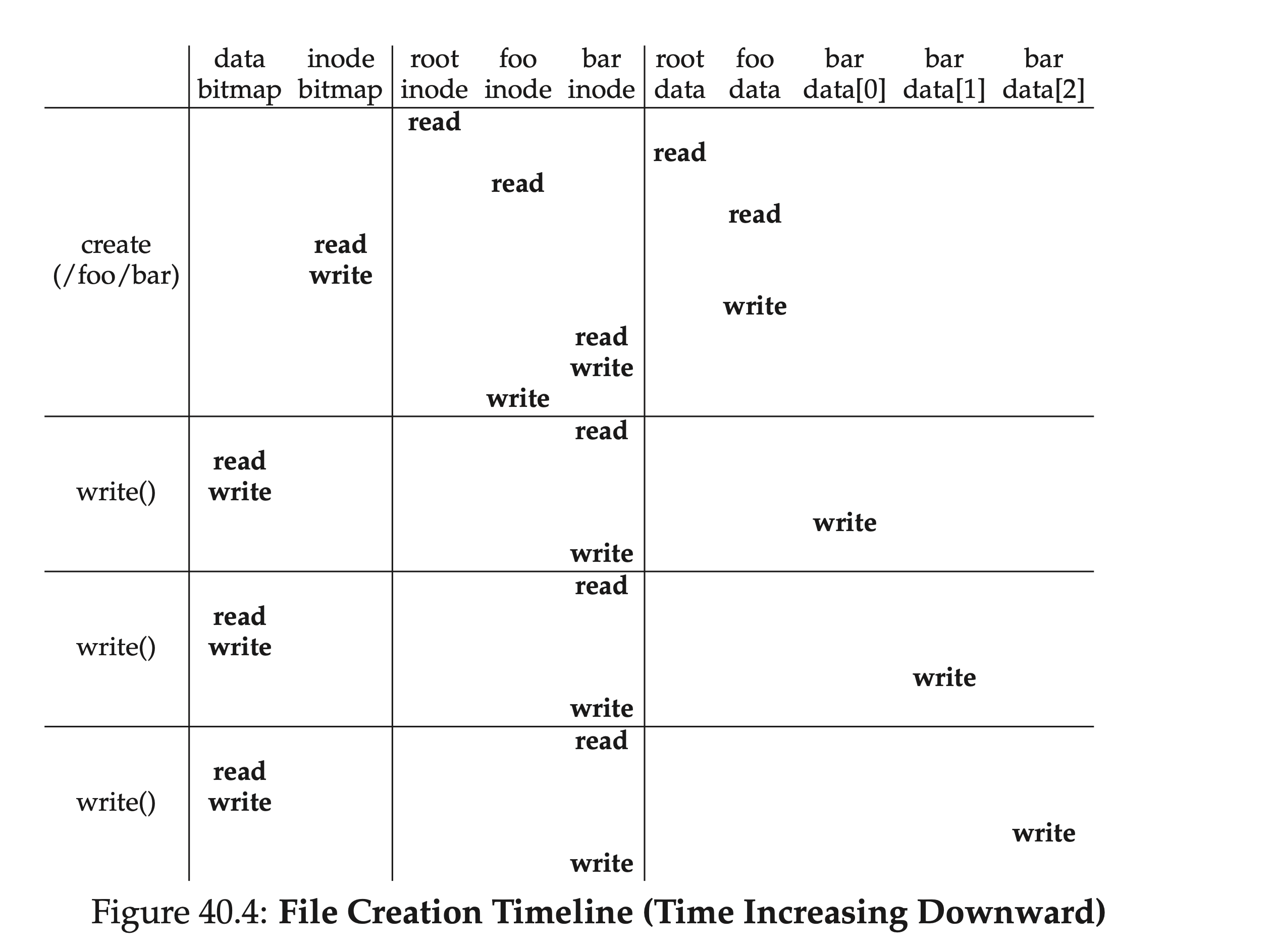
This is just writing to existing files. If it is to create and write to non-existent files, the process will be more complex: it will also create an inode, which will introduce a series of new IO operations:
- Read the inode bitmap once (find a free inode)
- Write back to the inode bitmap once (mark a certain inode as occupied)
- Write to the inode itself once (initialize)
- Read and write the directory entry data block corresponding to the parent folder once (add new files and inodes)
- Read and write the parent folder's inode once (update modification date)
If the data blocks of the parent folder are not enough, new space needs to be allocated, which requires reading the data bitmap and data blocks. The following diagram shows the I/O involved in the timeline of creating the /foo/bar file:
[](#Cache and Buffer "Cache and Buffer")Cache and Buffer
From the analysis of the read and write processes above, it can be seen that even such simple read and write operations involve a large amount of I/O, which is unacceptable in practice. To solve this problem, most industrial file systems make full use of memory to cache important (i.e., frequently accessed) data blocks in memory; at the same time, to avoid frequent disk flushing, modifications are first applied to the memory buffer and then accumulated before being written to disk.
Early file systems introduced fixed-size cache. If the cache is full, it will use replacement algorithms such as LRU for page eviction. Its drawback is the waste of space when the cache is not full and the potential for frequent page swapping when it is full. We refer to this style as static partitioning. Most modern file systems use dynamic partitioning techniques. For example, placing virtual memory pages and file system pages in a pool, known as unified page cache, allows for more flexible allocation and utilization. Once cached, subsequent reads of multiple files in the same directory can save a lot of I/O operations.
When writing processes, we can benefit from caching by using a writing buffering to delay flushing to disk. Delaying flushing to disk has many benefits, such as possibly needing to flush the bitmap only once for multiple modifications, improving IO bandwidth utilization by accumulating a batch of changes, and potentially avoiding flushing altogether if the file grows and then shrinks.
But these performance improvements come at a cost — unexpected crashes may lead to data loss. Therefore, while most modern file systems have enabled read-write caching, they also allow users to bypass the cache and write directly to the disk through direct I/O. Applications sensitive to data loss can utilize the corresponding system call fsync() to flush the disk immediately.
At this point, we have completed the implementation of a minimalist file system. Although small, it encompasses all the essential elements, from which we can observe some basic principles of file system design:
- Use inode to store file granularity metadata; use data blocks to store actual file data
- A directory is a special type of file, except it does not store file content, but rather subdirectory entries
- In addition to inodes and data blocks, some other data structures are needed, such as bitmaps to track free blocks
Starting from this basic file system, we can actually see a lot of points that can be chosen and optimized. If interested, everyone can build on this article and take a look at the design of some industrial file systems.