In diesem Artikel gehen wir auf die inneren Arbeitsweisen von Google ein, einem Werkzeug, das wir alle täglich nutzen, aber nur wenige wirklich verstehen. Nach dem kürzlichen Leak von Dokumenten in einer Kartellklage gegen Google haben wir die einzigartige Gelegenheit, die Algorithmen von Google zu erkunden. Einige dieser Algorithmen waren bereits bekannt, aber interessant ist die interne Information, die uns nie mitgeteilt wurde.
Wir werden untersuchen, wie diese Technologien unsere Suchanfragen verarbeiten und die Ergebnisse bestimmen, die wir sehen. In dieser Analyse möchte ich einen klaren und detaillierten Einblick in die komplexen Systeme hinter jeder Google-Suche bieten.
Darüber hinaus werde ich versuchen, die Architektur von Google in einem Diagramm darzustellen, unter Berücksichtigung neuer Entdeckungen.
Zunächst werden wir uns darauf konzentrieren, alle in 2 Dokumenten erwähnten Algorithmen zu extrahieren. Das erste befasst sich mit der Aussage von Pandu Nayak (VP von Alphabet) und das zweite mit Professor Douglas W. Oards Widerlegungsaussage zu den von Googles Experten, Prof. Edward A. Fox, in seinem am 3. Juni 2022 datierten Bericht geäußerten Meinungen. In letzterem Dokument wurde der berühmte und kontroverse „Fox-Bericht“ diskutiert, in dem Google experimentelle Daten manipuliert hat, um zu versuchen zu zeigen, dass Benutzerdaten für sie nicht so wichtig sind.
Ich werde versuchen, jeden Algorithmus basierend auf offiziellen Informationen zu erklären, sofern verfügbar, und dann die aus dem Versuch extrahierten Informationen in einem Bild darstellen.

Navboost
Es ist entscheidend für Google und einer der wichtigsten Faktoren. Dies kam auch im 2019 „Project Veritas“-Leak heraus, weil Paul Haar es seinem Lebenslauf hinzugefügt hat.

Navboost sammelt Daten darüber, wie Benutzer mit Suchergebnissen interagieren, insbesondere durch ihre Klicks auf verschiedene Abfragen. Dieses System tabelliert Klicks und verwendet Algorithmen, die aus von Menschen erstellten Qualitätsbewertungen lernen, um das Ranking der Ergebnisse zu verbessern. Die Idee ist, dass ein Ergebnis, das häufig (und positiv bewertet) für eine bestimmte Abfrage ausgewählt wird, wahrscheinlich ein höheres Ranking haben sollte. Interessanterweise hat Google vor vielen Jahren mit dem Entfernen von Navboost experimentiert und festgestellt, dass sich die Ergebnisse verschlechterten.

RankBrain
Gestartet im Jahr 2015, RankBrain ist ein Google KI- und maschinelles Lernsystem, das bei der Verarbeitung von Suchergebnissen unverzichtbar ist. Durch maschinelles Lernen verbessert es kontinuierlich seine Fähigkeit, Sprache und die Absichten hinter Suchanfragen zu verstehen, und ist besonders effektiv bei der Interpretation mehrdeutiger oder komplexer Anfragen. Es soll nach Inhalten und Links der drittwichtigste Faktor für das Ranking bei Google geworden sein. Es verwendet eine Tensor Processing Unit (TPU), um seine Verarbeitungsfähigkeit und Energieeffizienz signifikant zu verbessern.

Ich schließe daraus, dass QBST und Term Weighting Bestandteile von RankBrain sind. Also nehme ich sie hier mit auf.
QBST (Query Based Salient Terms) konzentriert sich auf die wichtigsten Begriffe innerhalb einer Abfrage und zugehöriger Dokumente, um auf diese Weise die Rangfolge der Ergebnisse zu beeinflussen. Dies bedeutet, dass die Suchmaschine schnell die wichtigsten Aspekte einer Benutzerabfrage erkennen und relevante Ergebnisse priorisieren kann. Dies ist beispielsweise besonders nützlich bei mehrdeutigen oder komplexen Abfragen.
Im Zeugnisdokument wird QBST im Zusammenhang mit den Einschränkungen von BERT erwähnt. Die spezifische Erwähnung besagt, dass «BERT keine großen Memorisationssysteme wie navboost, QBST usw. subsumiert.» Das bedeutet, dass obwohl BERT äußerst effektiv im Verstehen und Verarbeiten natürlicher Sprache ist, es bestimmte Einschränkungen hat, eine davon ist die Fähigkeit, große Memorisationssysteme wie QBST zu handhaben oder zu ersetzen.

Termgewichtung passt die relative Bedeutung einzelner Begriffe innerhalb einer Abfrage an, basierend darauf, wie Benutzer mit den Suchergebnissen interagieren. Dies hilft dabei zu bestimmen, wie relevant bestimmte Begriffe im Kontext der Abfrage sind. Diese Gewichtung behandelt auch effizient Begriffe, die in der Datenbank der Suchmaschine sehr häufig oder sehr selten vorkommen, und gleicht somit die Ergebnisse aus.

DeepRank
Geht einen Schritt weiter im Verständnis natürlicher Sprache, was es der Suchmaschine ermöglicht, die Absicht und den Kontext von Anfragen besser zu verstehen. Dies wird dank BERT erreicht; tatsächlich ist DeepRank der interne Name für BERT. Durch das Vor-Training an einer großen Menge von Dokumentendaten und Anpassung mit Rückmeldungen von Klicks und menschlichen Bewertungen kann DeepRank die Suchergebnisse feinabstimmen, um intuitiver und relevanter für das zu sein, wonach die Benutzer tatsächlich suchen.

RankEmbed
RankEmbed konzentriert sich wahrscheinlich auf die Aufgabe, relevante Merkmale für das Ranking einzubetten. Obwohl es in den Dokumenten keine spezifischen Details zu seiner Funktion und seinen Fähigkeiten gibt, können wir daraus schließen, dass es sich um ein Deep-Learning-System handelt, das darauf ausgelegt ist, den Suchklassifizierungsprozess von Google zu verbessern.
RankEmbed-BERT
RankEmbed-BERT ist eine verbesserte Version von RankEmbed, die den Algorithmus und die Struktur von BERT integriert. Diese Integration wurde durchgeführt, um die Sprachverständnisfähigkeiten von RankEmbed signifikant zu verbessern. Die Wirksamkeit kann abnehmen, wenn sie nicht mit aktuellen Daten neu trainiert wird. Für das Training wird nur ein kleiner Teil des Datenverkehrs verwendet, was darauf hindeutet, dass es nicht notwendig ist, alle verfügbaren Daten zu verwenden.
RankEmbed-BERT trägt zusammen mit anderen Deep-Learning-Modellen wie RankBrain und DeepRank zum endgültigen Ranking-Score im Suchsystem von Google bei, würde jedoch nach der anfänglichen Ergebnisabfrage (Neu-Ranking) arbeiten. Es wird anhand von Klick- und Abfragedaten trainiert und feinabgestimmt, wobei Daten von menschlichen Evaluatoren (IS) verwendet werden, und ist aufwändiger in der Trainingsberechnung als Feedforward-Modelle wie RankBrain.

MUM
Es ist etwa 1.000 Mal leistungsstärker als BERT und stellt einen bedeutenden Fortschritt in der Google-Suche dar. Im Juni 2021 gestartet, versteht es nicht nur 75 Sprachen, sondern ist auch multimodal, was bedeutet, dass es Informationen in verschiedenen Formaten interpretieren und verarbeiten kann. Diese multimodale Fähigkeit ermöglicht es MUM, umfassendere und kontextbezogene Antworten zu bieten, was den Bedarf an mehreren Suchvorgängen zur Erlangung detaillierter Informationen reduziert. Allerdings ist sein Einsatz aufgrund des hohen Rechenaufwands sehr selektiv.

Tangram und Kleber
Alle diese Systeme arbeiten innerhalb des Rahmens von Tangram zusammen, das dafür verantwortlich ist, die SERP mit Daten aus Glue zusammenzustellen. Es geht nicht nur darum, Ergebnisse zu ranken, sondern sie auf eine Art und Weise zu organisieren, die für Benutzer nützlich und zugänglich ist, unter Berücksichtigung von Elementen wie Bildkarussells, direkten Antworten und anderen nicht-textuellen Elementen.

Schließlich sorgen Freshness Node und Instant Glue dafür, dass die Ergebnisse aktuell sind und mehr Gewicht auf aktuelle Informationen legen, was besonders wichtig bei der Suche nach Nachrichten oder aktuellen Ereignissen ist.

Im Prozess wird Bezug auf den Angriff in Nizza genommen, bei dem die Hauptintention der Abfrage am Tag des Angriffs geändert wurde, was dazu führte, dass Instant Glue allgemeine Bilder zu Tangram unterdrückte und stattdessen relevante Nachrichten und Fotos aus Nizza förderte («schöne Bilder» vs. «Nice pictures»):

Mit all dem würde Google diese Algorithmen kombinieren, um:
- Verstehen der Abfrage: Entschlüsseln der Absicht hinter den Worten und Phrasen, die Benutzer in die Suchleiste eingeben.
- Relevanz bestimmen: Die Ergebnisse basierend darauf, wie gut sie zur Abfrage passen, anhand von Signalen aus vergangenen Interaktionen und Qualitätsbewertungen einstufen.
- Frische priorisieren: Sicherstellen, dass die aktuellsten und relevantesten Informationen bei Bedarf in den Rankings steigen.
- Ergebnisse personalisieren: Die Suchergebnisse nicht nur an die Abfrage, sondern auch an den Kontext des Benutzers anpassen, wie z.B. deren Standort und das verwendete Gerät. Es gibt kaum mehr Personalisierung als diese.
Von allem, was wir bisher gesehen haben, glaube ich, dass Tangram, Glue und RankEmbed-BERT die einzigen neuen Elemente sind, die bisher durchgesickert sind.
Wie wir gesehen haben, werden diese Algorithmen von verschiedenen Metriken genährt, die wir nun erneut aufschlüsseln werden, um Informationen aus dem Versuch zu extrahieren.
Metriken, die von Google zur Bewertung der Suchqualität verwendet werden
In diesem Abschnitt werden wir uns erneut auf das Widerlegungszeugnis von Professor Douglas W. Oard konzentrieren und Informationen aus einem früheren Leak, dem „Project Veritas“-Leak, einbeziehen.
In einer der Folien wurde gezeigt, dass Google die folgenden Metriken verwendet, um die Faktoren zu entwickeln und anzupassen, die sein Algorithmus bei der Bewertung von Suchergebnissen berücksichtigt, und um zu überwachen, wie sich Änderungen an seinem Algorithmus auf die Qualität der Suchergebnisse auswirken. Das Ziel ist, zu versuchen, die Absicht des Benutzers mit ihnen zu erfassen.
1. IS Score
Menschliche Evaluatoren spielen eine entscheidende Rolle bei der Entwicklung und Verfeinerung der Suchprodukte von Google. Durch ihre Arbeit wird die Metrik namens „IS-Score“ (Information Satisfaction Score im Bereich von 0 bis 100) generiert, abgeleitet von den Bewertungen der Evaluatoren und als primärer Indikator für Qualität bei Google verwendet.
Es wird anonym bewertet, wobei die Bewerter nicht wissen, ob sie Google oder Bing testen, und es wird verwendet, um die Leistung von Google mit seinem Hauptkonkurrenten zu vergleichen.
Diese IS-Werte spiegeln nicht nur die wahrgenommene Qualität wider, sondern werden auch zur Schulung verschiedener Modelle innerhalb des Suchsystems von Google verwendet, einschließlich Klassifizierungsalgorithmen wie RankBrain und RankEmbed BERT.
Gemäß den Dokumenten verwenden sie bis 2021 IS4. IS4 wird als eine Annäherung an die Nützlichkeit für den Benutzer betrachtet und sollte entsprechend behandelt werden. Es wird als möglicherweise wichtigste Ranglistenmetrik beschrieben, wobei jedoch betont wird, dass es sich um eine Annäherung handelt und anfällig für Fehler ist, über die wir später sprechen werden.

Eine Ableitung dieses Maßes, das IS4@5, wird ebenfalls erwähnt.
Die IS4@5-Metrik wird von Google zur Messung der Qualität von Suchergebnissen verwendet, wobei der Fokus speziell auf den ersten fünf Positionen liegt. Diese Metrik umfasst sowohl spezielle Suchfunktionen wie OneBoxes (auch bekannt als „blaue Links“). Es gibt eine Variante dieser Metrik namens IS4@5 Web, die sich ausschließlich auf die Bewertung der ersten fünf Web-Ergebnisse konzentriert und andere Elemente wie Werbung in den Suchergebnissen ausschließt.

Obwohl IS4@5 nützlich ist, um schnell die Qualität und Relevanz der Top-Ergebnisse einer Suche zu bewerten, ist ihr Anwendungsbereich begrenzt. Sie deckt nicht alle Aspekte der Suchqualität ab und lässt insbesondere Elemente wie Werbung in den Ergebnissen außen vor. Daher bietet die Metrik nur einen teilweisen Blick auf die Suchqualität. Für eine vollständige und genaue Bewertung der Qualität der Google-Suchergebnisse ist es notwendig, eine breitere Palette von Metriken und Faktoren zu berücksichtigen, ähnlich wie bei der Beurteilung der allgemeinen Gesundheit anhand einer Vielzahl von Indikatoren und nicht nur anhand des Gewichts.
**Beschränkungen von menschlichen Evaluatoren
Evaluatoren stehen vor mehreren Problemen, wie zum Beispiel dem Verstehen technischer Anfragen oder der Beurteilung der Beliebtheit von Produkten oder Interpretationen von Anfragen. Darüber hinaus könnten Sprachmodelle wie MUM in Zukunft Sprache und globales Wissen ähnlich wie menschliche Evaluatoren verstehen, was sowohl Chancen als auch Herausforderungen für die Zukunft der Relevanzbewertung darstellt.
Trotz ihrer Bedeutung unterscheidet sich ihre Perspektive erheblich von der realer Benutzer. Evaluatoren können über spezifisches Wissen oder frühere Erfahrungen verfügen, die Benutzer möglicherweise zu einem Abfrage-Thema haben, was potenziell ihre Bewertung der Relevanz und die Qualität der Suchergebnisse beeinflusst.
Aus geleakten Dokumenten aus den Jahren 2018 und 2021 konnte ich eine Liste aller Fehler erstellen, die Google in ihren internen Präsentationen erkennt.
- Zeitliche Diskrepanzen: Unterschiede können auftreten, weil Anfragen, Bewertungen und Dokumente aus verschiedenen Zeiten stammen können, was zu Bewertungen führt, die die aktuelle Relevanz der Dokumente nicht genau widerspiegeln. 2. Wiederverwendung von Bewertungen: Die Praxis, Bewertungen wiederzuverwenden, um schnell zu evaluieren und Kosten zu kontrollieren, kann zu Bewertungen führen, die nicht repräsentativ für die aktuelle Aktualität oder Relevanz des Inhalts sind. 3. Verständnis technischer Anfragen: Evaluatoren verstehen möglicherweise technische Anfragen nicht, was zu Schwierigkeiten bei der Bewertung der Relevanz von spezialisierten oder Nischenthemen führt. 4. Bewertung der Popularität: Es besteht eine inhärente Schwierigkeit für Evaluatoren, die Popularität unter konkurrierenden Anfrageinterpretationen oder rivalisierenden Produkten zu beurteilen, was die Genauigkeit ihrer Bewertungen beeinflussen könnte. 5. Vielfalt der Evaluatoren: Das Fehlen von Vielfalt unter Evaluatoren an einigen Standorten und die Tatsache, dass sie alle Erwachsene sind, spiegelt nicht die Vielfalt der Nutzerbasis von Google wider, zu der auch Minderjährige gehören. 6. Benutzergenerierte Inhalte: Evaluatoren neigen dazu, streng mit benutzergenerierten Inhalten umzugehen, was dazu führen kann, dass ihr Wert und ihre Relevanz unterschätzt werden, obwohl sie nützlich und relevant sind. 7. Freshness Node Training: Sie signalisieren ein Problem bei der Abstimmung von Aktualitätsmodellen aufgrund fehlender angemessener Trainingslabels. Menschliche Evaluatoren achten oft nicht genug auf den Aspekt der Aktualität der Relevanz oder haben keinen zeitlichen Kontext für die Anfrage. Dies führt dazu, dass aktuelle Ergebnisse für Anfragen, die Neuheit suchen, unterbewertet werden. Das bestehende Tangram-Dienstprogramm, basierend auf IS und zur Schulung von Relevanz- und anderen Bewertungskurven verwendet, litt unter dem gleichen Problem. Aufgrund der Begrenzung menschlicher Labels wurden die Bewertungskurven des Freshness Node bei seiner ersten Veröffentlichung manuell angepasst.
Ich glaube aufrichtig, dass menschliche Evaluatoren für die effektive Funktionsweise von „Parasite SEO“ verantwortlich waren, etwas, das endlich die Aufmerksamkeit von Danny Sullivan auf sich gezogen hat und in diesem Tweet geteilt wird:

Wenn wir uns die Änderungen in den neuesten Qualitätsrichtlinien ansehen, können wir sehen, wie sie endlich die Definition der Metriken für die Erfüllung von Bedürfnissen angepasst und ein neues Beispiel für Evaluatoren hinzugefügt haben, das sie berücksichtigen sollen, selbst wenn ein Ergebnis maßgeblich ist, sollte es nicht als besonders hoch bewertet werden, wenn es nicht die Informationen enthält, nach denen der Benutzer sucht.

Die neue Einführung von Google Notizen, glaube ich, weist auch auf diesen Grund hin. Google ist nicht in der Lage, mit 100%iger Sicherheit zu wissen, was qualitativ hochwertigen Inhalt ausmacht.

Ich glaube, dass diese Ereignisse, über die ich spreche, die fast gleichzeitig aufgetreten sind, kein Zufall sind und dass wir bald Veränderungen sehen werden.
2. PQ (Seitenqualität)
Hier schließe ich daraus, dass sie über Seitenqualität sprechen, also ist dies meine Interpretation. Wenn ja, gibt es in den Testdokumenten nichts außer der Erwähnung als verwendetes Maß. Das einzige offizielle Dokument, das ich habe und das PQ erwähnt, stammt aus den Richtlinien für Suchqualitätsbewerter, die sich im Laufe der Zeit ändern. Es wäre also eine weitere Aufgabe für menschliche Bewerter.

Diese Informationen werden auch an die Algorithmen gesendet, um Modelle zu erstellen. Hier können wir einen Vorschlag dazu sehen, der bei "Project Veritas" durchgesickert ist:

Ein interessanter Punkt hier, laut den Dokumenten bewerten Qualitätsbewerter nur Seiten auf Mobilgeräten.

3. Nebeneinander
Dies bezieht sich wahrscheinlich auf Tests, bei denen zwei Suchergebnissätze nebeneinander platziert werden, damit Evaluatoren ihre relative Qualität vergleichen können. Dies hilft dabei festzustellen, welcher Ergebnissatz relevanter oder nützlicher für eine bestimmte Suchanfrage ist. Wenn ja, erinnere ich mich daran, dass Google sein eigenes Download-Tool dafür hatte, das sxse.

Das Tool ermöglicht es den Benutzern, für die Suchergebnisse abzustimmen, die sie bevorzugen, und liefert somit direktes Feedback zur Wirksamkeit verschiedener Anpassungen oder Versionen der Suchsysteme.
4. Live-Experimente
Die offiziellen Informationen, die in So funktioniert die Suche veröffentlicht wurden, besagen, dass Google Experimente mit echtem Traffic durchführt, um zu testen, wie Menschen mit einem neuen Feature interagieren, bevor es für alle ausgerollt wird. Sie aktivieren das Feature für einen kleinen Prozentsatz der Benutzer und vergleichen deren Verhalten mit einer Kontrollgruppe, die das Feature nicht hat. Detaillierte Metriken zur Benutzerinteraktion mit den Suchergebnissen umfassen:
- Klicks auf Ergebnisse
- Anzahl der durchgeführten Suchanfragen
- Abbruch der Anfrage
- Wie lange es gedauert hat, bis Personen auf ein Ergebnis geklickt haben
Diese Daten helfen zu messen, ob die Interaktion mit der neuen Funktion positiv ist und stellen sicher, dass die Änderungen die Relevanz und Nützlichkeit der Suchergebnisse erhöhen.
Aber die Prozessdokumente heben nur zwei Metriken hervor:

- Position gewichtete lange Klicks: Dieses Maß würde die Dauer von Klicks und deren Position auf der Ergebnisseite berücksichtigen und die Zufriedenheit der Benutzer mit den gefundenen Ergebnissen widerspiegeln. 2. Aufmerksamkeit: Dies könnte bedeuten, die auf der Seite verbrachte Zeit zu messen und eine Vorstellung davon zu geben, wie lange Benutzer mit den Ergebnissen und deren Inhalt interagieren.
Darüber hinaus wird in dem Transkript der Aussage von Pandu Nayak erklärt, dass sie zahlreiche Algorithmustests unter Verwendung von Interleaving anstelle von traditionellen A/B-Tests durchführen. Dies ermöglicht es ihnen, schnelle und zuverlässige Experimente durchzuführen und somit Schwankungen in den Rankings zu interpretieren.
5. Frische
Frische ist ein entscheidender Aspekt sowohl von Ergebnissen als auch von Suchfunktionen. Es ist wichtig, relevante Informationen sofort anzuzeigen und aufzuhören, Inhalte zu zeigen, wenn sie veraltet sind.
Für die Ranking-Algorithmen, um aktuelle Dokumente in den SERP anzuzeigen, müssen die Indexierungs- und Bereitstellungssysteme in der Lage sein, frische Dokumente mit sehr geringer Latenz zu entdecken, zu indexieren und bereitzustellen. Obwohl idealerweise der gesamte Index so aktuell wie möglich sein sollte, gibt es technische und kostentechnische Einschränkungen, die verhindern, dass jedes Dokument mit geringer Latenz indexiert wird. Das Indexierungssystem priorisiert Dokumente auf separaten Pfaden und bietet unterschiedliche Kompromisse zwischen Latenz, Kosten und Qualität.
Es besteht die Gefahr, dass sehr aktuelle Inhalte aufgrund ihrer Relevanz unterschätzt werden und dass Inhalte mit vielen Beweisen für Relevanz aufgrund einer Änderung der Bedeutung der Abfrage weniger relevant werden.

Die Rolle des Freshness-Knotens besteht darin, Korrekturen zu veralteten Bewertungen hinzuzufügen. Bei Anfragen nach frischem Inhalt fördert er frischen Inhalt und degradiert veralteten Inhalt.
Vor nicht allzu langer Zeit wurde bekannt, dass Google Caffeine nicht mehr existiert (auch bekannt als das auf Perkolator basierende Indexierungssystem). Obwohl intern immer noch der alte Name verwendet wird, handelt es sich bei dem, was jetzt existiert, tatsächlich um ein völlig neues System. Das neue „Koffein“ ist tatsächlich eine Reihe von Mikroservices, die miteinander kommunizieren. Dies bedeutet, dass verschiedene Teile des Indexierungssystems als unabhängige, aber miteinander verbundene Dienste fungieren, von denen jeder eine spezifische Funktion ausführt. Diese Struktur kann eine größere Flexibilität, Skalierbarkeit und die Möglichkeit zur Aktualisierung und Verbesserung bieten.
Wie ich es interpretiere, würden Teile dieser Microservices Tangram und Glue sein, speziell der Freshness Node und Instant Glue. Ich sage das, weil ich in einem anderen durchgesickerten Dokument von «Project Veritas» gefunden habe, dass es einen Vorschlag aus dem Jahr 2016 gab, einen «Instant Navboost» als Frische-Signal zu erstellen oder zu integrieren, sowie Chrome-Besuche.

Bisher haben sie bereits «Freshdocs-instant» (extrahiert aus einer Liste von Pubsub namens freshdocs-instant-docs pubsub, wo sie die Nachrichten veröffentlichten, die von diesen Medien innerhalb von 1 Minute nach ihrer Veröffentlichung veröffentlicht wurden) und Suchspitzen und Inhaltskorrelationen integriert:

Innerhalb der Frische-Metriken haben wir mehrere, die dank der Analyse von korrelierten N-Grammen und korrelierten markanten Begriffen erkannt werden.
- Korrelierte NGramme: Dies sind Gruppen von Wörtern, die in einem statistisch signifikanten Muster zusammen auftreten. Die Korrelation kann während eines Ereignisses oder eines Trendthemas plötzlich ansteigen und auf einen Anstieg hinweisen. 2. Korrelierte markante Begriffe: Dies sind herausragende Begriffe, die eng mit einem Thema oder Ereignis verbunden sind und deren Häufigkeit in Dokumenten über einen kurzen Zeitraum zunimmt, was auf ein Interesse oder eine damit verbundene Aktivität hinweist.
Sobald Spitzen erkannt werden, könnten die folgenden Frische-Metriken verwendet werden:
- Unigramme (RTW): Für jedes Dokument werden der Titel, Anker-Texte und die ersten 400 Zeichen des Haupttexts verwendet. Diese werden in für die Trenderkennung relevante Unigramme aufgeteilt und dem Hivemind-Index hinzugefügt. Der Haupttext enthält im Allgemeinen den Hauptinhalt des Artikels, ohne wiederholende oder häufige Elemente (Boilerplate).
- Halbe Stunden seit Epoch (TEHH): Dies ist ein Zeitmaß, das als Anzahl von halben Stunden seit Beginn der Unix-Zeit ausgedrückt wird. Es hilft dabei, festzustellen, wann etwas mit halbstündiger Genauigkeit passiert ist.
- Wissensgraph-Entitäten (RTKG): Verweise auf Objekte im Wissensgraphen von Google, der eine Datenbank realer Entitäten (Menschen, Orte, Dinge) und ihrer Verbindungen ist. Er trägt dazu bei, die Suche durch semantisches Verständnis und Kontext zu bereichern.
- S2-Zellen (S2): Verweise auf Objekte im Wissensgraphen von Google, der eine Datenbank realer Entitäten (Menschen, Orte, Dinge) und ihrer Verbindungen ist. Er trägt dazu bei, die Suche durch semantisches Verständnis und Kontext zu bereichern.
- Freshbox-Artikel-Score (RTF): Dies sind geometrische Unterteilungen der Erdoberfläche, die für die geografische Indizierung in Karten verwendet werden. Sie erleichtern die Verknüpfung von Webinhalten mit präzisen geografischen Standorten.
- Dokument-NSR (RTN): Dies könnte sich auf die Nachrichtenrelevanz des Dokuments beziehen und scheint eine Metrik zu sein, die bestimmt, wie relevant und zuverlässig ein Dokument in Bezug auf aktuelle Ereignisse oder Trends ist. Diese Metrik kann auch dazu beitragen, minderwertige oder Spam-Inhalte herauszufiltern und sicherzustellen, dass die indizierten und hervorgehobenen Dokumente von hoher Qualität und bedeutend für Echtzeitsuchen sind.
- Geografische Dimensionen: Merkmale, die den geografischen Standort eines Ereignisses oder Themas im Dokument definieren. Diese können Koordinaten, Ortsnamen oder Identifikatoren wie S2-Zellen umfassen.
Wenn Sie in den Medien arbeiten, ist diese Information entscheidend, und ich nehme sie immer in meine Schulungen für digitale Redakteure auf.
Die Bedeutung von Klicks
In diesem Abschnitt werden wir uns auf die interne Präsentation von Google, die in einer E-Mail geteilt wurde und den Titel «Unified Click Prediction» trägt, die Präsentation «Google is Magical», die Präsentation Search All Hands, eine interne E-Mail von Danny Sullivan und die Dokumente aus dem «Project Veritas»-Leak konzentrieren.
Im Laufe dieses Prozesses sehen wir die grundlegende Bedeutung von Klicks für das Verständnis des Nutzerverhaltens/-bedarfs. Mit anderen Worten: Google benötigt unsere Daten. Interessanterweise durfte Google nicht über Klicks sprechen.

Bevor wir beginnen, ist es wichtig zu beachten, dass die Hauptdokumente, die sich mit Klicks befassen, vor 2016 entstanden sind, und Google hat seitdem erhebliche Veränderungen durchgemacht. Trotz dieser Entwicklung bleibt die Grundlage ihres Ansatzes die Analyse des Nutzerverhaltens und die Betrachtung als Qualitätsignal. Erinnern Sie sich an das Patent, in dem sie das CAS-Modell erklären?

Jede Suche und jeder Klick, den Benutzer bereitstellen, trägt zum Lernen und kontinuierlichen Verbessern von Google bei. Diese Rückkopplungsschleife ermöglicht es Google, sich anzupassen und "zu lernen" über Suchpräferenzen und Verhaltensweisen, wodurch die Illusion aufrechterhalten wird, dass es die Bedürfnisse der Benutzer versteht.

Täglich analysiert Google über eine Milliarde neue Verhaltensweisen innerhalb eines Systems, das darauf ausgelegt ist, kontinuierlich Anpassungen vorzunehmen und zukünftige Vorhersagen auf der Grundlage vergangener Daten zu übertreffen. Zumindest bis 2016 überstieg dies die Kapazität der KI-Systeme zu dieser Zeit, was die manuelle Arbeit erforderte, die wir zuvor gesehen haben, sowie Anpassungen, die von RankLab vorgenommen wurden.
RankLab, ich verstehe, ist ein Labor, das verschiedene Gewichte in Signalen und Rankingfaktoren testet, sowie deren anschließende Auswirkungen. Sie könnten auch für das interne Tool «Twiddler» (etwas, das ich auch vor Jahren von «Project Veritas» gelesen habe) verantwortlich sein, mit dem Zweck, die IR-Scores bestimmter Ergebnisse manuell zu modifizieren, oder mit anderen Worten, all das Folgende zu tun:

Nach diesem kurzen Zwischenspiel fahre ich fort.
Während menschliche Bewertungen einen grundlegenden Überblick bieten, liefern Klicks ein viel detaillierteres Panorama des Suchverhaltens.


Dies offenbart komplexe Muster und ermöglicht das Erlernen von Effekten zweiter und dritter Ordnung.
- Second-order effects spiegeln sich in aufkommenden Mustern wider: Wenn die Mehrheit detaillierte Artikel schnellen Listen vorzieht und auswählt, erkennt dies Google. Im Laufe der Zeit passt es seine Algorithmen an, um diese detaillierteren Artikel in verwandten Suchen zu priorisieren.
- Third-order effects sind umfassendere, langfristige Veränderungen: Wenn Klicktrends umfassende Anleitungen bevorzugen, passen sich Inhalteersteller an. Sie beginnen, mehr detaillierte Artikel und weniger Listen zu produzieren, wodurch sich die Art des im Web verfügbaren Inhalts verändert.
In den analysierten Dokumenten wird ein spezieller Fall präsentiert, bei dem die Relevanz der Suchergebnisse durch Klickanalyse verbessert wurde. Google identifizierte eine Diskrepanz in der Benutzerpräferenz, basierend auf Klicks, für einige Dokumente, die sich als relevant erwiesen, obwohl sie von einer Gruppe von 15.000 als irrelevant betrachteten Dokumenten umgeben waren. Diese Entdeckung unterstreicht die Bedeutung von Benutzerklicks als wertvolles Werkzeug zur Unterscheidung versteckter Relevanz in großen Datenmengen.

Google „trainiert mit der Vergangenheit, um die Zukunft vorherzusagen“, um Overfitting zu vermeiden. Durch kontinuierliche Bewertungen und Datenaktualisierungen bleiben die Modelle aktuell und relevant. Ein wichtiger Aspekt dieser Strategie ist die Lokalisierung der Personalisierung, um sicherzustellen, dass die Ergebnisse für verschiedene Benutzer in verschiedenen Regionen relevant sind.
In Bezug auf Personalisierung behauptet Google in einem neueren Dokument, dass sie begrenzt ist und die Rankings selten verändert. Sie erwähnen auch, dass sie nie in den „Top Stories“ vorkommt. Sie wird verwendet, um besser zu verstehen, wonach gesucht wird, beispielsweise unter Verwendung des Kontexts früherer Suchanfragen und auch zur Erstellung von Vorhersagevorschlägen mit der Autovervollständigung. Sie erwähnen, dass sie möglicherweise einen Videoanbieter leicht erhöhen, den der Benutzer häufig verwendet, aber jeder würde im Wesentlichen die gleichen Ergebnisse sehen. Ihrer Meinung nach ist die Suchanfrage wichtiger als die Benutzerdaten.
Es ist wichtig zu bedenken, dass dieser auf Klicks ausgerichtete Ansatz Herausforderungen birgt, insbesondere bei neuen oder seltenen Inhalten. Die Bewertung der Qualität von Suchergebnissen ist ein komplexer Prozess, der über das reine Zählen von Klicks hinausgeht. Obwohl dieser Artikel, den ich geschrieben habe, bereits mehrere Jahre alt ist, denke ich, dass er dazu beitragen kann, tiefer in dieses Thema einzutauchen.
Die Architektur von Google
Nach dem vorherigen Abschnitt ist dies das mentale Bild, das ich mir davon gemacht habe, wie wir all diese Elemente in einem Diagramm platzieren könnten. Es ist sehr wahrscheinlich, dass einige Komponenten der Architektur von Google nicht an bestimmten Stellen sind oder nicht in dieser Weise in Beziehung stehen, aber ich glaube, dass es als Annäherung mehr als ausreichend ist.
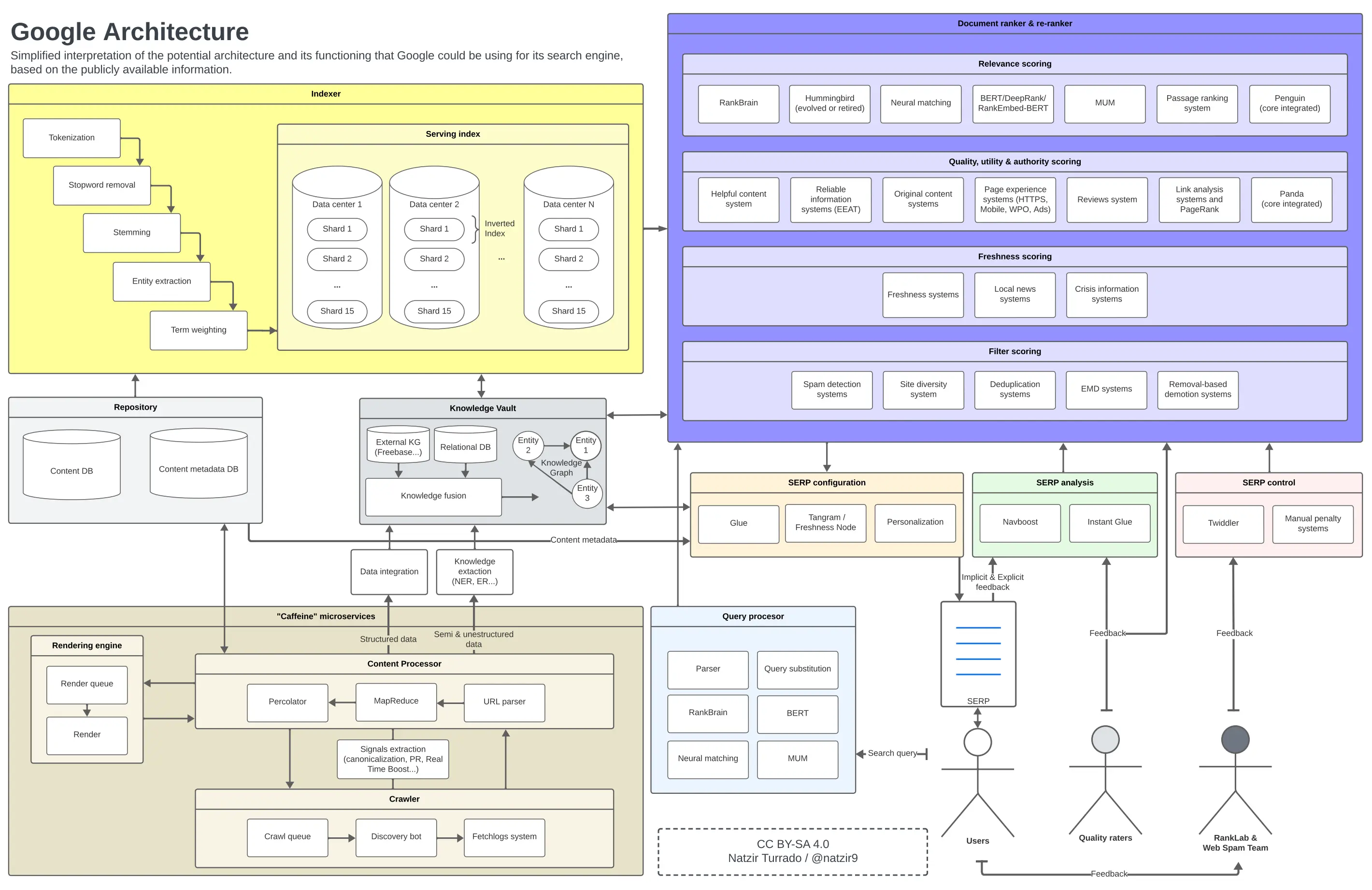
Mögliche Funktionsweise und Architektur von Google. Klicken Sie, um das Bild zu vergrößern.
Google und Chrome: Der Kampf um die Standard-Suchmaschine und den Browser
In diesem letzten Abschnitt konzentrieren wir uns auf die Aussage des Sachverständigen Antonio Rangel, Verhaltensökonom und Professor am Caltech, über die Verwendung von Standardoptionen zur Beeinflussung der Benutzerentscheidungen in der internen Präsentation "Zum strategischen Wert der Standard-Startseite für Google" und in den Aussagen von Jim Kolotouros, VP bei Google, in einer internen E-Mail.
Wie Jim Kolotouros in internen Kommunikationen enthüllt, ist Chrome nicht nur ein Browser, sondern ein Schlüsselelement im Dominanz-Puzzle von Googles Suche.
Unter den von Google gesammelten Daten befinden sich Suchmuster, Klicks auf Suchergebnisse und Interaktionen mit verschiedenen Websites, was entscheidend ist, um die Algorithmen von Google zu verfeinern und die Genauigkeit der Suchergebnisse sowie die Effektivität von zielgerichteter Werbung zu verbessern.
Für Antonio Rangel übertrifft die Marktherrschaft von Chrome seine Beliebtheit. Es dient als Eingangstor zum Google-Ökosystem und beeinflusst, wie Benutzer auf Informationen und Online-Dienste zugreifen. Die Integration von Chrome mit der Google-Suche als Standard-Suchmaschine verschafft Google einen erheblichen Vorteil bei der Kontrolle des Informationsflusses und der digitalen Werbung.

Trotz der Popularität von Google ist Bing keine minderwertige Suchmaschine. Viele Benutzer bevorzugen jedoch Google aufgrund der Bequemlichkeit seiner Standardkonfiguration und der damit verbundenen kognitiven Verzerrungen. Auf mobilen Geräten sind die Auswirkungen von Standard-Suchmaschinen aufgrund des Aufwands, sie zu ändern, stärker; bis zu 12 Klicks sind erforderlich, um die Standard-Suchmaschine zu ändern.

Diese Standardeinstellung beeinflusst auch die Entscheidungen der Verbraucher in Bezug auf die Privatsphäre. Die Standardeinstellungen von Google zur Privatsphäre stellen eine erhebliche Reibung für diejenigen dar, die eine begrenztere Datensammlung bevorzugen. Die Änderung der Standardeinstellung erfordert Kenntnis der verfügbaren Alternativen, das Erlernen der notwendigen Schritte zur Änderung und die Umsetzung, was eine erhebliche Reibung darstellt. Darüber hinaus neigen Verhaltensfehler wie Status quo und Verlustaversion dazu, dass Benutzer dazu tendieren, die Standardeinstellungen von Google beizubehalten. Ich erkläre das hier genauer.
Die Aussage von Antonio Rangel stimmt direkt mit den internen Analyseergebnissen von Google überein. Das Dokument zeigt, dass die Einstellung der Browser-Startseite einen signifikanten Einfluss auf den Marktanteil von Suchmaschinen und das Nutzerverhalten hat. Insbesondere führen eine hohe Anzahl von Nutzern, die Google als ihre Standard-Startseite haben, 50% mehr Suchanfragen auf Google durch als diejenigen, die dies nicht tun.

Dies legt eine starke Korrelation zwischen der Standard-Startseite und der Suchmaschinenpräferenz nahe. Darüber hinaus variiert der Einfluss dieser Einstellung regional und ist in Europa, dem Nahen Osten, Afrika und Lateinamerika ausgeprägter, während er in der asiatisch-pazifischen Region und Nordamerika weniger stark ausgeprägt ist. Die Analyse zeigt auch, dass Google im Vergleich zu Konkurrenten wie Yahoo und MSN weniger anfällig für Änderungen der Startseiteneinstellung ist und dass diese Konkurrenten erhebliche Verluste erleiden könnten, wenn sie diese Einstellung verlieren.

Die Startseiteneinstellung wird von Google als wichtiges strategisches Instrument identifiziert, nicht nur um seinen Marktanteil zu halten, sondern auch als potenzielle Schwachstelle für seine Konkurrenten. Darüber hinaus wird betont, dass die meisten Benutzer keine Suchmaschine aktiv auswählen, sondern sich auf den standardmäßigen Zugriff verlassen, der durch ihre Startseiteneinstellung bereitgestellt wird. In wirtschaftlicher Hinsicht wird ein geschätzter inkrementeller Lebenszeitwert von etwa 3 US-Dollar pro Benutzer für Google angenommen, wenn es als Startseite festgelegt ist.

Fazit
Nachdem wir die Algorithmen und internen Abläufe von Google erkundet haben, haben wir die bedeutende Rolle gesehen, die Benutzerklicks und menschliche Evaluatoren bei der Platzierung von Suchergebnissen spielen.
Klicks als direkte Indikatoren für Benutzerpräferenzen sind für Google unerlässlich, um die Relevanz und Genauigkeit seiner Antworten kontinuierlich anzupassen und zu verbessern. Obwohl sie manchmal das Gegenteil wollen könnten, wenn die Zahlen nicht aufgehen...
Zusätzlich tragen menschliche Evaluatoren eine entscheidende Schicht der Bewertung und des Verständnisses bei, die auch im Zeitalter der künstlichen Intelligenz unverzichtbar bleibt. Persönlich bin ich an diesem Punkt sehr überrascht, da ich wusste, dass Evaluatoren wichtig waren, aber nicht in diesem Ausmaß.
Diese beiden Eingaben, kombiniert mit automatischem Feedback durch Klicks und menschlicher Aufsicht, ermöglichen es Google nicht nur, Suchanfragen besser zu verstehen, sondern sich auch an sich verändernde Trends und Informationsbedürfnisse anzupassen. Mit dem Fortschritt der KI wird es interessant sein zu sehen, wie Google weiterhin diese Elemente ausbalanciert, um die Sucherfahrung in einem sich ständig verändernden Ökosystem mit Fokus auf Datenschutz zu verbessern und zu personalisieren.
Auf der anderen Seite ist Chrome viel mehr als nur ein Browser; es ist die entscheidende Komponente ihrer digitalen Dominanz. Seine Synergie mit der Google-Suche und seine Standardimplementierung in vielen Bereichen beeinflussen die Marktdynamik und die gesamte digitale Umgebung. Wir werden sehen, wie der Kartellprozess endet, aber sie haben seit mehr als 10 Jahren etwa 10.000 Millionen Euro an Bußgeldern für den Missbrauch ihrer marktbeherrschenden Stellung nicht gezahlt.